Sora:大模型从读万卷书到行万里路
我不能创造的,证明我没有理解(What I cannot create, I do not understand)——理查德·费曼
大年初七(实际上是西海岸的初六)就被Sora刷屏了。看了官网的视频和技术报告,还有一些评论。整理了这些想法作为笔记,和大家分享,践行下开源和learn in public的精神。
一、Sora的惊艳之处
Sora可以生成长达一分钟的视频——当前的文生视频的SOTA(最好的模型),比如RunWay和Pika是3-4秒。
Sora能同时保持视觉质量和提示词的一致性,也就是说,作为一个“视频剪辑师”,他理解需求的能力很强。
作为一个“摄影师”,Sora还很专业:能生成具有多个角色、特定运动类型的复杂场景。可以在单个生成的视频中展示多镜头拍摄视角,并且对象是统一的。
Sora还学会了物理(对人类来说的“物理常识”恰恰是对计算机而言最难的,也是此前文生视频模型一大痛点):模型不仅理解用户在提示中要求的内容,还理解这些东西在物理世界中的存在规律。
二、Sora目前的缺陷
可能难以准确模拟复杂场景的物理,也可能无法理解因果关系的具体实例。例如,老太太吹完蜡烛开始鼓掌,但蜡烛其实还没有熄灭。
模型也可能混淆提示的空间细节,例如,将左边和右边混在一起,并可能难以精确描述随时间发生的事件,比如沙漠考古中凭空多出来的椅子,几只小狗玩耍画面中,小狗的数量忽多忽少。
三、Sora技术报告主要内容
技术报告是一贯的CloseAI精神,一些核心要点都按下不表,比如数据/算力方面的信息。主要介绍了两个点:一是技术路线(轮廓)——用生成式模型进行统一视觉数据表示,二是视频生成能力的量化评估,对模型的优势和缺陷的描述。
核心技术是四个:循环神经网络、生成对抗网络、自回归Transformer、扩散模型,这些都贯穿OpenAI早年的技术探索中。
借鉴了大语言模型(LLM)的思路(用Token统一表示文本、代码、符号),用Patch(视觉补丁)表示视频。把视频压缩到低维空间(latent space),然后表示为时空补丁(Spacetime patches)。
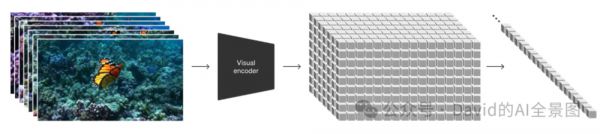
在扩散模型(准确说是扩散Transformer)上,通过条件信息,比如我们输入的提示词,来预测下一个Patch(视觉补丁)来生成视频,就像LLM预测下一个Token生成文本一样。

Sora可以基于文本、也可以基于图像和视频预测下一个Patch,当然也可以生成一个图,就像Midjouney和Dall·E一样,不过那样有点大材小用。
Sora还可以模拟数字世界、比如电子游戏,还可以和世界互动,比如一个人吃汉堡后留下咬痕,画家的画笔下增加新的笔触。
四、OpenAI的技术理想
技术报告最后有一句很重要的话:
我们相信Sora今天展现出来的能力,证明了视频模型的持续扩展(Scaling)是开发物理和数字世界(包含了生活在其中的物体、动物和人)模拟器的一条有希望的路。
OpenAI的目标并不是PK现有的文生视频模型(比如Make-A-Video、Video LDM、Text2Video-Zero、Runway-Gen2、NUWA-XL、Pikal Labs),或是颠覆广告和影视行业——这些在OpenAI看来都是“短期应用”,OpenAI把Sora视为理解和模拟现实世界的模型基础,视为AGI的一个重要里程碑。
2016年的一篇论文开头写道(译文来自SIY.Z):
我们常常会忽略自己对世界的深刻理解:比如,你知道这个世界由三维空间构成,里面的物体能够移动、相撞、互动;人们可以行走、交谈、思考;动物能够觅食、飞翔、奔跑或吠叫;显示屏上能展示用语言编码的信息,比如天气状况、篮球比赛的胜者,或者1970年发生的事件。这样庞大的信息量就摆在那里,而且很大程度上容易获得——不论是在由原子构成的物理世界,还是由比特构成的数字世界。
挑战在于,我们需要开发出能够分析并理解这些海量数据的模型和算法。生成模型是朝向这个目标迈进的最有希望的方法之一。要训练一个生成模型,我们首先会在某个领域收集大量的数据(想象一下,数以百万计的图片、文本或声音等),然后训练这个模型去创造类似的数据。这个方法的灵感源于理查德·费曼的一句名言:我不能创造的,证明我没有理解(What I cannot create, I do not understand)。
BTW,2016年的这篇论文第一作者是Andrej Karpathy,却在Sora发布前夕离职,确实有些费解。
最后,一些个人非结构化的思考:
五、用比问题更高一维度的视角看待问题
LLM把所有的文本、符号、代码都抽象为Token,Sora把图片、视频都抽象为Patch。
爱因斯坦说过:We cannot solve our problems with the same thinking we used when we created them(我们不能用创造问题时的思维来解决问题)。把问题升维的妙处在于:在高一维度,问题会更简单。
还有一些值得考究的经典例子:计算机把所有问题抽象为数学,并用0和1表示。量子计算的量子比特可以实现量子叠加(同时处于0和1状态)。爱因斯坦的统一理论,统一了质量和能量,时间和空间。在高维视角下,万有引力其实是一种时空弯曲。
就像Nvidia的Jim Fan博士所分析的那样,如果要生成这个“两艘海盗船在咖啡杯里互相战斗的逼真特写视频”,用低维的解决方法视角会觉得不可思议:

Sora生产的视频,来源:OpenAI
模拟器实例化了两个精美的 3D 资产:具有不同装饰的海盗船。Sora 必须在其潜在空间中隐含地解决文本到 3D 的问题。
3D 对象在航行和避开彼此的路径时保持一致动画。
咖啡的流体动力学,甚至是围绕船只形成的泡沫。流体模拟是计算机图形学的一个整体子领域,传统上需要非常复杂的算法和方程。
几乎像使用光线追踪渲染的照片级真实感。
模拟器考虑到杯子与海洋相比的小尺寸,并应用了倾斜移位摄影技术,以给出一种“微缩”感觉。
六、关于“真实世界不存在了”
眼见不再为实,视频真实性会遇到前所未有的挑战,但道高一尺,会有视频分类器。这个在Sora技术报告提到了,OpenAI正在开发,会加入到C2PA(Coalition for Content Provenance and Authenticity)内容出处和真实性联盟。C2PA是一个旨在通过开发技术标准,来认证媒体内容来源和历史的联合项目。目标是制定内容出处和真实性的技术规范,为数字媒体创建、发布和分享建立透明和可信的环境。

七、对现有行业的影响
容易想到的是短视频、影视/广告行业。
短视频平台可能会充斥大量AI生成的视频,对于Tiktok和视频号这样的平台而言,消极的因素是:数据存储需求剧增,平台可能需要推出分类器,给视频打上是否是AI生成的标签,加入到推荐算法权重中。对于视频创作者,消极面是用户注意力会被大幅稀释,行业更卷。积极面是,拍摄和剪辑能力进一步民主化,大家进一步卷的是创意和想法, 而不是拍摄设备和剪辑技巧。
对于影视/广告行业,工业化制作的时代正在落幕,下一个时代会很难理解一个“大制作”背后的成本——几百人上千人,分成摄影组/演员组/服装组/化妆组/灯光组/特效组,几年在拍摄现场不眠不休,吃着盒饭,在花费不菲搭建的布景地和道具堆中,用昂贵的设备、一遍遍折腾着天价片酬请来的演员。
积极的视角,正如Elon Musk说的:AI增强的人类将在未来几年里创造出最好的作品。
技术中最迷人的一面,就是让一些经济成本过高行业的专业化祛魅(从另外一个角度看其实是垄断和进入门槛),让更多的玩家进入,让人人平等地发挥自己的天赋,创造出更有想象力的作品。
最后总结一下:Sora是Transformer架构和Diffusion模型的合体,OpenAI继续Scale up(甚至此前有Sam Altman希望用7万亿美元重构芯片市场的传闻),LLM(大模型)从此前的读万卷书到现在开始行万里路——从视频和真实世界学习。
这确实是一个AGI的里程碑,但后面还需要多少里程碑?估计这位老爷子知道答案:

Sora生产的视频截图,来源:OpenAI
参考资料:
作为世界模拟器的视频生成模型:Video generation models as world simulators (openai.com)
Generative models: (openai.com)
如何看待openai最新发布的sora?- SIY.Z的回答 - 知乎
https://www.zhihu.com/question/644473449/answer/3397947587
《Scalable diffusion models with transformers》, https://arxiv.org/abs/2212.09748
https://mp.weixin.qq.com/s/gSvxvOVqYtGcKw0ueDGbFA
https://mp.weixin.qq.com/s/2iGVsdz6YHHupsKIPxRjdQ
本文来自微信公众号:David的AI全景图(ID:aifromchina),作者:李光华DavidLee
相关推荐
Sora:大模型从读万卷书到行万里路
OpenAI刷屏的Sora模型,是如何做到这么强的?
OpenAI又爆了!首个视频生成模型Sora惊艳亮相,视频行业被颠覆?
胡锡进谈文生视频模型Sora:这是爆炸性进展!
Sora横空出世 它会重塑影视行业吗?
Sora是怎么训练出来的
揭秘Sora,OpenAI是怎么实现1分钟一镜到底的?
Sora会对视频内容创作有什么影响?
我,ChatGPT,身高167cm
华为轮值董事长胡厚崑:当前的重要任务,是让人工智能服务于科学研究
网址: Sora:大模型从读万卷书到行万里路 http://www.xishuta.com/newsview108688.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95233
- 2人类唯一的出路:变成人工智能 21212
- 3报告:抖音海外版下载量突破1 21183
- 4移动办公如何高效?谷歌研究了 20367
- 5人类唯一的出路: 变成人工智 20366
- 62023年起,银行存取款迎来 10342
- 7五一来了,大数据杀熟又想来, 8621
- 8网传比亚迪一员工泄露华为机密 8512
- 9滴滴出行被投诉价格操纵,网约 8242
- 10顶风作案?金山WPS被指套娃 7234



