训练成本不到其 6% 的「联邦大模型」,凭什么在会议场景媲美 GPT-4?

作者丨何思思
编辑丨陈彩娴
今年 8 月,在雷峰网于新加坡举办的 GAIR 大会主论坛上,前微软全球技术院士、美国双院院士黄学东用一句中国古语提出了他对大模型的发展理论预测:
当时,国内大模型研发的主流趋势是一家自研一个基座大模型,正进入如火如荼的「百模大战」中,而黄学东院士的观点则反其道而行之,认为将所有鸡蛋放在一个篮子里太危险,应该将四五家大模型的能力进行整合,每个大模型都有各自的应用场景。
用一个专业词汇来概括,离开微软、加入 Zoom 担任 CTO 后,黄学东在 Zoom 内部推崇的大模型研发路线是「联邦大模型」——将 OpenAI、Anthropic AI、谷歌、Meta 等等科技巨头的大语言模型集合在一起,形成 Zoom 的 AI 底座,由此以更低的成本、实现更好的效果。
近日,黄学东团队经过一系列的研究与实验,验证了 8 月对「联邦大模型」的路线设想,取得重大突破:Zoom 的 AI 技术团队以不到 GPT-4 6% 的成本将多个知名大模型进行整合,训练出来的联邦大模型在会议场景的性能上达到了 GPT-4-32k 的效果。
在算力层面,联邦大模型用小于 10% 的计算资源可以达到 GPT-4在 Zoom 应用场景中 99% 的性能、并大大超越GPT-4的反应速度。
相比国内外追求单一最优的基座大模型厂商,虽然它们在技术研究上也取得不错突破,在单一模态、部分任务上能实现最优,但整体能力仍然偏弱,距离 GPT-4 有很大差距。
究其原因,是因为大部分的厂商在同时兼顾效果与成本上分身乏术,要么没有足够的财力,要么没有足够的能力。而由于对自研文化的极致推崇,原本优势集中在应用场景上的玩家也更倾向于通过自己的力量将模型做大做强,缺少向外学习、取长补短的意识。
在重复造轮子现象严重的当下,Zoom 所提出的「联邦大模型」具有启示意义。
什么是联邦大模型?
大模型时代的力量被分为三层,一层是底层算力,中间层是算法创新,最上层是模型应用。Zoom 虽自建大模型团队,但并不是一个卖算法的厂商。相比算法研发,拥有明确的落地场景(如视频会议)、广大垂直行业用户的 Zoom 更偏向于应用。
与大多数侧重应用的厂商一样,Zoom 对大模型的诉求也主要体现在性价比上——用最低廉的价格实现最强的模型能力,从而为用户提供最优质的服务,提高用户满意度。例如,提高视频会议的沟通效率,增强会议的自动文本总结功能,自动生成会议草稿与会议问答等。为此,Zoom 选择联邦大模型的路线更具优势。
据 AI 科技评论独家对话 Zoom 团队,过去半年,他们基于联邦大模型在落地上取得了飞速进步,主要体现在三方面:
其一,AI落地方法的改进。
与其他 AI 应用改造不同的是,Zoom 采用了联合AI 的方法,其也是 Zoom 创新的基石。据悉,目前 Zoom 已经接入了多个模型,其中包括 Zoom 自研的 LLM、第三方模型 GPT-3.5 和 GPT-4,以及 Anthropic AI 的 Claude 2 等大模型。
想接入的模型并不局限于上述,而是在以开放的心态拥抱各类 LLM,不仅可以整合最新的 LLM,比如 OpenAI 的 GPT-4甚至是未来的GPT-5等,还可以将开源或者闭源 LLM 融入其中,共同为提升客户在 中端到端的体验。
为了验证联邦大模型的效果,Zoom 也在内部进行了多轮测试。结果显示,Zoom 基于模型整合训练的联邦大模型取得的效果已经能媲美许多知名的单一基座模型,包括 OpenAI 的 GPT-3.5 Turbo(99% vs 93%)以及其他几种最先进的 LLM。
其二,坚持低成本落地。
能根据具体的场景选择最适合的且成本最低的 LLM。根据 Z-Scorer 评估初始任务的完成质量评估,会视情况调用更高级别的 LLM 来根据初始 LLM 所取得的成果增强任务的完成。
聚焦到实际的应用场景中,诸如一些比较简单的问题,Zoom 会选择使用中小模型解决,一些比较难的问题则会调用 GPT-4来解决。而这种方法较单一模型来说,能在很大程度上实现较低成本的落地。
相当于 GPT-4是老师,由他带着下面的学生一起工作,就像一个团队需要不同技能人才协同工作才能创造一个比较有战斗力的集体。
在具体的测试中,与 OpenAI 的 GPT-4-32k 作为微软 Copilot 的 Agent 相比,结果显示,Zoom AI Companion 的会议功能在保证更低成本和更快响应时间的同时,还增强了大模型的质量。目前 Zoom 已经实现了以不到6%的成本达到 GPT-4-32k 的性能,效果非常可观。
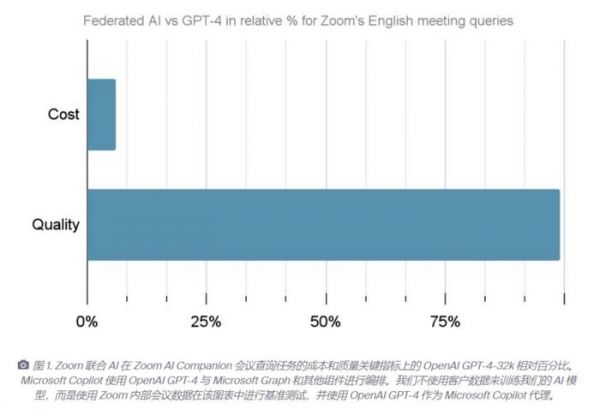
其三,性能越来越强。
在联合 AI 方法的支持下,Zoom 可以实现充分利用众多优秀合作伙伴在大模型方面的进展,在低成本的基础上充分展现了高性能的能力。
AI 科技评论了解到,目前 Zoom 用小于 10% 的计算资源可以达到目前最先进的大模型 GPT-4在 Zoom 应用场景中 99% 的性能、并大大超越GPT-4的反应速度。
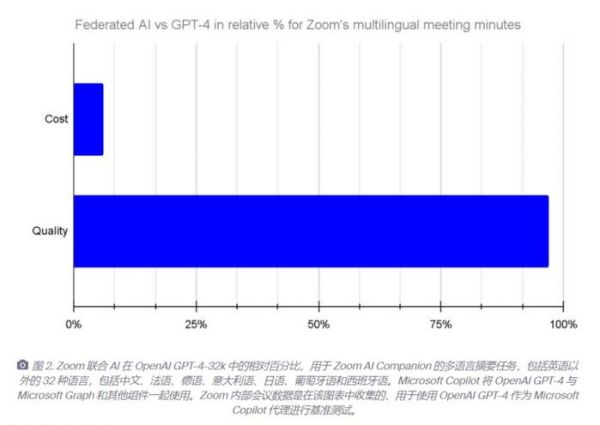
在语言支持方面,早期的 AI 大模型、包括现在的大部分模型主要以英语数据为主进行预训练,Zoom 则增加了翻译模型,扩展了多语言能力,目前已经可以支持除英语以外的 32 种语言。
这些测试均强调了 Zoom 联合 AI 方法的有效性,以及对不同机器学习系统进行整合的优势。
联邦大模型的下一站在哪里?
三个臭皮匠顶个诸葛亮的思想在 Zoom 的成功落地,为整个行业打响了头炮,也证明了联邦大模型为业界指明了一个能让大模型落地的多快好省的方向。
大模型在行业落地时,最为严峻的挑战聚焦在性能、反应速度以及成本三方面,但 Zoom 团队提出的联邦大模型方法较好地解决了这些挑战。据 AI 科技评论观察,目前国内还没有企业能将超过四个、甚至更多的大模型联邦整合起来。
这背后主要还是技术的考验,即根据具体的应用场景应该选哪些模型。在这基础上,如何进行融合,也有很强的技术壁垒。
另外,在性能、反应速度以及成本方面,以 Zoom 现在的表现来看,用比 GPT-4 更少的成本实现了媲美 GPT-4 的性能,是目前行业的顶尖水平,但在具体实践中,联邦大模型也并非坦途。
黄学东曾预测道,以大模型为中心,多模态联合发展的技术趋势在未来两年势必会成为现实。但在现在看来,联邦大模型还是一个比较新的概念,要想通过这项技术做成功的落地应用,不是一朝一夕就能完成的,起码需要对这项技术有较强的认知和充分的理解。
其次,从联邦大模型本身出发,Zoom 强调的融合多个模型,如果是单一模型的话,只需要考虑和某一个模型的适配程度,包括如何灌入数据做训练,如何微调,如何做能力的增强;但如果是多个不同的模型的话,则要复杂的多,不仅需要考虑不同模型之间的勾稽关系,比如这个问题需要 A 模型还是 B 模型来解决,还需要考虑使用哪个模型能更低成本的落地,使用哪个模型的性能更高,体验更好……
这是联邦大模型的核心挑战,也是 Zoom 需要重点克服的问题。Zoom 团队向 AI 科技评论透露道,他们遇到的最大挑战是怎么把众多的臭皮匠大模型整合成诸葛亮。怎么决定在什么样的场景下动态使用什么样的大语言模型来取得最低成本,最快响应速度和最好的质量。平衡这三者的关系是一门艺术,对技术的理解、数据的获取和工程的实践,三者缺一不可。
从目前 Zoom 对外展现的实现效果看,联邦大模型只是在个别场景问题上实现了媲美 GPT-4 ,比如会议问答。但是在质量上还要继续努力,99% 到 100% 的距离是不能马上消除的。未来,联邦大模型想要在全场景中实现赶超还有很长一段路要走。
(雷峰网雷峰网雷峰网)
发布于:广东
相关推荐
训练成本不到其 6% 的「联邦大模型」,凭什么在会议场景媲美 GPT-4?
如果我在OpenAI训练GPT-4
成本大砍90%,GPT-4标注能力直逼人类了
Meta的大模型开源后,国产大模型在卷什么?
Meta计划曝光:下一个大模型以GPT-4为标准,2024年开始训练
马斯克、图灵奖得主等叫停GPT-4后续大模型,千人响应
AI大模型闪聊会:中美顶流AI大模型的碰撞与契机
Meta新AI大模型开发计划首次披露!其功能或赶上OpenAI最先进模型
首次:微软用GPT-4做大模型指令微调,新任务零样本性能再提升
GPT-4就是冲着赚钱来的!
网址: 训练成本不到其 6% 的「联邦大模型」,凭什么在会议场景媲美 GPT-4? http://www.xishuta.com/newsview100906.html
推荐科技快讯






- 1问界商标转让释放信号:赛力斯 95159
- 2人类唯一的出路:变成人工智能 20754
- 3报告:抖音海外版下载量突破1 20622
- 4移动办公如何高效?谷歌研究了 19927
- 5人类唯一的出路: 变成人工智 19897
- 62023年起,银行存取款迎来 10296
- 7网传比亚迪一员工泄露华为机密 8436
- 8五一来了,大数据杀熟又想来, 8225
- 9滴滴出行被投诉价格操纵,网约 7846
- 10顶风作案?金山WPS被指套娃 7202



