OpenAI宣布RLHF即将终结,超级AI真的要来了?
上周,OpenAI在其官网上发布了一个全新的研究成果:一个利用较弱的模型来引导对齐更强的模型的技术,称为由弱到强的泛化。
OpenAI认为,未来十年来将诞生超过人类的超级AI系统。但是,这会出现一个问题,即基于人类反馈的强化学习技术将终结。因为彼时,人类的水平不如AI系统,所以可能无法再对模型输出的内容评估好坏。为此,OpenAI提出这种超级对齐技术,希望可以用较弱的模型来对齐较强的模型。这样可以在出现比人类更强的AI系统之后,继续让AI模型遵循人类的意志、偏好和价值观。
RLHF技术及其问题
RLHF全称是Reinforcement Learning from Human Feedback,是当前大语言模型在微调之后必不可少的一个步骤。简单来说,就是让模型输出结果,人类提供结果反馈,然后模型学习理解哪些输出是更好的,这里所说的更好包括道德、价值观以及回复质量等。
在此前Microsoft Build 2023上,来自OpenAI的研究员分享了ChatGPT是如何被训练出来的,那次汇报他回答了为什么大模型在做了有监督微调之后还要做RLHF,这不单单是一个价值对齐的训练,而且是因为它会让模型的回复质量变得更高。至于原因,其实并不是很明确(详情参考:来自Microsoft Build 2023:大语言模型是如何被训练出来的以及语言模型如何变成ChatGPT——State of GPT详解:https://www.datalearner.com/blog/1051685329804657)。
总的来说,RLHF是当前大语言模型质量提升的一个必备步骤。但是,大家可以看到这其中的核心一个步骤是让“人类”来判断好坏。
RLHF面临超人类AI系统可能是不行的
但是,如果有一天,AI系统的能力超过人类了,这个方法显然是不够的。而OpenAI认为:
We believe superintelligence could arrive within the next 10 years.
也就是说,OpenAI认为10年内超越人类的人工智能系统将会出现。所以,他们考虑在这种情况下如何用较弱的AI模型来监督和管理更强的模型。
传统的机器学习(也就是现在),人类比模型强,所以才能使用RLHF监督和引导模型变得更强更好。但未来面临的问题是人类要监督控制比人类更强的AI系统。然而,超人类模型将能够展现人类难以完全理解的复杂和创造性行为。例如,如果一个超人类助手模型生成了一百万行极其复杂的代码,人类将无法为关键的校准相关任务提供可靠的监督,包括:代码是否遵循用户的意图、助手模型是否诚实地回答有关代码的问题、执行代码是否安全或危险等等。
因此,如果我们用人类监督对超人类模型进行微调(即RLHF),其实本质上都是做人类认知范围内的引导。对于超过这部分的风险,需要模型自己推导。那么,超人类模型是否可以推广到人类无法可靠监督的复杂行为上,目前还不得而知。
为什么要让弱AI监督引导强AI
如前所述,此前的强化学习是人类比模型强的情况下推出的,如下图所示,是一个示意图:
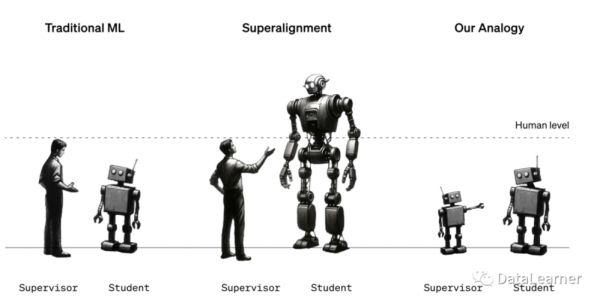
在未来,我们面临的是人类需要监督和控制比自己更强大的AI系统。AI系统产生的行为、错误和问题也会超出人类认知。所以,超人类AI系统的管理上必须具备一种能力,可以将人类给出的监督推广到更复杂的行为上。例如,人类可能只能审核1000行代码是否遵从了指令或者安全。但是,对于一个几百万行的代码系统,可能需要AI根据前面1000行代码的人类评估过程来推广,去自行评估这个几百万行代码的系统是否准确遵从了人类的意图且符合安全要求。
显然,如果10年内出现了超人类AI系统,这个问题迫在眉睫。而OpenAI也据此做了当前的这个由弱到强的超级对齐工作。即如果较弱的人类监督较强的人工智能系统是一个必须解决的目标,那么基于较弱的AI系统监督引导较强的模型则是同一种问题。所以解决了后者不仅可以解决前者的问题,未来也可以降低人类的工作量。
而这次提出的超级对齐就是这个工作的探索方向。
超级对齐
本次OpenAI做的超级对齐系统目标非常简单。首先,说明一下当前AI系统如何更好地达到这个目标。
一开始会训练一个基座模型。这个模型很强,但是它可能并不知道如何回复人类,或者不知道哪些回复的结果更好。所以,我们有了监督微调和RLHF。前者是为了让模型识别人类指令,后者可以让模型知道什么样的回复更好。只有完成了后面两个阶段的微调,模型才可以取得最好的性能。
所以,OpenAI认为,超级对齐有三个基准:第一个是较弱的模型(比如未来的人类、较弱的AI系统),它有一个性能表现基准,还有一个强的AI模型的性能上限基准。超级对齐的目标就是通过弱模型微调(如生成好坏的评价),让强模型完成当前类似SFT和RLHF阶段,达到自己的上限。显然,实际上,由弱模型微调的强模型的性能其实可能并没有达到它上限水平,因此它与强模型上限的差距就是未来我们要缩小的目标。
这里面可能有些人会困惑为什么弱模型可以微调强模型。其实这里的微调主要是指当前大模型训练过程中的对齐阶段。即我们训练出来了一个超强的AI系统,没有对齐微调(RLHF)之前它可以生成任意不加限制和不顾好坏的结果。所以我们需要用一些好坏的示例来告诉它(微调)你应该如何判断好坏,进而完成引导和监督的目的。弱模型的微调是指弱模型可以在有限的范围内生成一些好坏评估结果(例如可以生成1000行代码的评估结果),较强的模型需要根据这个好坏结果微调来提升自己的水平,进而最终可以完成对自己生成的100万行代码的好坏进行评估的能力。这样就可以保证较强的AI系统可以在基座模型上提升水平。
如下图所示:
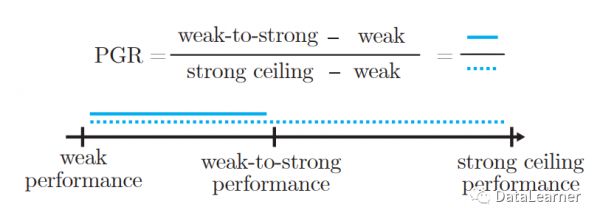
这里的PGR全称是performance gap recovered,就是说强模型的能力恢复(其实就是基座模型的能力通过微调可以发掘出来),它的值如果是1,说明我们完全可以做到由弱模型引导强模型的过程。也就意味着未来我们可以有效控制超人类AI系统。
超级对齐的实验总结
由于这个工作内容很长,我们这里篇幅原因不再细说,总结一下过程和结论。
首先,OpenAI使用的是用GPT-2当作弱模型,GPT-4当作强模型。GPT-2是完全训练好的能力上限的模型。GPT-4用的是基座模型(我们现在用的ChatGPT的GPT-4模型是做过RLHF之后的,所以感觉很强)。
然后,OpenAI选择了非常多的任务,用GPT-2去打标签,再用这个标注结果去微调对齐GPT-4的模型。由于OpenAI本身已经依靠RLHF做出了性能很强的当前已经在使用的GPT-4模型,所以可以对比GPT-2标注结果微调的GPT-4和当前做过RLHF的GPT-4的性能差距。这样测试由弱到强的监督可以恢复强模型的多少能力(这里可以看到,GPT-4比人类弱,所以我们RLHF可以完全激发GPT-4的性能。因此,这里的弱模型基准、GPT-4上限基准和由弱到强的微调基准我们都能算出来)。
最终,不同任务的测试结果如下:
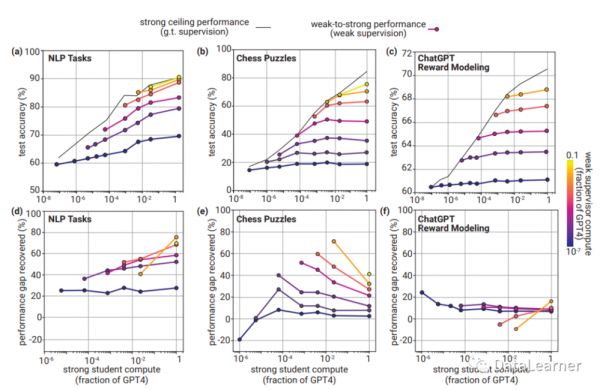
这里的上面一行的数据展示的是真正的GPT-4成绩和由弱到强微调的结果对比。下图是PGR的分数。大致结论就是由弱到强的监督在部分任务上获得不错的结果,比如NLP任务上,可以恢复到最强性能上限的70%还多,最少也有20%的提升(相比较强模型的基座)。但是,在奖励模型的任务上表现很差,不管在什么的测试环境,都无法获得强模型的有效提升。奖励模型是指模型可以识别出人类偏好什么样的回复。
下图是总结:
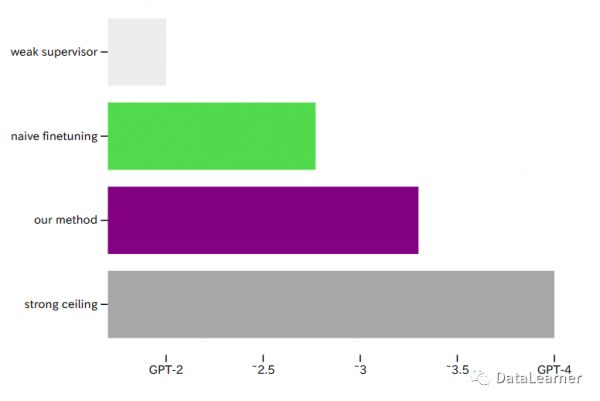
第一行是GPT-2的基准,最后一行是GPT-4的上限(基于RLHF),绿色是直接使用GPT-2生成的数据微调基座GPT-4之后GPT-4的性能,紫色是OpenAI改进了由弱到强的微调方法后GPT-4恢复的性能。
总体的实验结论如下:
强大的预训练模型天然能够超越它们的弱监督者。如果我们使用弱模型生成的标签对强模型进行微调,强模型的表现会超出弱监督者。例如,在自然语言处理(NLP)任务上,如果我们用GPT-2级别模型的标签对GPT-4进行微调,可以让强模型恢复一半的性能水平。
仅依靠弱监督模型数据的微调是不够的。尽管有积极实验结果,但使用弱监督微调的强模型与使用真实监督微调的强模型之间仍然存在显著差距。弱到强泛化在ChatGPT奖励建模方面尤其不佳。综合来看,这个实验结果提供了实证证据,表明当前的RLHF可能无法很好地扩展到超人类模型,除非进行额外的工作。
改进弱到强的泛化是可行的。OpenAI发现,通过鼓励强模型使用辅助损失函数来进行自信预测、使用中间模型进行监督引导和通过无监督微调改进模型表示,可以提高性能。例如,当使用辅助信心损失函数对NLP任务中的GPT-4进行GPT-2级别模型的监督时,我们通常能够恢复弱模型和强模型之间近80%的性能差距。也就是说,至少看到有方法可以实现这种泛化。
总结
这个论文最重要的不是OpenAI提出的方法和结论,而是2个信息:一个是OpenAI真的相信未来10年会出现超过人类的AI系统;另一个是OpenAI正在积极准备应对这种情况。而由弱到强只是这方面的一个探索。同时,OpenAI也宣布投资1000万美元,在全球招募团队做这方面的研究,合格的团队可以获得10万-200万美元的资助,进行超级对齐的研究。
由弱到强的超级对齐论文:https://cdn.openai.com/papers/weak-to-strong-generalization.pdfOpenAI官方的介绍:https://openai.com/research/weak-to-strong-generalization
本文原文来自DataLearnerAI:https://www.datalearner.com/blog/1051702655263827
本文来自微信公众号:DataLearner(ID:data_learner),作者:DataLearner
相关推荐
OpenAI宫斗中被忽略的一部分:AI对齐
OpenAI真的可以让AI“价值对齐”吗?
AI对齐AI,OpenAI让GPT-2监督GPT-4
OpenAI CEO宣布转向,“大模型时代”即将结束?
担忧AI向人类扔核弹,OpenAI是认真的
有效加速还是超级对齐?
超级对齐vs有效加速:OpenAI高层大混战
英伟达、甲骨文投资的AI独角兽,想抢跑OpenAI?
AI大模型,如何保持人类价值观?
Sam和Ilya的深层矛盾:有效加速主义 vs. 超级“爱”对齐
网址: OpenAI宣布RLHF即将终结,超级AI真的要来了? http://www.xishuta.com/newsview102043.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 94831
- 2人类唯一的出路:变成人工智能 18279
- 3报告:抖音海外版下载量突破1 17828
- 4移动办公如何高效?谷歌研究了 17547
- 5人类唯一的出路: 变成人工智 17382
- 62023年起,银行存取款迎来 10009
- 7网传比亚迪一员工泄露华为机密 8000
- 8顶风作案?金山WPS被指套娃 6446
- 9大数据杀熟往返套票比单程购买 6423
- 1012306客服回应崩了 12 6370



