为什么说Sora是世界的模拟器?
AI 视频生成的“ChatGPT时刻”比想象中提前了6个月。
Sora 的诞生意味着什么,何以堪称“世界的模拟器”?
OpenAI 技术报告中透露,Sora 能够深刻地“理解”运动中的物理世界,堪称为真正的世界模型。
而 LeCun 则一贯酸溜溜地认为 Sora 不能理解物理世界,在他看来,“仅根据文字提示生成逼真的视频,并不代表模型理解了物理世界。生成视频的过程与基于世界模型的因果预测完全不同”。
Sora 真的理解物理世界吗?与 ChatGPT 的底层逻辑有什么异同?
成为物理世界的模拟器,Sora 是唯一的解法吗?
OpenAI 接连核爆,“暴力美学”之路真的能抵达 AGI 吗?
Sora 是世界的模拟器?
OpenAI 在其技术报告中只字未提数据规模、训练成本等相关的细节,但其标题赫然指出 Sora 这类视频生成模型是“世界的模拟器”。
OpenAI 想强调,Sora 不是单纯的视频生成模型,不只是视频行业的颠覆者,而是“世界的模拟器”——它打开了一条通往模拟物理世界的有效路径。
OpenAI 仅列举了作为物理世界的模拟器应具备的几个特点和例子——3D一致性、远程相关性、物体持久性、与世界互动等,却并未对“什么是世界的模拟器”做任何定义和具体分析。
但我们大概可以总结出它的逻辑:Sora生成的视频能够在相当长的时空范围内,不违反物理世界的常见规律(比如重力、光电、碰撞等)。如果模型规模进一步提升,它有可能模拟生成物理世界的一切视频。
我们不禁疑问,为什么 OpenAI 在此时提出“模拟器”这一概念,它究竟是什么?如何成为“世界的模拟器”?与单纯的视频生成模型有什么逻辑关系?进而,一个能够模拟复杂世界动态的 AI 会将人类带往何处?
在谈物理世界的模拟器之前,我们先重温一下虚拟世界的模拟器——ChatGPT。
ChatGPT 是虚拟思维世界的“模拟器” ?
何谓“模拟器”,顾名思义,如同动态镜像一般,模拟器是可以逼真“反映”虚拟世界或现实世界的模型或系统。
游戏可视为一种对现实世界的模拟,所谓数字世界。
游戏的数字世界通常有一个既定的环境,包括人物、场景、功能道具等,还有一个起始的配置。给以目标指令,按下“start”,游戏主角便可以开始出发探索这个世界,与之互动。
比如在小游戏《超级马里奥》中,主角马里奥和每一关卡的场景都是既定的环境,小马里奥只身出场是起始配置,在规则下赢得金币是目标指令,“start”游戏开始,直达旅程目标。
这就是一个最简单模拟器的模拟过程,构造了一个既定场景的小世界。
在 ChatGPT 这类应用中,我们通常可以为模型设置角色,例如设置为用户的助理、教师或伴侣(可视为环境),用户就可以给出目标指令开始与之交互。
比如可以让 ChatGPT 写一篇关于 Sora 的文章,给它一段开头,ChatGPT 就会续写整篇;给定一段故事结尾,它可以补足故事的来龙去脉;给出一段故事节选,它可以展开前后两端的想象,予以扩写;给定完整的篇幅,它也可以缩写摘要。成篇非常顺畅丝滑,符合文法和逻辑。
这些语言任务的完成,其实是在模拟创作者的思维过程。
而对创作者思维的模拟,需要遵从思维背后的逻辑和常识。比如 ChatGPT 在续写 Sora 原理的文章时,会围绕深度学习和语言模型层层推进,逻辑线条合理,而不会跳跃到辛亥革命或咖啡机使用指南。
ChatGPT 作为语言模型 ,通过“语言”这一思维的载体,可以多方面模拟虚拟世界中的各种场景和角色(合理丝滑的故事线),成为虚拟世界的“模拟器”。
既然 ChatGPT 对答如流,也能模拟不同风格的文学家、诗人写诗作文,作品不违反常识,也符合人类思维规律,那是否说明它就掌握了这些规律呢?
功能主义角度的回答是肯定的。我们可以认为ChatGPT是懂得思维的,是理解思维世界的,具有自己的认知。虽然我们没有一一教他具体的思维逻辑和常识,但它读遍浩瀚的书籍数据,已然从数据中汲取了海量的知识,掌握了知识背后的思维逻辑。
ChatGPT这类语言模型从语言大数据中的学习,实际上就是在模拟一个充满了人类思维和认知映射的虚拟世界。
今天的ChatGPT已经攻下了虚拟世界“模拟器”的堡垒。它所反映的人类认知,包括常识、百科知识以及推理逻辑,实际上已经远远超过了绝大部分人类个体。
那么物理世界的模拟器会以何种方式呈现?
何为物理世界的模拟器?遵循物理世界规律
如同人类的思维世界要前后自洽,不违反常识,遵循分析归纳、逻辑推理等“规律”(统称思维逻辑),物理世界也有背后的“规律”,包括能量守恒定律、热力学定律、力的相互作用定律等等。
比如苹果不能突然在空中漂浮,这不符合牛顿的万有引力定律;比如在光线照射下,物体产生的阴影和高光的分布要符合光影规律等;比如物体之间产生碰撞后会破碎或者弹开。
作为“物理世界的模拟器”,需要能够在虚拟环境中重现物理现实,为用户提供一个逼真且不违反“物理规律”的数字世界。
技术上至少有两种方式可以实现这样的模拟器,一种是通过大数据学习出一个AI系统来模拟这个世界,比如说本文讨论的 Sora。
另外一种是弄懂物理世界各种现象背后的数学原理,并把这些原理手工编码到计算机程序里,从而让计算机程序“渲染”出物理世界需要的各种人、物、场景以及他们之间的互动。
虚幻引擎(Unreal Engine,UE)就是这种物理世界的模拟器。它内置了光照、碰撞、动画、刚体、材质、音频、光电等各种数学模型。一个开发者只需要提供人、物、场景、交互、剧情等配置,系统就能做出一个交互式的游戏,这种交互式的游戏可以看成是一个交互式的动态视频。
UE 这类渲染引擎所创造的游戏世界已经能够在某种程度上模拟物理世界,只不过它是通过人工数学建模及渲染而成,而非通过模型从数据中自我学习。而且,它也没有和语言代表的认知模型连接起来,因此本质上缺乏世界常识。而 Sora 代表的AI系统有可能避免这些缺陷和局限。
为什么 Sora 有望成为世界的通用模拟器?
不同于 UE 这一类渲染引擎,Sora 并没有显式地对物理规律背后的数学公式去“硬编码”,而是通过对互联网上的海量视频数据进行自监督学习,从而能够在给定一段文字描述的条件下生成不违反物理世界规律的长视频(虽然目前长度只有一分钟,但是完全碾压了此前有数秒限制的类似竞品,如曾被热捧的 Pika 和 Runway)。
与 UE 这一类“硬编码”的物理渲染引擎不同,Sora 视频创作的想象力来自于它端到端的数据驱动,以及跟LLM这类认知模型的无缝结合。
端到端的数据驱动更加通用、更方便迭代提升
与历史上所有的数据驱动的端到端AI系统一样,Sora 的优势是如果数据给力,数据量足够大,它可以覆盖各种各样的边界条件下的复杂度。与之相比,UE 能够硬编码的数学原理和场景模版毕竟是有限的,更何况很多物理世界的现象,人类还没有发现其背后的数学原理。
所以很多时候,UE游戏开发者不得不牺牲用户体验,或者手工对某些特殊情况“头痛医头”地做针对性专门编码。比如,由于材质和碰撞模型的不完善,大家经常看到数字人直播时的穿模现象(手插到肚子里去了),而要解决穿模问题得做很多额外的工作。
以迭代完善的角度,对于数据驱动的AI系统,我们只要利用摩尔定律,不停地加大数据和算力,系统就会自动越来越完善。而“硬编码”的系统则依赖于“人工”的努力和进展。
与认知模型的无缝融合让多模态模型更加通用和鲁棒
与很多人一样,我们为 Sora 视频的高质量所折服,但让我们真正兴奋的是,Sora 类视频生成模型的架构终于向 LLM 的架构靠近。
比如 Sora 采用 Transformer 作为模型的骨架来学习文本和视频的关系以及视频内部的时空关系。又比如 Sora 把视频数据 token 化。这样的好处是视频生成模型能跟 LLM 在模型层面无缝融合。
虽然我们现在无法判断 Sora 的训练是否将 LLM 作为起点,然后再加入视频的模态继续训练。但是几乎可以肯定的是,未来的多模态模型都会把 LLM 作为起点,从而把 LLM 的认知能力迁移到下游的其它模态里。
这既提升了下游模型的智能天花板,也大大降低了下游模型的数据需求。笔者多次强调,这种跨模态的知识迁移可能是 LLM 对AI建模的最大贡献,已经在RT-2、Gemini、出门问问魔音工坊的语音大模型等很多实践中得到证明。
为什么LLM的认知赋能及其与视频模型的无缝融合这么重要?
前文提到如果视频生成模型要成为世界的模拟器,那它生成的视频必须得符合物理规律。我们可以从大量的视频数据里学习这些规律,也可以直接继承语言模型里海量的常识,而继承这些常识会大大降低对视频数据的质量和数量的需求,也会大大降低模型学习的难度。
比如,如果我们让 Sora 生成一只杯子掉在地板上的视频。今天的大语言模型,比如出门问问的“序列猴子”,就含有玻璃会碎、水会溅出等常识(见下图)。
有了这些常识,视频生成模型将不再需要大量的类似玻璃掉地的视频数据来训练,从而大大降低了生成逼真视频的难度。语言模型还包含了对其它物理规律(比如声光电、碰撞等)的各种描述。
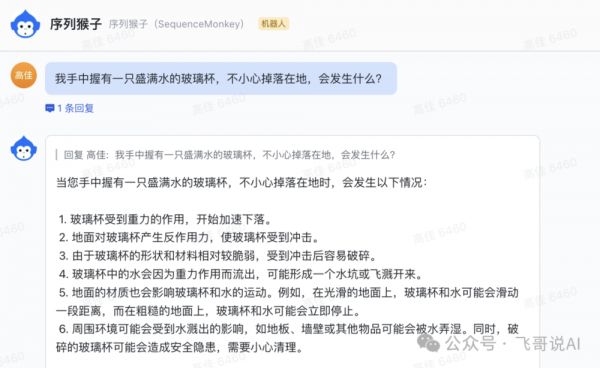

所以,如果 Sora 训练的基础是一个语言模型,这个模型不仅仅处理文本数据,而且继承了对世界常识的理解。
通过引入多模态数据处理能力——特别是视频与文本对应的数据——Sora 能够实现更深层次的Grounding,即将语言的虚拟概念与物理世界的具体实例紧密关联。
这种能力使得 Sora 在模拟物理世界时,能够更准确地反映出现实世界的复杂性和多样性。具象的视频训练数据总是有限的,因此模型所能学到的物理现象总有局限。
但语言模型中的物理常识几乎是面面俱到的,这是由语言作为思维认知模型的本性所决定的。这种知识迁移弥补了视频数据不可能面面俱到的短板。
语言模型是多模态大模型的核心,必将居于独一无二的中心赋能地位。而“视频”作为物理世界的映像,是世界模型渲染出来的结果。
相比语言数据,通过视频大数据学习到的模型是“模型的模型” ,同时学到了很多物理世界规律,让模型更加逼近模拟物理世界。
文本与视频的区别在于,前者是理解人类的逻辑思维,后者在于理解物理世界。所以,视频生成模型 Sora 如果能很好跟文本模型 LLM 融合,那它真有望成为世界的通用模拟器。如果有一天,这样的系统自己通过模拟驾车场景,学会了在城市复杂的交通环境下开车,我们应该也不会奇怪。
我们认为,Sora 之所以有潜力成为下一代物理世界模拟器的翘楚,主要归功于其基于多模态大模型的设计理念及其实现中巨大算力和工程能力。
Sora 在视频赛道重现 ChatGPT 式的成功,很可能得力于其把虚拟世界的模型(LLM)落地到具象化的物理世界模型(视频生成),如果现在不是这样,将来也大概率是。
能生成世界,就意味着理解世界?
类比语言模型,面对ChatGPT的对答如流、通情达理,我们反思语言模型到底是否学会了“思维”和“理解”?
虽然尚无法从原理上解释,但从结果上看,它与基于对语言的深刻理解所呈现出来的行为是一致的,我们可以认为它其实已经学会了虚拟世界的“思维”和“理解”;那今天的 Sora 已经可以在长时空的范围里生成不违反物理规律和常识的视频,我们是否也可以认为,它已经理解了物理世界?它具备了世界模型的能力?
模拟物理世界,Sora 是唯一解法吗?
如果 Sora 深度融合 LLM (如 ChatGPT)被认知智能充分赋能,它的确有望成为“世界的模拟器”。除此之外,还有其他成为世界模拟器的可能性解法吗?另外一种可能是:ChatGPT + UE。
如果我们能把自然语言模型(如 ChatGPT)与物理渲染引擎(如 UE)结合起来,把自然语言模型的描述转换成 UE 的描述语言,然后由 UE 来渲染出视频,是不是也意味着一个可行的物理世界模拟器?
在很多对通用性的要求不那么高的场景中,这可能是优于 Sora 这种端到端模型的选择,估计未来很快会看到这样的尝试。但是,UE的天花板就是整个系统的天花板。
另外一个相关话题,Sora 的训练可能用了 UE 合成的数据,但 Sora 模型本身应该没有调用 UE 的能力。
从虚拟到物理,如果世界皆可被模拟,什么是现实?
如果说这个世界(无论是虚拟世界还是物理世界),其背后存在着简单的规律和模型,那么文本和视频等模态就是这些规律的具体呈现,也可以说是渲染。
OpenAI 的 ChatGPT 和 Sora 通过互联网上海量的自然的文本和视频数据,“隐式”地学会了这些数据背后的规律和模型。那么,未来是否有一天,ChatGPT 和 Sora 之类的系统还将融合味觉、触觉等其他模态,从而可以模拟我们的整个世界呢?
如果这一天到来,什么是现实呢?我们是否还那么坚定地相信我们这个物理世界不是被模拟出来的?科幻电影《黑客帝国》所描述的世界是否仍是科幻呢?这是现代版的庄周梦蝶,古老的哲学思辨在后现代的技术浪潮中再度冲击我们的信仰,细思有点恐。
展开想象,为什么AI模拟器不可以模拟巴以冲突、中美关系,模拟人类从山顶洞走向农耕文明的过程呢?“世界模拟器”通过模拟不同的事件和情景,预测未来的发展趋势,或可辅助决策制定。Sora 类不仅能够模拟政治经济、人类社会等宏观层面的动态,也应该可以深入到病毒传播、交通规划等微观领域。这一切最终是否会改变各种学科研究的方式?
我们可以展望,AI 有能力通过模拟学会各种物理世界的技能。比如城市驾驶,AI 可以从文本里学到各种驾驶规则,自己渲染一些交通视频场景并在这些场景里学习提升,从而学会基本驾驶技能。当然,模型最后还是会有真正物理环境下的Fine Tuning。如果机器人能够自主学习各种技能,这是否也会改变机器人服务世界的发展路径?
总之,如果未来的 AI 既理解了人类思维,又理解了物理世界,而且还不知疲倦地自主模拟学习,下一步将会“涌现”怎样的斑斓世界?人类如何自处?
暴力美学能抵达 AGI 吗?
回看OpenAI的最初胜利,主要并非算法上的创新,而是“暴力美学”的胜利。
如今,以GPT为代表的“暴力美学”已成为工业界凝聚了共识的做 AI 的方法论:把模型架构做得简简单单,但足够通用,然后把精力放在猛搞数据和算力上。
这一次 Sora 的成功延续了 OpenAI 的暴力美学的套路。把 Diffusion Model 里的 Unet 换成 Transformer、把视频的时空 Patch 转换成 Token 等之类的想法应该很多人拍脑袋都能想到,都是对模型的简化从而更便于 Scale Up。但是,能够坚信这些简单的 ideas、并有能力和有条件把规模真正做上去修成正果的却是凤毛麟角。
OpenAI 这次关于 Sora 的技术 blog 里的两段话,把这种信念的力量体现得淋漓尽致。
“These capabilities suggest that continued scaling of video models is a promising path towards the development of highly-capable simulators of the physical and digital world, and the objects, animals and people that live within them.”
“We find that video models exhibit a number of interesting emergent capabilities when trained at scale. These capabilities enable Sora to simulate some aspects of people, animals and environments from the physical world. These properties emerge without any explicit inductive biases for 3D, objects, etc.—they are purely phenomena of scale.”
第一段话表达了他们对 Scaling 的信念,而第二段话强调了 Scaling 导致涌现的实证。
这次 Sora 的发布又让很多人对 AGI 的实现更加乐观了,可能也让心高气盛的 OpenAI 对 Scaling Law 和暴力美学的信念进一步坚定。但是,沿着 Scaling Law 和暴力美学一定能抵达 AGI 吗?面对飞速发展的AI科技,也许只能拷问自己,到底是因为看见而相信,还是因为相信而看见?
可以肯定的是,Sora 如果真能实现对物理世界的模拟、能够跟 LLM 代表的虚拟世界无缝融合,那它必然是通往 AGI 路上的里程碑。
结语
当我们回到人类文明的前夜,从用石头砸开坚果,从山洞走向茅屋,一一回望人类最早的科技成就——石制工具、火、衣服、长矛和弓箭是如何被发明的。正是有了让能力边界不断延伸的它们,人类才得以走出非洲。
其中最重要的一项能力——语言能力,它使现代智人能有效传递信息,不断完成物理世界的任务,最终将尼安德特人赶到比利牛斯半岛的尽头,成为世界主人。
而今天,掌握人类语言的AI,将能进一步地通过视频生成模拟世界,面向我们为之雀跃的 AGI 时刻,是否已是另一种文明的前夜?
本文来自微信公众号:飞哥说AI(ID:FeigeandAI),作者:李志飞李维、高佳
相关推荐
为什么说Sora是世界的模拟器?
Sora是怎么训练出来的
Sora “拯救”元宇宙,世界模型的潜力才刚释放
揭秘Sora,OpenAI是怎么实现1分钟一镜到底的?
Sora:大模型从读万卷书到行万里路
一场新的“革命”已经开始,揭秘OpenAI文生视频模型Sora技术报告
OpenAI为什么总是领先一个版本
技惊四座的Sora模型,参数只有30亿?
Sora带来的四点启发
OpenAI刷屏的Sora模型,是如何做到这么强的?
网址: 为什么说Sora是世界的模拟器? http://www.xishuta.com/newsview108871.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95252
- 2人类唯一的出路:变成人工智能 21395
- 3报告:抖音海外版下载量突破1 21365
- 4移动办公如何高效?谷歌研究了 20539
- 5人类唯一的出路: 变成人工智 20536
- 62023年起,银行存取款迎来 10357
- 7五一来了,大数据杀熟又想来, 8780
- 8网传比亚迪一员工泄露华为机密 8538
- 9滴滴出行被投诉价格操纵,网约 8404
- 10顶风作案?金山WPS被指套娃 7243



