你和人工智能的对话,正在被人工收听
编者按:本文来自微信公众号“燃财经”(ID:rancaijing),作者 周晶晶,编辑 阿伦。36氪经授权发布。
如今,智能设备越来越多地出现在每个人的生活中,在享受它们带来的便利时,很多人或许没有意识到,自己说的话可能会被人工“窃听”并分析标注,而原因是——厂商想让这些设备变得更智能。
“放首牛德华的歌”,一段带口音的成年女声从电脑里响起,但机器把它识别成了“儿童”的声音,这是机器常犯的错误,标注员唐顿把它修改为“成人”,紧接着还要把“牛德华”注释为“刘德华”,好让机器下次变得“聪明”一点。
听写、标注这些声音,是唐顿五年来的日常工作。
这五年,她每天大约要听1000个陌生人的声音,这些声音出现在不同场景:一位带有南方口音的尖锐男声发出指令“小薇你好,请播放沙漠骆驼”,背景里伴随着车辆闪光灯滴答滴答的声响;一位略带不耐烦的女声高喊“关闭导航”;偶尔,还有车主通过骂脏话发泄情绪的声音……
唐顿不明白为何要对这些声音进行标注,她把问题抛给领导后,得到的反馈是——“机器需要数据来自我优化”。唐顿因此调侃自己是人工智能背后的女人。
人工智能的进化,需要大量数据来“喂养”,这催生出一个全新的产业,像唐顿一样的标注员越来越多,一个庞大的系统正在形成。
为AI打工的青年
早上8点,家在河南的张艺诚打开电脑,带上耳机,输入账号密码后进入到一个后台系统,开始一天的工作。
1个月前,他陆续加入了两个近2000人规模和两个50人规模的标注团队,每次能领到一个约有150条语音的数据包,大概要在1小时内做完,做完后才能继续领任务。
张艺诚向燃财经展示抢到的不知来源的语音包,从内容上看场景较为私密,有“涛哥,下班了一起斗地主啊”、“好心累呐”、“你在哪”等。
相比“领”任务,张艺诚认为,用“抢”更贴切,“僧多粥少,能抢到多少取决于老大的能力。”
张艺诚向燃财经展示的50人团队里,大家称管理员为“老大”,老大们之间也有竞争,团队转录的数据质量越高、速度越快,老大能拿到的单子就越多,才能“喂饱”团队并继续扩大规模。同时,团队规模越大,对上游的话语权也就越大,能领到的单量也更多、质量也更高,这是相辅相成的关系。
不管团队是上千人还是几十人,新人加入都必须先经过测试,测试之后是培训,紧接着才是领任务,最后还得有一轮人工质检审核,因为客户通常要求最终的准确率在95%以上。
想通过测试并不容易,需要记住繁琐的细节规范,比如哪些客户需要在转写英文字母时大写、哪些要求小写,哪些情况会直接视语音为“无效”,发音不清的字词哪些需要加音标、哪些不加,“且动不动就要整批打回”,除此之外还得听得懂特定场景的术语。

语音标注员需要遵循的标注规范(部分)
张艺诚让燃财经尝试转录了10条他收到的语音包,从内容看是发生在游戏同伴间的对话,里面出现了包括“吕布”、“李白”、“房主”等在内的王者荣耀游戏里的称呼,通常带有环境噪音,麦克风偶有喷麦,并不容易听清。
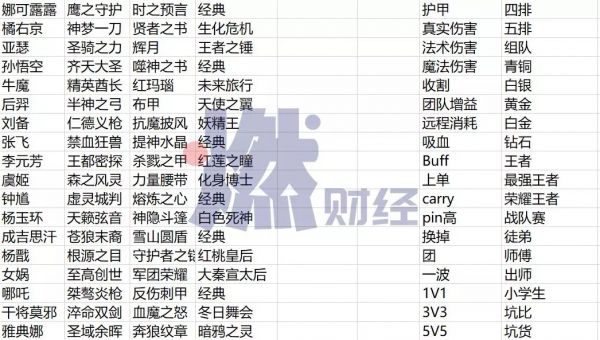
标注员需要熟悉的专业词汇
张艺诚展示的录音,大多来自拥有语音交互功能的产品,如车载语音、智能音箱,其中包括百度小度、天猫精灵的用户录音,还有来自携程的客服录音和来自滴滴的司乘录音。但大部分任务并不以客户名称命名,而是以音频长短来区分。
燃财经体验后发现,交互类型的音频多在2-5秒之间,通常夹杂噪音,大部分是用户和语音产品的对话,少数能明显判断为意外触发的录音,且未出现暴露用户身份信息、位置信息的情况。
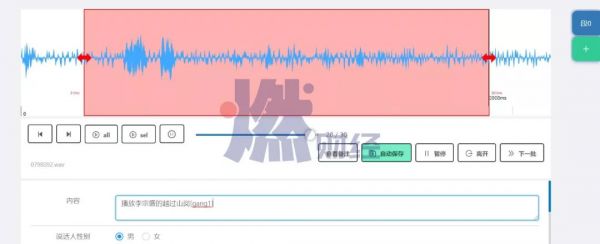
语音标注员需要用到的后台系统及显示界面
其中,小度音箱的转录注意事项注明:如果整句跟旁人聊天的无效,只有跟小度对话的才有效。
而在燃财经体验的车载语音中,大部分为带口音的普通话用户,点播的歌曲类型多为东北社会摇和快手热门歌曲。
张艺诚表示,这是一项完全没有技术的累活,1小时有效时长录音,能带来100元报酬,但听下来需要30个小时,平均时薪只有3块多钱。即使是干了五年的唐顿,平均月薪也只有三千。
AI迫切需要成长,张艺诚和唐顿们只会越来越多,他们大多遍布在河南、山东、河北等地的四五线小城里, 夜以继日地为世界领先的AI产品服务。
美国AI研究机构Cognilytica预计,截止2018年,全球数据标注相关产业的产值将增长66%达到5亿美元,2023年产值更将翻一番,而由于大部分工作都在“水下”,具体产值尚且难以准确估算。
财大气粗的数据服务商
与遍布在四五线小城镇里的打工者不同,被转录的数据包通常由具备一定规模的人工智能公司或数据服务商发布。
在BOSS直聘上,燃财经以“数据标注员”为关键词,搜索到超过100条相关职位信息,发布这类职位的公司通常处于B轮或C轮阶段、具备一定的资金实力,有的直接在职责介绍中注明——“智能语音、图片等相关数据的语义理解及标注”、“对已标注数据的清洗,保证标注数据的正确率”。
对于燃财经“数据清洗是什么”的疑问,一位负责招聘的hr回答:使用软件对数据进行操作,不是很难。
当燃财经继续询问是否是“将录音内容转写成文字”时,对方表示“是的”,同时透露客户是小米,但问到具体会是什么语音包时,对方不再回复。
而在张艺诚加入的四个群背后,发布的任务大多来自一个叫海天瑞声的公司。
公开资料显示,该公司成立于2005年,专注于人工智能上游的数据资源服务,服务场景包括人机交互、智能家居、智慧城市等。
招股书显示,海天瑞声有三大主营业务,分别是数据资源定制服务、数据库产品和数据资源相关的应用服务。前五大客户为阿里巴巴、三星、腾讯、微软、百度,贡献了2018年营业收入的59.6%,总计1.1亿元,其中阿里巴巴排名第一为5179万。
2016年-2018年,海天瑞声分别实现营业收入8422.86万元、1.19亿元、1.93亿元,净利润为1028.93万元、3414.96万元、6714.16万元。
2016年-2018年,数据资源定制服务及数据库产品两项收入合计占营业收入近99%,两者毛利润合计占比也是超过95%。海天瑞声的招股书中,对数据资源定制服务和数据库产品定义如图:

来源 / 海天瑞声招股书
无论是从数据资源定制服务还是数据库产品的销售情况来看,智能语音数据资源的销售是主要收入来源。

来源 / 海天瑞声招股书
2019年,海天瑞声还上演了一场科创板“逃跑计”。7月26日,其上会审核状态变更为终止审核,科创板上市之路告一段落,舆论认为原因在于其核心技术不足。
从公布的软件著作权以及在申请专利来看,海天瑞声的大部分技术是用于语音数据采集与处理环节。可见,公司的核心技术主要体现在录制及标注语音数据方面。
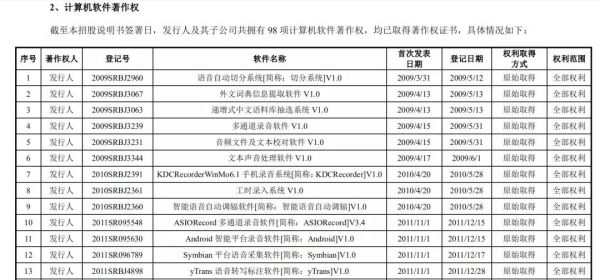
来源 / 海天瑞声招股书
而由于录制及标注语音数据需要大量廉价劳动力,这也是公司经常大规模招兼职的原因。
“在能看得见的未来,我们还得为AI打工”
在电影《她》中,那个由斯嘉丽·约翰逊配音的人声智能系统Samantha拥有极高的情商,为讨好使用者继续订阅,Samantha不仅需要让男主人泰奥多尔完全相信她与人类无差,同时还要尝试让对方爱上自己,为此,永远都不能听错或理解错泰奥多尔说过的任何一个字。
这是一部来自2013年的电影,时间来到2019,距离电影中的愿景还很遥远。
一位来自北邮人工智能研究院的研究员周洲告诉燃财经,一个好的模型数据量基本都是上百万级别的,通过用户自发产生的数据,才是最贴合实际业务的好数据。
“机器学习,你教他什么,他才能学会什么。以目前的技术,脱离大数据学习的强人工智能模型还是很遥远的。”周洲说。
他解释了AI的训练过程:“首先,AI训练需要一个模型,这个模型需要通过一定量的基础标注数据进行训练,获得一个预期的训练结果,比如对预测天气的语句识别率达到60%或更高。这时候投入使用环境会产生大量的用户数据,这些数据再经过甲方脱敏处理——去掉姓名地址等能透露用户身份的信息,再交由人工进行二次标注。
这就来到了大量廉价标注员标注的环节。通过一些标准,把质量高的音频筛选出来,因为引入一些冷门的数据反而会降低模型的表现。通过这些数据进一步调整模型,使模型能够更加适合自己的业务场景,这样就构成了一次迭代,然后不断循环。”
具体到语音交互产品,周洲补充,如果一个音箱恰好在南方地区销售比较好,那么他们就可以通过数据调整,对南方口音有更好的识别率。
曾做过语音交互产品的创业者告诉燃财经,目前对智能语音产品的需求是,它能听懂我说的话并反馈给我想要的东西,而中华文化博大精深,不同地域又有不同表达,加上生活和书面语言还不一样,这些都需要交代在系统里。
AI的生长需要优质数据喂养,而另一边,不知情的用户也开始反击。
2019年4月,亚马逊被爆在世界各地雇佣了数千名员工,对Echo音箱捕捉到的录音进行转录、注释;
7月,苹果被爆用户与Siri的对话可能会被录音,并且上传至苹果,由苹果分发给Siri的外包公司进行分析,迫于舆论压力,苹果表示暂停语音分析业务;
同月,谷歌承包商泄露了超过1000份用户与谷歌助理交谈的录音,录音来自于Google Home智能音箱以及语音助手。
对此,亚马逊、苹果、谷歌的回应基本一致,“偷听”是为了提高各自旗下语音助手的智能性。
尽管在发布数据包前,大部分公司会对数据进行脱敏处理,但在用户未知情的情况下,这是否触犯了法律?
对此,有多年司法工作经验的中经天平副主任王凯告诉燃财经,无论是否用于牟利,或者是为了提高服务和产品质量,采集和抓取用户数据的首要原则,就是要有用户授权。“即使是不涉及用户身份信息的指令性录音,如‘播放音乐’,在没有经过授权去抓取这个数据,也属于违法。”
市面上大部分产品以是否同意隐私协议内容作为用户授权的方式,但对用户来说,虽然选择权掌握在手,大部分情况还是处于被动状态,这是因为大部分产品只有在同意授权后才能使用。
对此,王凯表示,从法律上来说,还有一个问题,即便得到了用户授权也要考虑到用户是否完全了解授权的内容,授权之后是否有清晰的提示与展现,以及是否是本人进行操作等等情况。
“但回归到问题本质,是否合法还得看最终如何去使用这个数据。如果是倒卖给第三方,或者使用在用户不知情的地方,仍然是违法的;
如果协议中并未明确数据将会如何使用,则处于不完全告知状态,这也存在一些法律风险,但目前并没有一个明确的法律条款去规范,只能说如果用户能找到明确侵权证据,那就属于违法。”
燃财经查阅了小度音箱的用户协议和隐私协议,协议显示:“当您激活DuerOS程序或唤醒DuerOS设备后,我们会自动接收并记录您与设备终端进行交互过程中产生的音频、视频等相关信息。”
值得注意的是,协议还表明:“若您拒绝我们收集上述信息……将导致您无法获得相关服务。”

小度音箱用户协议
燃财经就用户协议向百度和阿里相关人员咨询,截至发稿,未获回应。
一方面,AI变得更智能需要更多用户数据,另一方面,用户数据属于隐私应该保护,而法律的完善不是一朝一夕的事,这似乎形成了一个无解的困境。
是否能提出一个大胆的设想:在不久的将来,AI训练不再依赖大数据?
对此,周洲表示,“现在已经存在一种强化学习的方式,就是机器可以通过一部分简单学习后,自己产生数据进行自主学习,AlphaGo就是这样。”
“但目前强化学习还只能用于规则既定、奖惩明确的场景,比如下棋、玩游戏等,下错了就会失败,机器人可通过奖惩的方式去学习,但现实更多情况是复杂的,很难制定一个明确的奖惩规则。”
他补充,未来确实有实现的可能性,不过这个未来有多远就不知道了,至少在能看得见的未来,我们还得为AI打工。
“What happens on your iPhone, stays on your iPhone(在iPhone上发生的事,就让它留在iPhone上)”,这是今年年初的CES展上,苹果公司在会场外投放的巨型广告宣传语,目前看来,这可能只是一个美好的幻想。
相关推荐
你和人工智能的对话,正在被人工收听
谷歌承认雇人收听智能助手记录的用户音频
人工智能还是人工智障?带你看看大型算法翻车现场
人工智能,还是“人工”去实现智能?从ScaleFactor的倒掉谈起
人工智能正在改变你看待世界的方式
对话达摩院科学家:阿里人工智能这五年
周杰伦所有歌曲付费收听,你愿意为偶像买单吗?
苹果为其员工收听Siri录音道歉:不再保留Siri互动录音
摘掉“骚扰电话”帽子,电话机器人助力疫情排查,效率超人工100倍
网红送餐无人车被指用人冒充AI:没有人工,就没有智能
网址: 你和人工智能的对话,正在被人工收听 http://www.xishuta.com/newsview10555.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95228
- 2人类唯一的出路:变成人工智能 21183
- 3报告:抖音海外版下载量突破1 21148
- 4移动办公如何高效?谷歌研究了 20339
- 5人类唯一的出路: 变成人工智 20338
- 62023年起,银行存取款迎来 10336
- 7五一来了,大数据杀熟又想来, 8596
- 8网传比亚迪一员工泄露华为机密 8505
- 9滴滴出行被投诉价格操纵,网约 8215
- 10顶风作案?金山WPS被指套娃 7230



