阿里EMO模型,一张照片就能造谣
2月28日,阿里巴巴智能计算研究所发布了一款全新的生成式AI模型EMO(Emote Portrait Alive)。EMO仅需一张人物肖像照片和音频,就可以让照片中的人物按照音频内容“张嘴”唱歌、说话,且口型基本一致,面部表情和头部姿态非常自然。
EMO不仅能够生成唱歌和说话的视频,还能在保持角色身份稳定性的同时,根据输入音频的长度生成不同时长的视频。
您目前设备暂不支持播放
角色:张颂文饰演的高启强
声乐来源:法律考试在线课程
您目前设备暂不支持播放
角色:Audrey Kathleen Hepburn-Ruston
声乐来源:Ed Sheeran - Perfect. Covered by Samantha Harvey
您目前设备暂不支持播放
角色:来自SORA的AI Lady
声乐来源:Where We Go From Here with OpenAI's Mira Murati
您目前设备暂不支持播放
角色:蔡徐坤
声乐来源:Eminem - Rap God
您目前设备暂不支持播放
角色:张国荣
声乐来源:陈奕迅 - Eason Chan - Unconditional. Covered by AI (粤语)
EMO的工作过程分为两个主要阶段:首先,利用参考网络(ReferenceNet)从参考图像和动作帧中提取特征;然后,利用预训练的音频编码器处理声音并嵌入,再结合多帧噪声和面部区域掩码来生成视频。该框架还融合了两种注意机制和时间模块,以确保视频中角色身份的一致性和动作的自然流畅。
这个过程相当于,AI先看一下照片,然后打开声音,再随着声音一张一张地画出视频中每一帧变化的图像。
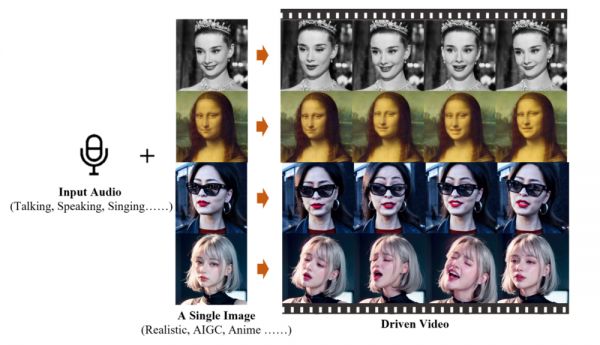
EMO的技术报告中称:实验结果表明,EMO不仅能够产生令人信服的说话视频,还能生成各种风格的歌唱视频,显著优于现有的先进方法,如DreamTalk、Wav2Lip和SadTalker,无论是在表现力还是真实感方面。
目前,研究团队认为该模型的潜在应用方向将集中在:提高数字媒体和虚拟内容生成技术水平,特别是在需要高度真实感和表现力的场景中。
然而在另一些人看来,EMO模型却很可能成为别有用心的人手中的犯罪工具。
AI生成视频日益危险
事实上,与EMO类似的多数研究,对于技术滥用的可能性讨论的都相对较少。EMO的技术报告中也没有直接提及EMO模型是否可能被用于非法用途。
然而,基于深度学习和生成模型的技术,如EMO,确实存在被滥用的风险,例如生成虚假内容、侵犯隐私或个人形象权等。
生成式AI技术的快速发展,在刺激全社会正向发展的同时也给很多黑色、灰色产业提供了新技术。
LLaMA等开源大语言模型刚刚兴起时,就有一些不法分子利用AI生成诈骗脚本。某互联网金融机构专家告诉虎嗅,AI生成的诈骗脚本内容更多变,在一定程度上增加了利用技术手段甄别诈骗的难度。
不过语言模型即便对于不法分子来说,也并不容易找到应用场景。DeepFake(深度伪造)的“主战场”目前仍在图片和视频生成领域。
深度伪造技术是通过AI创建或修改图片、视频和音频内容,使之看起来像是真实的,但实际上是虚构的。这种技术的高度真实性和易于获取的特点,使其应用范围广泛,但同时也带来了一系列道德和法律上的挑战。
距离今天最近的DeepFake案件就是2024年1月下旬AI合成Taylor Swift色情图片事件。这些图片在社交媒体平台4chan和X(以前称为 Twitter)上大量传播,据外媒报道,其中一篇帖子在最终被删除之前已被浏览超过4700万次。有人认为斯威夫特的影响力可能会导致关于制作深度伪造色情内容的新立法。
除了著名歌星之外,深度伪造技术也曾被应用在一些危险的政治斗争中。美国非党派倡导组织RepresentUs曾利用深度伪造技术发布广告,伪造普京和金正恩的讲话,暗指普京正在操纵美国大选。虽然这两则视频都以“这段视频不是真实的,但威胁是真实的”这样的免责声明结尾,但对于辨别能力较弱的普通民众来说,如果这样的伪造视频大规模传播,仍是有可能造成严重的后果。
虽然多数生成式AI技术开发的目的都是用于创新和教育,但其在法律方面的潜在负面影响,尤其是在侵犯个人隐私、扭曲信息真相和影响政治过程方面,需要得到社会、立法机构和技术公司的足够重视。
如何规避DeepFake风险?
目前,开发和应用此类技术时,研究者和开发者需考虑到这些潜在风险,并采取适当的措施来减轻这些风险,例如通过加入水印、制定使用准则等方式。
为了应对深度伪造视频和图像的挑战,目前已经开发了很多技术和法律手段,来识别伪造内容,并限制技术使用范围,包括加水印,制定严格的使用准则等方式。
Nature在2023年5月刊登的一篇论文中,介绍了一种通过机器学习(ML)和深度学习(DL)技术来检测和分类深度伪造图像的方法。这个框架利用预处理方法找到错误级别分析(ELA),然后使用深度CNN架构提取深层特征,这些特征随后通过SVM和KNN进行分类,准确率达到了89.5%。
MIT Media Lab也在积极研究相关项目,一项名为Detect DeepFakes的项目,可以通过识别AI生成的错误信息的微妙迹象来对抗误导信息。该项目组认为,深度伪造视频有一些细微的标志,比如面部的不自然平滑或阴影位置不正确等,可以帮助人们识别出深度伪造内容。
很多科技巨头也针对DeepFake推出了一些检测技术。Intel就研发了一款名为FakeCatcher的实时深度伪造检测器,该技术可以在毫秒级返回结果,准确率高达96%。FakeCatcher通过评估视频像素中的微妙“血流”变化来寻找真实视频的线索,然后使用深度学习即时检测视频是真实还是伪造。
Google的Assembler实验平台,则可以帮助记者和事实核查员快速验证图像。虽然Assembler是一个积极的步骤,但它不涵盖视频的许多其他现有操纵技术,技术解决方案本身并不足以解决数字伪造的所有挑战。
此外,也有一些专门的机构在提供这方面的服务。Sentinel是一家基于AI的保护平台,用户可以通过其网站或API上传数字媒体,系统将自动分析媒体是否为AI伪造,并提供操纵的可视化表示。
然而,道高一尺魔高一丈。生成式AI技术的快速发展,或许很快就会使这些检测技术和工具中的一部分失效。
例如EMO模型,即使在缺乏明显线索的情况下,也能创建出逼真的视频。另一方面,如果视频内容的复杂性过高,或视频质量过低,也可能会大大影响检测工具的准确性。
EMO技术报告解读
EMO模型的训练数据集使用了超过250小时的视频和超过1.5亿张图像。这个数据集包含了广泛的内容,包括演讲、电影和电视剪辑以及歌唱表演,涵盖了多种语言,如中文和英文。这确保了训练材料能够捕捉到人类表达和声音风格的广泛光谱。
在模型架构方面,EMO采用了与Stable Diffusion相似的UNet结构,其中包含了用于视频帧生成的时间模块。
训练分为三个阶段,图像预训练、视频训练和速度层训练。在图像预训练阶段,网络以单帧图像为输入进行训练。在视频训练阶段,引入时间模块和音频层,处理连续帧。速度层训练专注于调整角色头部的移动速度和频率。
使用了大约250小时的talking head视频,来自互联网和HDTF以及VFHQ数据集,VFHQ数据集在第一阶段训练时使用,因为它不包含音频。
视频剪辑被重置和裁剪到512×512的分辨率。在第一训练阶段,批处理大小设置为48。在第二和第三训练阶段,生成视频长度设置为f=12,运动帧数设置为n=4,训练的批处理大小为4。
学习率在所有阶段均设置为1e-5。在推理时,使用DDIM的采样算法生成视频剪辑,为每一帧生成指定一个恒定的速度值。生成一批(f=12帧)的时间大约为15秒。
这些详细信息提供了对EMO模型训练和其参数配置的深入了解,突显了其在处理广泛和多样化数据集方面的能力,以及其在生成富有表现力和逼真肖像视频方面的先进性能。
EMO模型有如下特点:
直接音频到视频合成:EMO采用直接从音频合成视频的方法,无需中间的3D模型或面部标志,简化了生成过程,同时保持了高度的表现力和自然性。
无缝帧过渡与身份保持:该方法确保视频帧之间的无缝过渡和视频中身份的一致性,生成的动画既生动又逼真。
表达力与真实性:实验结果显示,EMO不仅能生成令人信服的说话视频,而且还能生成各种风格的歌唱视频,其表现力和真实性显著超过现有的先进方法。
灵活的视频时长生成:EMO可以根据输入音频的长度生成任意时长的视频,提供了极大的灵活性。
面向表情的视频生成:EMO专注于通过音频提示生成表情丰富的肖像视频,特别是在处理说话和唱歌场景时,可以捕捉到复杂的面部表情和头部姿态变化。
这些特点共同构成了EMO模型的核心竞争力,使其在动态肖像视频生成领域表现出色。
EMO模型的工作原理
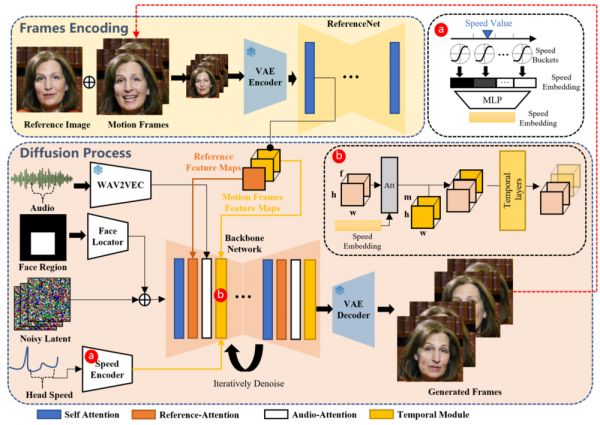
预训练音频编码器:EMO使用预训练的音频编码器(如wav2vec)来处理输入音频。这些编码器提取音频特征,这些特征随后用于驱动视频中的角色动作,包括口型和面部表情。
参考网络(ReferenceNet):该网络从单个参考图像中提取特征,这些特征在视频生成过程中用于保持角色的身份一致性。ReferenceNet与生成网络(Backbone Network)并行工作,输入参考图像以获取参考特征。
骨干网络(Backbone Network):Backbone Network接收多帧噪声(来自参考图像和音频特征的结合)并尝试将其去噪为连续的视频帧。这个网络采用了类似于Stable Diffusion的UNet结构,其中包含了用于维持生成帧之间连续性的时间模块。
注意力机制:EMO利用两种形式的注意力机制——参考注意力(Reference-Attention)和音频注意力(Audio-Attention)。参考注意力用于保持角色身份的一致性,而音频注意力则用于调整角色的动作,使之与音频信号相匹配。
时间模块:这些模块用于操纵时间维度并调整动作速度,以生成流畅且连贯的视频序列。时间模块通过自注意力层跨帧捕获动态内容,有效地在不同的视频片段之间维持一致性。
训练策略:EMO的训练分为三个阶段:图像预训练、视频训练和速度层训练。在图像预训练阶段,Backbone Network和ReferenceNet在单帧上进行训练,而在视频训练阶段,引入时间模块和音频层,处理连续帧。速度层的训练在最后阶段进行,以细化角色头部的移动速度和频率。
去噪过程:在生成过程中,Backbone Network尝试去除多帧噪声,生成连续的视频帧。去噪过程中,参考特征和音频特征被结合使用,以生成高度真实和表情丰富的视频内容。
EMO模型通过这种结合使用参考图像、音频信号、和时间信息的方法,能够生成与输入音频同步且在表情和头部姿势上富有表现力的肖像视频,超越了传统技术的限制,创造出更加自然和逼真的动画效果。
相关推荐
阿里EMO模型,一张照片就能造谣
华为新研究:一张贴纸就能破解 Face ID ?
用一张照片解开人脸识别,零售场景人脸识别将被整顿
阿里海康成立HR联盟,将共享员工隐私?钉钉:造谣
一张照片攻破人脸识别系统:能点头摇头张嘴,网友:太可怕
一张照片搜出你的所有信息,有多少人在用你的脸换钱?
百度文心一言App将可生成“数字分身”:一张图、三句话就能创建
造谣救得了中国足球吗?
135亿获得阿里妈妈医疗健康独家经营权,阿里健康拿到一张“好牌”
手机拍出单反照片,苏黎世理工单个深度卷积模型取代ISP
网址: 阿里EMO模型,一张照片就能造谣 http://www.xishuta.com/newsview110030.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95175
- 2人类唯一的出路:变成人工智能 20854
- 3报告:抖音海外版下载量突破1 20736
- 4移动办公如何高效?谷歌研究了 20025
- 5人类唯一的出路: 变成人工智 19999
- 62023年起,银行存取款迎来 10307
- 7网传比亚迪一员工泄露华为机密 8449
- 8五一来了,大数据杀熟又想来, 8311
- 9滴滴出行被投诉价格操纵,网约 7930
- 10顶风作案?金山WPS被指套娃 7210



