“打假”Sora,谷歌Gemini 1.5 Pro第一波评测出炉
OpenAI 与谷歌同一天发布的两款 AI 模型正在“互相伤害”。
先是 OpenAI 的 “世界模拟器” Sora 完全抢走了谷歌最新一代多模态大模型 Gemini 1.5 Pro 的风头,让谷歌这出大招反响平平。谷歌也被戏称为“AI界的汪峰”。
很快,谷歌 Gemini 1.5 Pro 就来给 Sora “拆台”了。
一名谷歌董事将一条 Sora 生成的视频发给 Gemini 1.5 Pro,让其点评一下。Gemini 1.5 Pro 犀利指出了视频中不合逻辑的地方:
这段视频是在日本一条雪街上拍摄的,樱花盛开。有一些不一致之处表明这段视频可能是由人工智能生成的。
首先,雪花纷纷扬扬地飘落,但樱花依然盛开。樱花通常在春天盛开,当天气温暖而没有雪。
其次,雪以非常均匀的方式下落,这并不是雪在现实生活中通常下落的方式。
第三,视频中的人们没有穿任何冬季衣物,尽管下着大雪。
总的来说,这个视频在视觉上很吸引人,但不一致之处表明这不是一个真实场景。
您目前设备暂不支持播放
谷歌应该是最有实力改变大模型格局、给 OpenAI 带来压力的玩家。这次与 Sora 互相拆台的 Gemini 1.5 Pro,实力究竟如何?
一、第一波评测出炉,Gemini 1.5 Pro 表现如何?
谷歌 Gemini 1.5 Pro 是一个多模态模型,可以为不同模态执行高度复杂的理解和推理任务,同时可以在更长的代码块中执行更相关的问题解决任务。
不过,Gemini 1.5 Pro 目前尚未对公众开放,仅有少数用户加入内测,AI 工具库网站 Therundown.ai 创始人 Rowan Cheung 便是其中之一。
2月19日,Rowan Cheung 在 X 上发布了 Gemini 1.5 Pro 的六项能力测评。
1. 分析和理解长视频。
Rowan Cheung 上传了前一晚 NBA 扣篮大赛的整个视频,并询问哪个扣篮得分最高。
Gemini 1.5 凭借其出色的长上下文视频理解能力,能够从视频中找到得分最高的完美50分扣篮及其细节!
您目前设备暂不支持播放
2. 理解和比较《星际穿越》《星际探索》的完整电影剧本。
Gemini 1.5 能够理解、比较并对比这两部电影的完整剧本,帮助 Rowan Cheung 决定应该看哪部电影。
您目前设备暂不支持播放
3. 将语言翻译成只有不到 2000 人使用的语言。
Gemini 1.5 能够在推理时遵循完整的语言手册,将英语翻译成 Saterlandic (德国的一种语言,只有不到 2000 人使用)。
您目前设备暂不支持播放
4. 观看、理解和区分 OpenAI Sora 视频中的内容是否由 AI 生成。
Gemini 1.5 突出显示了著名的 Sora 猫视频,并强调了为什么它可能是由AI生成的关键因素。
Rowan Cheung 直呼“对它的回答深度感到惊讶”。
您目前设备暂不支持播放
5. 在一篇长论文中找到、理解并解释一个小图表。
Gemini 1.5 能够从 DeepMind 的 Gemini 1.5 Pro 论文中提取出“表8”,并解释了该表的含义。
您目前设备暂不支持播放
6. 理解整部《星际穿越》电影剧本,并突出关键时刻。
Gemini 1.5 能够找出《星际穿越》剧本中的 3 句最鼓舞人心的引语。
您目前设备暂不支持播放
二、背后的两大技术“杀招”
Gemini 1.5 Pro 有两大“杀招”——最强的 MoE 大模型,最高可支持 10000K token 超长上下文。
1. 高效的 MoE 架构
Gemini 1.5 Pro 建立在谷歌关于 Transformer 和 MoE(Mixture of Experts,混合专家)架构的领先研究之上。传统的 Transformer 作为一个大型神经网络运作,而 MoE 模型被划分为较小的“专家”神经网络。
MoE 是一种混合模型,由多个子模型(即专家)组成,每个子模型都是一个局部模型,专门处理输入空间的一个子集。MoE 的核心思想是使用一个门控网络来决定每个数据应该被哪个模型去训练,从而减轻不同类型样本之间的干扰。
基于 MoE 架构,与 Gemini 1.0 Ultra 相比,尽管 Gemini 1.5 Pro 的训练计算需求大大减少,但服务效率更高,在超过半数的评测指标上(16/31)表现更出色,特别是在文本处理(10/13)和多项视觉处理任务(6/13)上。
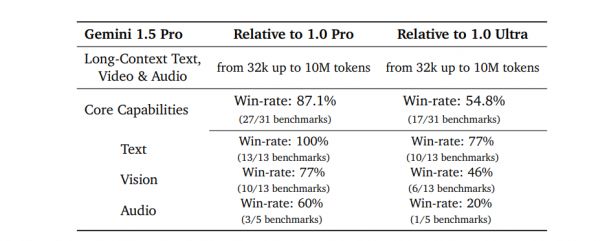
Gemini 1.5 Pro与Gemini 1.0系列比较
MoE 架构已经在大模型圈火了一段时间,比如被称为“欧洲版 OpenAI”的法国大模型公司 Mistral AI ,其 8x7B 模型就采用了 MoE 架构。微软紧跟着发布了全新版本的Phi-2 小模型;猎豹移动董事长 & CEO 傅盛近期对“甲子光年”表示,公司接下来也会考虑在模型中引入 MoE 架构。
“老大哥”谷歌在 MoE 路线上也早有布局,已经有 Sparsely-Gated MoE、GShard-Transformer、Switch-Transformer、M4 等成果。
谷歌最新的模型架构创新使 Gemini 1.5 Pro 能够更快地学习复杂任务并保持质量,同时在训练和服务上更加高效。
2. 支持超长的上下文窗口
去年下半年,各家大模型公司便开始卷上下文窗口的长度。
AI 模型的“上下文窗口”由 Token 组成,这些 Token 是用于处理信息的基本构建块,Token 可以是单词、图像、视频、音频或代码的部分或子部分。模型的上下文窗口越大,它在给定提示中能够吸收和处理的信息就越多,进而能使模型输出更加一致、相关性强且有用的内容。
通过一系列机器学习创新,谷歌增加了 Gemini 1.5 Pro 的上下文窗口容量,并实现在生产中运行高达 100 万个Token,远超 32k 的 Gemini 1.0、128k 的 GPT-4 Turbo、200k 的 Claude 2.1。
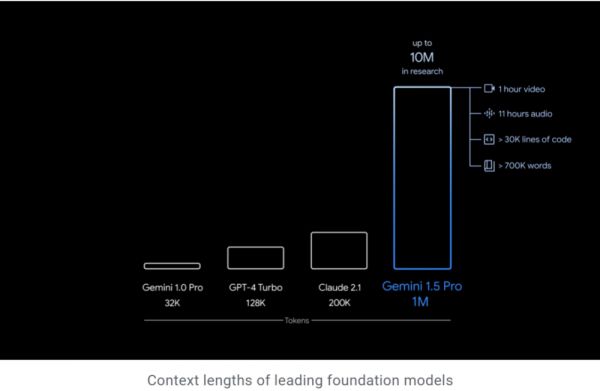
这意味着 Gemini 1.5 Pro 可以一次性处理大量信息——包括1小时的视频、11小时的音频、超过 30000 行代码的代码库或超过 700000 个单词。
谷歌还透露,内部研究已经成功测试了高达 1000 万个 Token 。
在给定的提示中,Gemini 1.5 Pro 可以无缝分析、分类和总结大量内容。例如,当给出阿波罗 11 号登月任务的 402 页记录时,它可以推理关于对话、事件和文档中的细节。
在现实世界数据中,这种上下文长度让 Gemini 1.5 Pro 能够轻松处理几乎一天的音频记录(约 22 小时)、超过《战争与和平》1440 页(或 587287 词)的书籍十倍的内容、Flax 整个代码库( 41070 行代码),或者以每秒一帧的速度播放三小时视频。
更进一步,由于该模型天生支持多模态,并能够将不同模态的数据混合在同一个输入序列中,它能同时处理音频、视觉、文本和代码输入。
在被称为“大海捞针”的 NIAH 实验评估中,实验人员故意将包含特定事实或陈述的小文本片段放置在长文本块中,在长达 100 万个 Token 的数据块中,Gemini 1.5 Pro 能够 99% 的概率找到嵌入的文本。
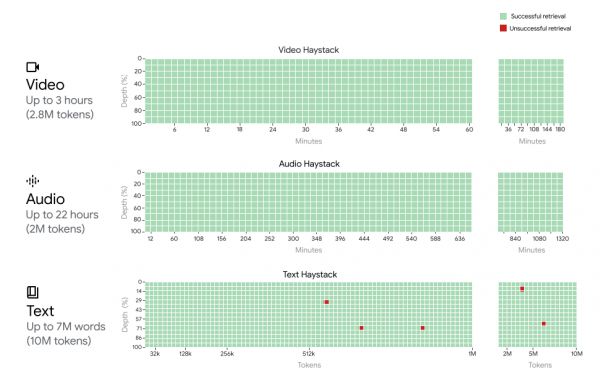
Gemini 1.5 Pro在所有模态(即文本、视频和音频)中实现了接近完美的“针”召回率(>99.7%),即使在“干草堆”中达到100万个标记。它甚至在文本模态中扩展到1000万个标记(大约700万字)、音频模态中达到200万个标记(长达22小时)、视频模态中达到280万个标记(长达3小时)时仍保持这种召回性能。x轴代表上下文窗口,y轴代表在给定上下文长度中放置的“针”的深度百分比。结果用颜色编码表示:绿色表示成功检索,红色表示失败。
三、谷歌不走 OpenAI 的老路
在 Sora 的技术文档里,OpenAI 并没有透露模型的技术细节,只是表达了一个核心理念——Scale。
OpenAI 将 Scale 列为企业核心价值观之一:“我们相信规模——在我们的模型、系统、自身、过程以及抱负中——具有魔力。当有疑问时,就扩大规模。”
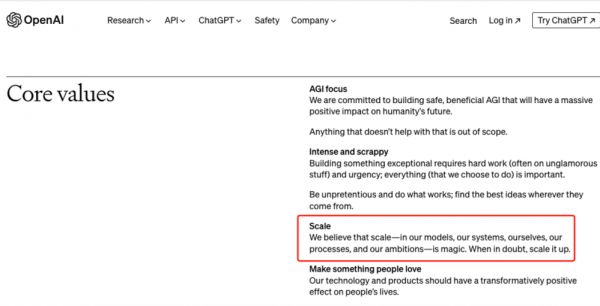
基于该理念,OpenAI 在 2020 年总结出了模型训练的秘诀——Scaling Law。根据 Scaling Law,模型性能会在大算力、大参数、大数据的基础上像摩尔定律一样持续提升,不仅适用于语言模型,也适用于多模态模型。
不过,目前来看,谷歌似乎并不吃 Scaling Law 这一套。
在最新访谈中,哈萨比斯表示:“你必须推动现有技术,看看它们能走多远,但仅仅扩大现有技术,你很难获得新的能力。如规划、工具使用或代理行为,这些不会神奇地发生。”
他进一步透露,自从 AlphaGo 时代以来,谷歌已经在 Agent、强化学习和规划的路上走了很长时间,这是谷歌真正的强项。“我们正在重新审视很多想法,考虑将 AlphaGo 的能力建立在这些大型模型之上,我认为内省和规划能力将有助于解决幻觉等问题。”
可以推测,谷歌正在试图搭建一个系统,来引导模型更有逻辑地思考,而并非一味追寻 OpenAI 的暴力美学路径。
毕竟,从科研角度来说,暴力美学的“黑盒”不够透明,且很难复制;从实际应用来说,暴力美学的成果也并不安全。
哈萨比斯则一直倡导建立模拟沙箱,在将 Agent 系统放在网上之前对其进行测试,也呼吁行业应该开始真正考虑 Agent 系统的出现。在他看来,Agent 系统将是一个完全不同的系统。
对于“模拟沙箱”的方法,国内大模型初创公司面壁智能在“小钢炮” MiniCPM 模型中也有应用。发布 MiniCPM 之前,面壁智能做了上千次的模型沙盒实验,探索出了最优的配置,所有尺寸的模型可以通过最优的超参数的配置,保证训练任意大小的模型取得最好的效果。
可以说,模拟沙盒的方法,或许能将大模型的训练过程从“炼丹”转化为一种“实验科学”。
无论是单纯的语言模型还是多模态,围绕 LLM 展开的技术与商业竞争都还处在早期,一切定论或许都为时尚早。OpenAI 伟大,但不应被神化。
Diffusion Transformer架构论文的作者之一的谢赛宁认为,在复杂 AI 系统的比拼中,人才第一、数据第二、算力第三,而谷歌是目前为止最能和 OpenAI 掰一掰手腕的老玩家,期待谷歌的后续表现。
本文来自微信公众号:甲子光年 (ID:jazzyear),作者:刘杨楠,编辑:赵健
相关推荐
“打假”Sora,谷歌Gemini 1.5 Pro第一波评测出炉
谷歌Gemini 1.5被OpenAI抢头条,是真的冤
GPT-4 Turbo惨遭碾压 谷歌刚发布的Gemini 1.5 Pro有多强?
OpenAI的Sora会砸掉谁的饭碗?
Sora带来的四点启发
OpenAI站在谷歌的肩膀上,用谷歌的技术刷屏
Sora互联网纪实:卖课割韭菜、A股大涨停
GPT-4地位难保,谷歌Gemini新王登基?
谷歌Gemini:被神话的多模态和被低估的隐忍
Gemini大规模商业化,谷歌在AI大战中不再谨慎
网址: “打假”Sora,谷歌Gemini 1.5 Pro第一波评测出炉 http://www.xishuta.com/newsview109189.html
推荐科技快讯






- 1问界商标转让释放信号:赛力斯 95093
- 2人类唯一的出路:变成人工智能 20339
- 3报告:抖音海外版下载量突破1 20157
- 4移动办公如何高效?谷歌研究了 19551
- 5人类唯一的出路: 变成人工智 19456
- 62023年起,银行存取款迎来 10251
- 7网传比亚迪一员工泄露华为机密 8371
- 8五一来了,大数据杀熟又想来, 7877
- 9滴滴出行被投诉价格操纵,网约 7501
- 10顶风作案?金山WPS被指套娃 7171



