不是大模型用不起,而是小模型更有性价比
到了年末,又到了喜闻乐见的“2024大预测”环节。
今年最热的AI赛道中,机构们自然也得下一些判断,比如说:
2024年大模型的一个趋势,是将变得“越来越小”。
这种趋势其实已经出现一些端倪,在遍地都是千亿级参数量的千模大战下,今年9月,法国AI初创公司发布了Mistral-7B。
身为一个参数量仅为70亿的模型,所有基准性能却都超越了参数量为130亿的Llama 2,公司估值达到22亿美元。
今年12月,谷歌一口气推出了三种规格的Gemini:Ultra、Pro和Nano,其中最小的Nano则准备直接在移动设备上运行,有18亿参数量和32.5亿参数量两个版本。
同时,微软也在12月推出了参数量仅为27亿的模型Phi-2。
它不仅在性能上超越了Mistral-7B,甚至跟参数量700亿版本的Llama 2之间的差距也不大,在一些说明中,其性能已经接近甚至很快会超越自身体量25倍的模型[1]。
在这些参数量越来越小的模型一次次震惊AI界之前,大语言模型有一个心照不宣的法则——参数量越大,性能就越好。
毕竟大模型的参数量可以简单理解成“模仿人类大脑的神经元连接”,更多的连接意味着更多的知识储备空间和产生更复杂的思维链条的可能性,所以更大的参数量=更强的性能其实并没有错。
人类的大脑大概有860亿个神经元,能形成差不多100万亿个神经元链接。目前大模型界的扛把子GPT-4,参数量达到了1.76万亿。
即便不能简单换算,但显然即便是GPT-4也还有很大的进步空间。
可怎么明明没达到人脑水平,就要开始降低参数量了?
一、大模型太贵了
这还是要从OpenAI和它的ChatGPT说起,据数据监测网站Down for Everyone or Just Me的记录,从今年11月底至今,ChatGPT已经宕机5次。
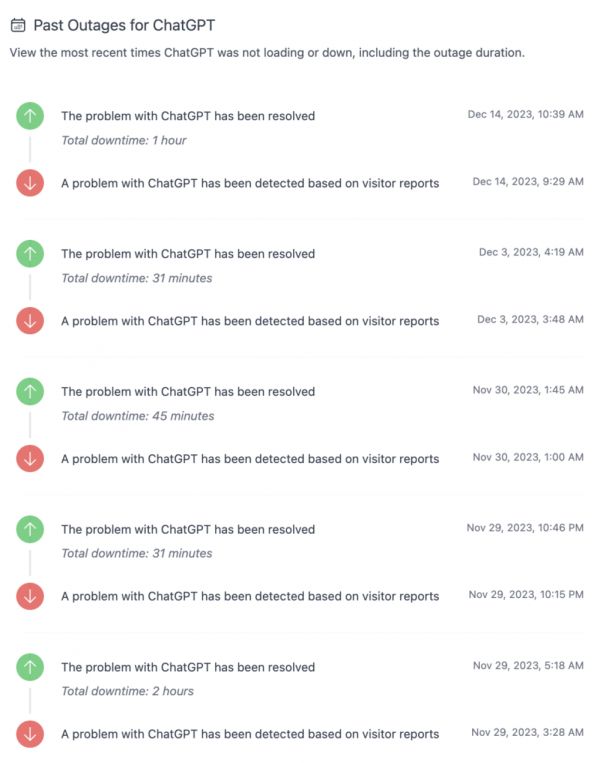
11月7日,Open AI首届开发者大会上,一口气公布了GPT-4 Turbo、图像识别、文字转语音、GPTs等重磅功能,跃跃欲试的用户太多,以至于隔天ChatGPT和API就因为服务器超负荷而故障了两个多小时[2]。
11月15日,Open AI的CEO奥特曼(Sam Altman)直接宣布暂停新的GPT Plus注册,直到12月中旬才逐步重新开放。
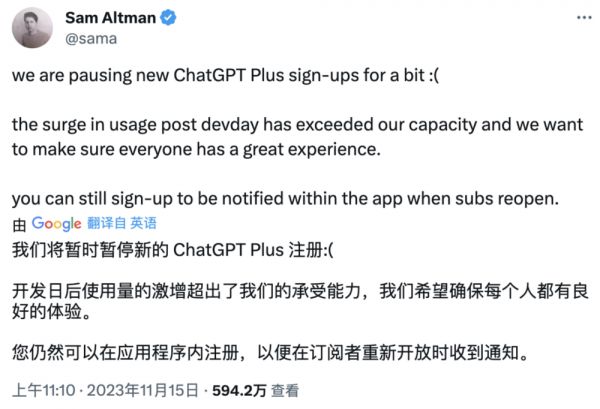
来源:X
这实际上反映的是超大参数量带来的第一个问题:服务器负载。
大模型加上大访问量,对算力的需求是个无底洞,据安信证券测算,目前ChatGPT每天所需的算力约50EFLOPs,所需服务器约1万台[3]。
若ChatGPT的用户量继续保持上涨,假设到24年底用户数量为5亿,则需要23万台服务器,但2022年全球AI服务器的出货量仅为13万台。

服务器需求分为两方面,一者是包括买GPU在内的动辄七八位数的训练成本,比如据奥特曼透露,GPT-4的开发成本超过1亿美元。
据研究机构Epoch AI统计,训练尖端模型所需的算力每6到10个月就会翻一番[7]。
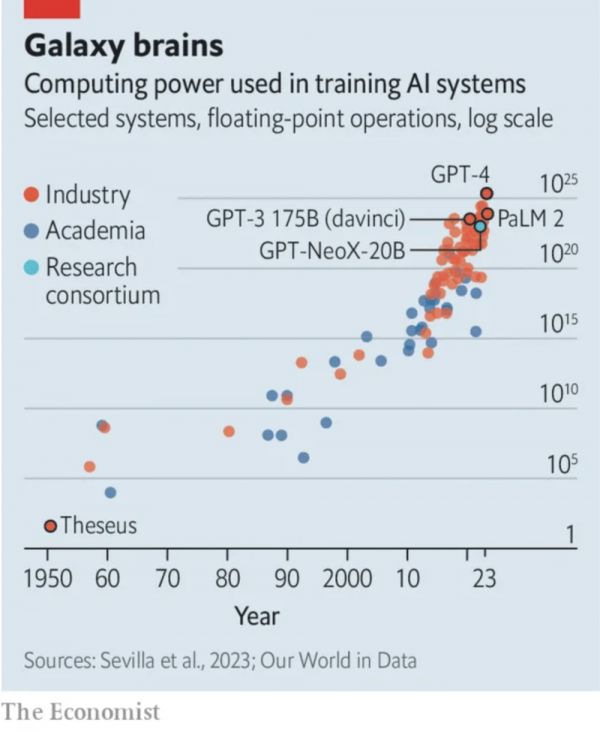
经济学人杂志在这个趋势上进行了推算,如果“10个月翻一番”的理论站得住脚,那到2026年训练一个顶尖模型的成本要超过10亿美元。
在现阶段虽然还有诸多公司愿意为了这个“遥遥领先”的地位去烧钱搏一把,但随着竞争格局逐渐清晰,往死里堆参数的公司显然会越来越少。
这些还都只是一次性开支,咬咬牙也就忍过去了。
真正难以承担的,其实是当模型推出给大众后,日常使用过程中所产生的庞大推理费用。
对于一个大模型来说,回答用户“今天气温多少度”和“如何造一枚原子弹”,假设都只推理一次的情况下,其成本其实是一样的,而前者的需求反而更加庞大。
等于说,科技公司提供了一辆超跑级别的性能野兽,但大多数用户的需求就是拿它送外卖。
大摩也算过一笔账,如果把谷歌当前一半的搜索量交给ChatGPT去处理,那每年要凭空多花60亿美元。
这种成本上的巨大负担,成为了科技公司们另寻它路的首要原因,就像阿尔特曼在今年4月份他在MIT的一次演讲中说[9]:
“我们已经到了大模型时代的尽头,是时候想点其他的办法来提升模型性能了。”
比如说,小模型。
二、不是大模型用不起,而是小模型更有性价比
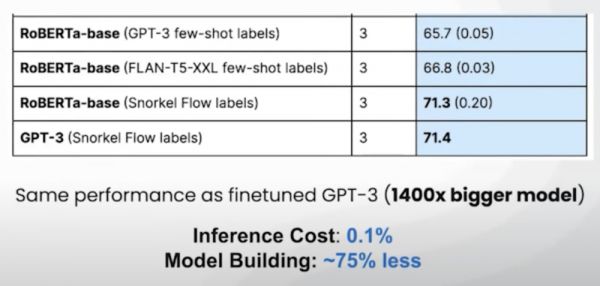
前身是斯坦福AI实验室的Snorkel AI做了一个试验,分别用GPT-3微调和自己搭建小模型的方式去训练一个法律领域的垂直模型。
GPT-3的微调和搭建成本是7418美元,1万次推理花费173美元,而自己搭建小模型的成本仅有1915美元,1万次推理也只要花费0.26美元[8]。
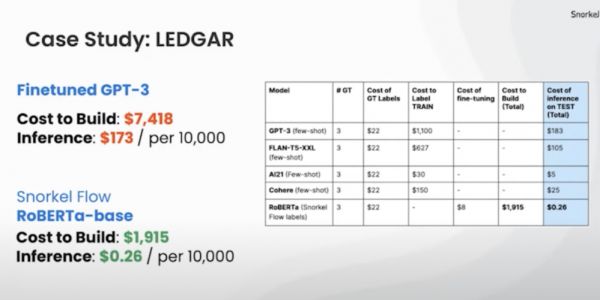
而且GPT-3微调出来的垂直模型正确率为71.4%,仅仅比小模型的71.3%好了一点点。看在GPT-3模型参数量是小模型1400倍的份上,表现好也是正常的。
但是抛开表现看一下成本:小模型的建造成本是GPT-3微调的1/4,推理成本是GPT-3微调的1/1000。
在这种级别的成本差异面前,0.1%的差距似乎显得没那么难接受了。
更为关键的是,现在已经有诸多论文详述了“如何在更少参数量的前提下,实现更强的能力。”
比如说谷歌DeepMind的Chinchilla模型,其凭借700亿的参数量,在表现上超过了参数量为1750亿的GPT-3。这里鸡贼的是,Chinchilla的参数量虽然比GPT-3小,但是它的训练语料库却比GPT-3要大5倍。
简单来说,他们的思路是,让每一个参数都变得更有价值。
DeepMind团队发现,自己训练了400个模型之后发现了一个规律,为了达到最佳的训练效果,当模型参数量翻倍时,训练语料库也应该翻倍[10]。
于是他们遵循这个规律,在1.4万亿个token上训练出来了700亿参数的Chinchilla,语料库的token和参数量比达到了20:1。
而相比之下, Open AI在3000亿个token上训练出来了1750亿参数的GPT-3,语料库的token和参数量比连2:1都没有达到。
DeepMind在更大的语料库上花了更多的时间训练出了Chinchilla,虽然参数量仅有700亿,但这700亿都是精华,由此保障了性能。
还有另一种方式,学术名叫知识蒸馏(Knowledge distillation),咱们俗称“偷师”或者“改进”。
简单来说,这种方式可以高效地将大型复杂模型里的知识,转移到更小更简单的模型中[11]。
知识蒸馏的概念也是辛顿教授一篇论文中所提到的,说白了就是让大模型去吸收浩瀚宇宙中的无穷知识,把学出来的结果传授给小模型。
就像牛顿总结出的那些物理学定律一样,咱们作为学生只要拿来应用就行了。

具体来说,比如你给教师模型一道题:有一个人拿着一套高尔夫球杆,那他最有可能去下面哪个地方?
A.俱乐部
B.礼堂
C.冥想室
D.会议室
E.教堂
教师模型想要得到答案,他需要知道ABCDE这五个地方一般进行什么活动,什么人会去,去了会带些什么做些什么动作,高尔夫球杆在这些地方有没有可能发挥作用,将这些庞大的数据分析后,最终得出结论,只有在俱乐部有可能使用。
而学生模型则不需要关于这五个地方的详细信息,教师模型已经给这五个地方分别打好了标签总结出了规律,从而迅速得出结论,只有A选项符合要求。
回答:答案应该是需要用到高尔夫球杆的地方。上述的选择里面,只有俱乐部里能用到,所以我的答案是 A.俱乐部。
学生模型在看到教师模型的回答后,不仅记住了俱乐部跟高尔夫球杆有关联这个知识点,也知道了遇到相似问题的时候的解题思路。
NLP/AI领域的专家猜测,轰动一时的欧洲之光Mistral 7B就是通过知识蒸馏的方式训练出来的。

来源:Medium
虽然Mistral的训练方式目前还是保密的,但是创始人Arthur Mensch在访谈中提到过,在大模型的基础上通过蒸馏和合成数据来训练出质量更高的小模型,这种方法是可行的。
纵观下来,小模型和大模型实际上并不是一种竞争关系,而是面对算力成本和应用推广两大难题下的一种优化合作。
就如同三体人操控地球的方式是阻止基础物理的发展一样,没有大模型奠基,也就没有站在其肩膀上的小模型。
成本问题解决了,实现方法也有了,推理效率还能够保证,剩下的就是商业化的应用场景了。
三、端侧AI,小模型的天堂
相较于千亿参数大模型不得不部署在云端服务器,占用超级计算机的算力,小模型最大的优势实际上是能部署在端侧。
比如放进随身携带的手机里,不再占用超算算力降低成本不说,其响应速度完全不在一个量级上。
由于手机芯片在空间上的局限性,其算力上限在摩尔定律尚未被打破前基本是可以算得出来的,想要让AI真正走进千家万户,目前来看只能是将模型瘦身装进手机里最为现实。
对于手机端AI的前景,高通的CEO安蒙(Cristiano Amon)认为[4]:“我们将看到以应用为中心的用户界面发生改变,生成式AI将成为人与应用之间的接口。”
而各家手机厂商确实也是这么做的。
小米放出直接搭载在新一代手机系统中的60亿参数模型,可以回答问题、写文章、写代码、做表格。
Vivo的蓝心小V也是定位为融合到手机系统里的全局智能助理,可以听人话、看文字、读文件,能帮用户做计划定日程[5]。
荣耀下一代旗舰机Magic 6直接支持动动嘴皮子,让手机自己去相册找视频素材,剪辑成片的功能。
OppoFind X7也宣布让70亿参数的AndesGPT真正地装进手机,并实现内存和存储空间的进一步优化。
谷歌的Pixel 8 Pro今年12月已经用上了自家的Gemini Nano,不过目前只有两个比较简陋的应用:一是在录音APP里对音频进行自动摘要,二是通过谷歌键盘进行智能回复[6]。
2000年前后,用拨号上网下载一个1GB的文件大概要上千元,到了今天1GB的流量在手机上也就几毛钱。这种成本的大幅降低,实际上才是互联网普及的关键。
同理,AI想要普及,问题的关键还是成本。
但恰巧,成本问题是咱们最擅长的环节,看看拼多多、Shein如何做到全球最低价,看看华为是如何让非洲普及5G,看看印度人钟爱小米。
如果说美国最擅长技术上的突破,那么中国最擅长的则是:
让技术带来的普惠走进千家万户。
参考文章:
[1] 微软小模型击败大模型:27亿参数,手机就能跑 | 机器之心
[2] 火成这样?OpenAI暂停新的ChatGPT Plus订阅|华尔街见闻
[3] ChatGPT 提升算力需求增长中枢,超算服务器出货量有望大幅提升|安信证券
[4] 卷生成式AI的旗舰手机,2024年会引发一场交互革命|机器之心
[5] vivo发布蓝心大模型,手机端运行且开源,自研系统亮相 | 机器之心
[6] Google’s Gemini AI model is coming to the Pixel 8 Pro for recording summaries and smart replies | The Verge
[7] The bigger-is-better approach to AI is running out of road | The Economist
[8] Better not Bigger: Distilling LLMs into Specialized Models | Enterprise LLM Summit
[9] Sam Altman: Size of LLMs won’t matter as much moving forward | TechCrunch
[10] Training Compute-Optimal Large Language Models
[11] Introduction to Knowledge Distillation | Deci
[12] Distilling the Knowledge in a Neural Network
本文来自微信公众号:新硅NewGeek(ID:gh_b2beba60958f),作者:刘白,编辑:张泽一
相关推荐
中国SaaS的当务之急,不是创新,而是跑通赚钱模型
小米玩不起AI大模型
大模型不是手机厂商的杀手锏
大模型创业潮:狂飙 180 天
大模型的智能,不是人类的智能
大模型不是巨头的宠物
别吹了,自动驾驶大模型PPT们
投资人,看不懂大模型
陆奇的大模型世界观
院士称大模型对话聊天绝对不是刚需院士称大模型对话聊天很难形成商业模式
网址: 不是大模型用不起,而是小模型更有性价比 http://www.xishuta.com/newsview103082.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95258
- 2人类唯一的出路:变成人工智能 21448
- 3报告:抖音海外版下载量突破1 21429
- 4移动办公如何高效?谷歌研究了 20592
- 5人类唯一的出路: 变成人工智 20589
- 62023年起,银行存取款迎来 10361
- 7五一来了,大数据杀熟又想来, 8832
- 8网传比亚迪一员工泄露华为机密 8551
- 9滴滴出行被投诉价格操纵,网约 8455
- 10顶风作案?金山WPS被指套娃 7250



