AI竞赛没有意义:模型根本没用,冠军全凭运气?
编者按:本文来自微信公众号“AI前线”(ID:ai-front),作者Luke Oakden-Rayner,译者 姚佳灵,编辑 陈思,36氪经授权发布。
AI 前线导读:Luke Oakden-Rayner 又来了~ 熟悉他的读者应该记得,2018 年的时候,他曾经写过一篇 《人工智能医疗安全:我们有麻烦了!》,以此来表达他个人对 AI 医疗安全的担忧,作为一名放射科医生,他十分关注医疗与计算机科学等未来技术的交汇。
近日,他开始研究人工智能竞赛对实际应用产生的影响,当然还是在他个人比较熟悉的医疗领域,他认为:AI 竞赛无法产生有用的模型,甚至不仅仅在医疗领域。先别急着反驳或者赞同,来品一品 Luke 的这篇文章再做评价也不迟。
今天(9 月 19 日),一个庞大的新 CT 脑部数据集被公布于众,目标是训练模型以检测颅内出血。到目前为止,看起来都不错,尽管我还没有深入研究细节(而魔鬼常在细节中)。
该数据集被公布于众是为了一场竞赛,这显然引发了在推特上通常是友好的竞争:
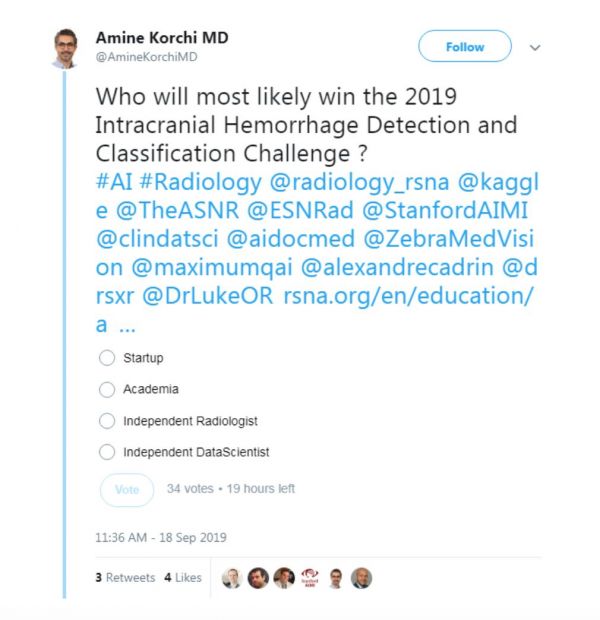
当然,这也引来了怀疑论者的冷嘲热讽。
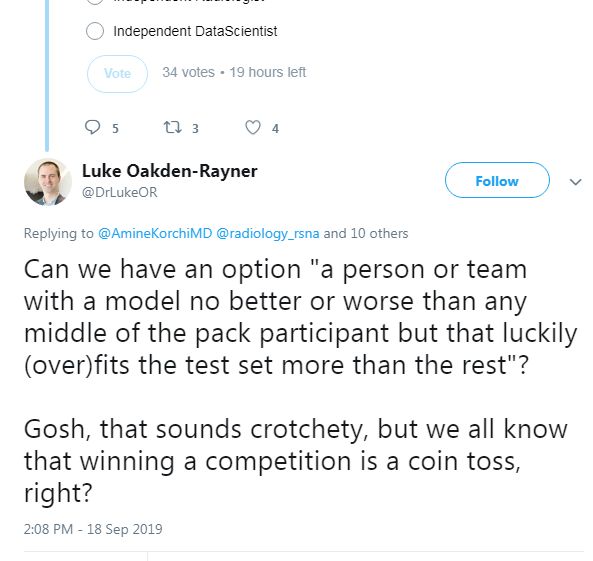
然后,讨论持续进行着,讨论的范围很广,从“但是,由于有一个留出法(hold out)测试集,怎么会过拟合呢?”到“从未打算直接应用提出的解决方案”(后者是上次比赛的冠军提到的)。
随着讨论的进行,我意识到,尽管我们“都知道”比赛结果从临床意义上讲是非常可疑的,但是,我从没有真正看到一个令人信服的解释,来解释为什么会这样。
我希望本文能够解释竞赛为什么不是真正关于构建有用的 AI 系统。
免责声明: 我写本文的初衷是供我的忠实读者阅读,他们了解我在一系列问题上的一般立场。但是,它在推特和 HackerNews 上传播得很广,而且,很显然,我没有为大量的陈述提供足够的上下文。我打算写个续篇来澄清几件事情,但是,这里是对几个常见批评的快速回复:
我不认为 AlexNet 是个比 ResNet 好的模型。这个立场是荒谬的,尤其是考虑到我所有发表的作品都是使用 resnets 和 densenets,而不是 AlexNets。
我认为,这个误解来自于我没有定义我用到的术语:一个“有用的”模型应该是能够胜任它受过训练的任务的模型。它不是模型架构。如果在竞赛过程中开发的架构广泛有用,那么,它是一个好的架构,但是,提交给竞赛的特定实现不一定是有用的模型。
本文中的统计数据是错误的,但是,它们注定在正确方向上出错了。它们的目的是说明基于人群的过拟合概念,而不是准确性。更好的方法几乎都需要在公开排行榜上没有的信息。我可能在某个时间点更新这些统计数据,以便让它们更准确,但是,它们永远都不会完美。
我在本文中尝试了一些新东西,那是对一个推特讨论的回应,因此,我想看看,我是否能在一天内写下来,以使其与时同进。考虑到我通常的流程是,每篇帖子要写上几个星期及多次重写,这有点冒险。但我认为,这个帖子仍然能达到其目的,但是,我个人认为不值得冒险。如果我再花上 1 天或 2 天,那么,我怀疑,我会在发布前就了解其中的大部分问题。我承认我错了。
让我们来干上一仗吧!
那么,什么是医学 AI 领域中的竞争呢?这里有几个选项:
让团队尝试解决一个临床问题
让团队探索一下如何解决问题,并尝试新颖的解决方案
让团队构建一个在竞争测试集上表现最佳的模型
浪费时间
现在,我没有那么烦恼,直接跳到最后一个选项(值得花时间在什么上是个观点问题,而临床效用只是一个考虑因素。更多相关内容在本文的最后)。
但是,前面那三个选项呢?这些模型适用于临床任务吗?它们是否带来广泛应用的解决方案和新颖性?或者,它们只是竞赛中表现出色,而在现实中表现平平呢?
(剧透:我将讨论后者)。
好模型和坏模型
我们是否应该期望本次竞赛会产生好的模型呢?我们来看看其中一个组织者所说的话。
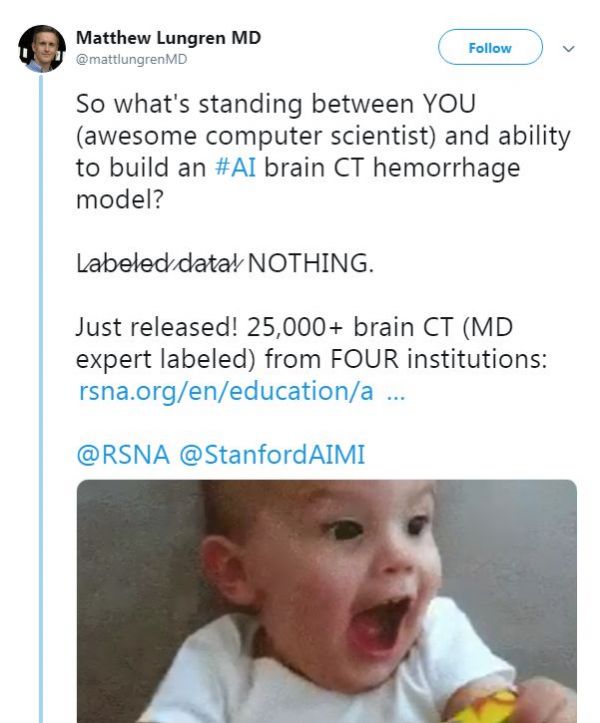
这很酷。我完全同意,缺乏大型的、标记良好的数据集是构建有用临床 AI 的最大障碍,因此,数据库应该有所帮助。
但是,说到这个数据集可以有用和本次竞赛将产生好的模型可不是一回事。
因此,为了定义我们的术语,比如说,一个 好的模型 是能够在不可见数据(该模型不了解的情况下)上检测到脑出血的模型。
因此,反过来说,一个 坏的模型 就是在不可见数据上没有检测到脑出血的模型。
这些定义将不会有争议。Machine Learning 101(以下简称 ML101)。我确信,竞赛组织者同意这些定义,并且更喜欢参赛者产生好模型而不是坏的模型。事实上,他们已经明确组织了旨在推广好模型的竞赛。
这是不够的。
Epi vs ML,开打!
ML101(现在拟人化了)告诉我们,控制过拟合的方式是使用一个留出法测试集,这是在模型训练过程中没有见过的数据。这模拟了在临床环境中看到新病患的情形。
ML101 还说,留出法的数据只能用于一次测试。如果我们测试多个模型,那么,就算我们在开发过程中没有作弊或泄露测试信息,我们的最佳结果也可能是一个异常值,只比偶然得到的最坏结果好一点。
因此,如今的竞赛组织者提供若干留出法测试集,只让每支参赛团队在这些数据上运行其模型一次。ML101 认为问题解决了。获胜者只测试一次,因此,没有理由认为它们是异常值,他们只是有最好的模型。
别急,伙计,我们来看看 Epidemiology 101,它声称自己有一枚神奇的硬币。
Epi101 告诉我们掷这个硬币 10 次。如果我们得到正面的次数达到或超过 8 次,那么,就证明这个硬币很神奇(尽管这个断言显然是胡说八道,但是,我们还是可以继续玩,因为我们知道,10 次中得到 8 次正面相当于对于一个均匀硬币来说 p 值小于 0.05,所以,它一定是合法的)。
在我们不知道的情况下,Epi101 跟其他 99 个人做了同样的事,所有这些人都认为自己是唯一测试这个硬币的人。那么,我们该期望发生什么事情呢?
如果这枚硬币完全正常,一点都不神奇,那么,大概有 5 个人会发现这枚硬币很特别。看起来很明显,但是,请考虑个体的情况。这 5 个人都只进行了一次测试。根据他们的说法,他们有统计学上显著的证据,表明他们拥有一枚“神奇的”硬币。
现在假设我们没有在掷硬币。想象一下,我们都在一个竞赛测试集上运行一个模型。与其想象我们的硬币是否是神奇的,不如希望我们的模型是最好的,可以为我们赚到 25000 美元。
当然,我们只能提交一个模型。否则那将是作弊。模型的其中之一可能表现良好,相当于抛掷一枚均匀的硬币 10 次而得到 8 次正面朝上的结果,只是偶然罢了。
好事情是,规则不允许提交多个模型,不然其他 99 个参赛者及他们的 99 个模型中的任何一个都可以靠运气得奖了……
多重假设检验
我们看到的用 Epi101 的硬币测试效果当然适用于我们的竞赛。由于随机的机会,某些百分比的模型会比其他的表现出色,即便它们都是一样好的。数学不关心测试 100 个模型的是 1 支团队还是 100 支团队。
即使某些模型在某种意义 ^ 上比其他的好,除非我们真的认为获胜者具有 ML 巫师(ML-wizard)的独特能力,否则我们必须接受至少其他一些参赛者也会取得类似的结果,因此,获胜者只是因为运气好才赢的。真正的“最佳表现”将排在后面,可能高于平均水平,但排在获胜者之后 ^^。
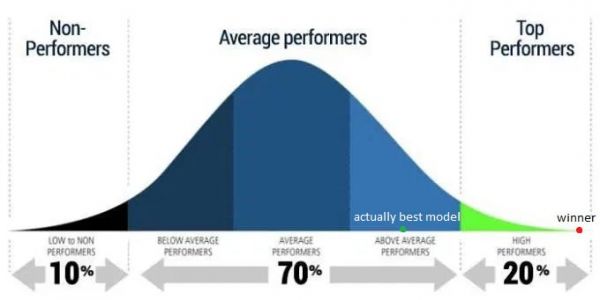
Epi101 表示,这种效应称为多重假设检验。如果在一场比赛中,我们有很多假设,每个参赛者比其他参赛者都好。那么,对于 100 个参赛者来说,就有 100 种假设。
单独来讲,这些假设的其中之一可能表示,我们有个具有统计学意义的获胜者(p<0.05)。但是,综合来看,即使获胜者有个计算出来的“获胜”p 值小于 0.05,那也不意味着,我们只有 5% 的机会来做出不合理的决定。事实上,如果是掷硬币(容易计算,但毫不奇怪),我们可以有个大于 99% 的机会让一个或多个人“获胜”并获得 8 次正面朝上的结果!
这就是 AI 竞赛的获胜者,在掷硬币的时候刚好得到了 8 次正面朝上的结果。
有趣的是,尽管 ML101 很清楚,我们自己运行 100 个模型,并选出最好的,将导致过拟合,他们很少讨论这个“过拟合的人群”。很奇怪,当我们考虑到几乎所有的 ML 研究都是用严重过度测试的公开数据集完成时……
那么,我们怎样应对多重假设检验?这都归结到产生问题的根本原因,也即数据。Epi101 告诉我们,任何测试集都是目标人群的一个有偏差的版本。在这种情况下,目标人群是“有 CT 脑部图像,具有或不具有颅内出血的所有病患”。我们来看看这种偏见是如何产生,采用的是一个小型假设人群的小样本:
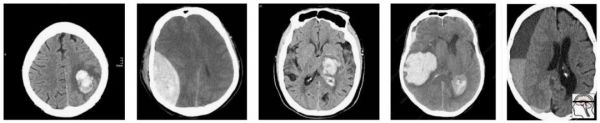
在这群人中,我们有很合理的“临床”病例组合。3 例脑内出血(可能与高血压或中风有关),2 例创伤性出血(右侧的是硬膜下出血,左侧的是硬膜外出血)。
现在,我们对这群人取样,构建我们的测试集:
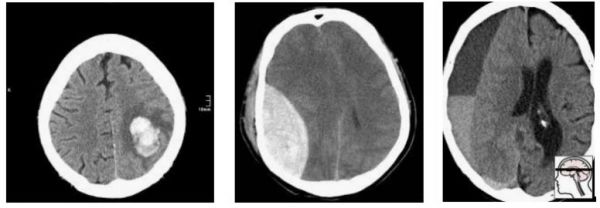
随机的,最终我们得到了轴外(在大脑外部)出血。在这个测试集上表现良好的模型不一定在实际病患那里表现良好。事实上,我们可以预计,在轴外出血上表现很好的模型以脑内出血为代价而获胜。
但是,Epi101 不仅仅是指出问题,它还有解决方案。
如此强大
要有一个没有偏差的测试集,只有一种方法,就是包括全部人!然后,无论什么模型,在测试中表现良好的也将是实践中最好的,因为我们在所有可能的未来病患身上做了测试(看起来很难)。
这导致了一个非常简单的想法,即随着测试集变得更大,我们的测试结果会变得更可靠。实际上,我们可以通过指数计算来预测测试集的可靠性。
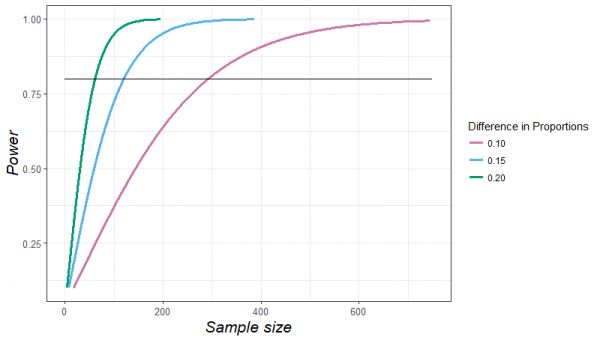
这是指数曲线。如果我们有个关于我们的“获胜”模型比次优模型好多少的大概想法,那么,我们可以估计我们需要多少测试病例,以便可靠地表明它更好。
因此,要表明我们的模型比竞争对手的好 10%,我们就需要大约 300 个测试病例。我们还可以看到,随着模型之间的差异变得越来越小,所需的病例数量如何呈指数级增长。
让我们付诸实践吧。如果我们看下另一个医学 AI 竞赛,SIIM-ACR 气胸分割挑战赛,我们可以看到,在排行榜的前几名之间,Dice 得分(范围在 0 到 1 之间)的差异可以忽略不计。请记得,这个竞赛用到的数据集有 3200 个病例(这很慷慨,但是,它们对 Dice 得分的贡献并不均等)。
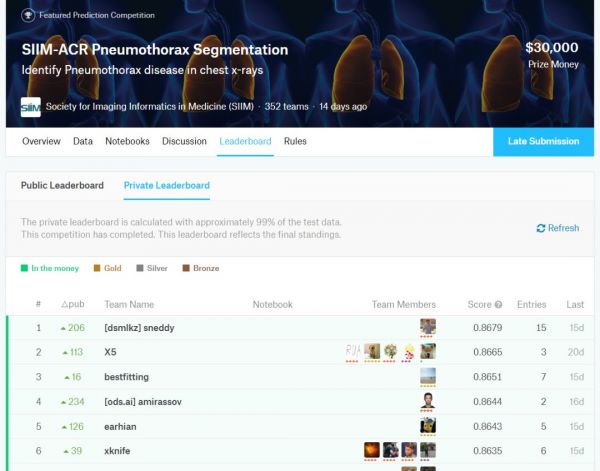
因此,在前两名之间的差异是 0.0014……让我们将它放入样本容量计算器中。
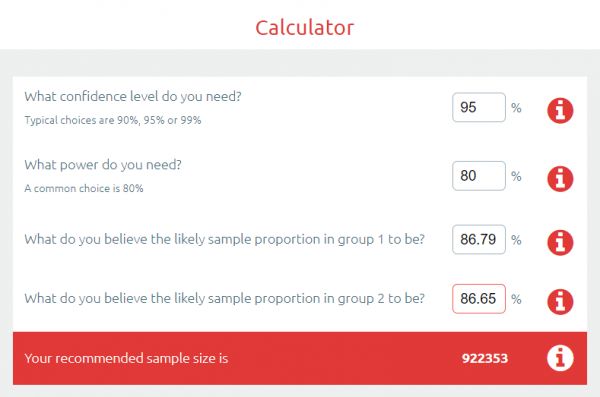
好了,为了在这两个结果中显示显著的差异,我们需要 92 万个病例。
但是,为什么止步于此呢?我们甚至还没有讨论多重假设检验呢。仅在只有一个假设,意味着 只有两个参赛者的情况下,就需要这么荒谬的数量的病例。
如果我们看看排行榜,那里有 351 支参赛团队。规则表示,他们可以提交两个模型,因此,我们最好假设至少有 500 个测试模型。这就必定产生异常值,就像 500 个人在那里掷均匀硬币一样。
Epi101 来救场啦。多重假设检验在医学上确实很常见,尤其是在基因组学等“大数据”领域。我们已经用了几十年学习如何处理这些问题。解决这类问题最简单可靠的方法被称为 Bonferroni 校正 ^^。
Bonferroni 校正特别简单:将 p 值除以测试次数就得到“统计显著性阈值”,该阈值已经针对所有额外的硬币投掷进行了调整。因此,在这种情况下,我们计算 0.5/500 的值。新的 p 值目标是 0.0001,任何比这个差的值将被认为是支持零假设(即竞争对手在测试集上的表现同样出色)。我们把这个值放入我们的指数计数器。
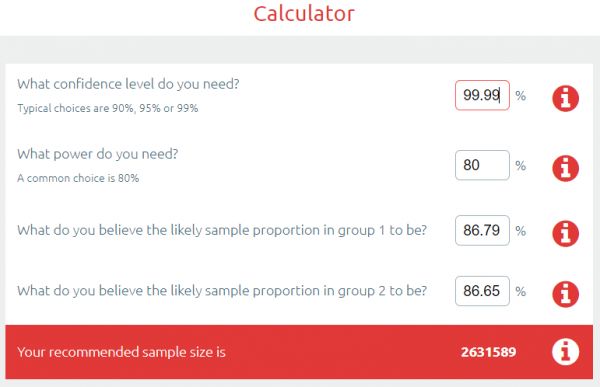
很棒!只提高了一点点……要得到一个有效的结果,需要 260 万个病例:P
现在,你可能会说,我很不公平,在排行榜上的前几名中一定有一些有好模型的小团队,彼此之间没有明显的不同 ^^^。好吧,大方一点。如果我把第 1 名和第 150 名的模型进行比较的话,肯定没有人会抱怨,对吧?
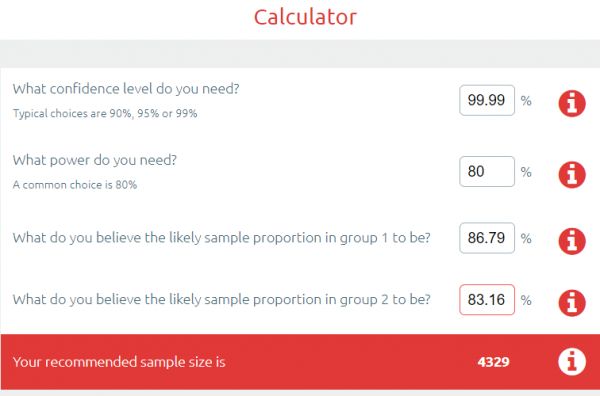
仍然比我们拥有的数据还要多。事实上,我必须降低到第 192 名位置,以找到这样一个结果,即样本大小要足够产生一个“统计学上显著的”差异。
但是,这可能是特定于气胸挑战比赛?其他比赛会是什么情况?
在 MURA,有个 207 张 X 光图像的测试集,70 支队伍每个月最多提交 2 个模型,让我们大方点,就说提交了 100 个模型吧。从数字上看,“排名第一的”模型只比排名第 56 及以下的模型有显著的差异。
在 RSNA 肺炎检测挑战赛 中,有 3000 张测试图像,350 支团队各提交 1 个模型。排名第一的只与排名第 30 及以下的模型有显著差异。
这真正地造成轩然大波了,医学以外的领域呢?
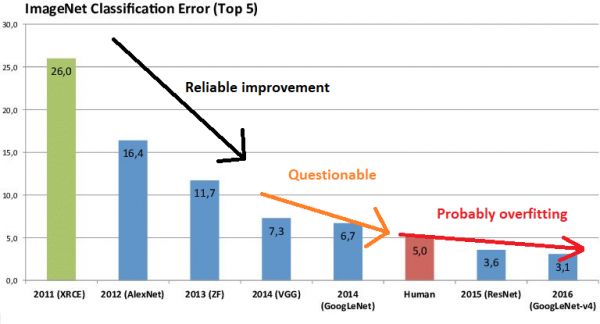
当我们从左到右地仔细查看 ImageNet 的结果时,发现每年的改进变慢了(有效的范围减小了),而在数据集上进行测试的人数增加了。我无法真正估算出数字,但是,知道我们对多重测试的了解后,还有人真的相信 SOTA 赶在 2010 年中期,只是众包过拟合吗?
那么,比赛的目的是什么?
显然,他们不能可靠地找到最佳模型。他们甚至没有真正揭示有用的技术以构建出色的模型,因为我们不知道,在上百个模型中,哪个实际上使用了一个良好、可靠的方式,哪个模式只是刚好适合动力不足的测试集。
当我们和竞赛组织者提起的时候……他们大多说,竞赛是为了宣传。我想,这就足够了。
AI 竞赛是有趣的,可以建设社区、搜寻人才、推广品牌和吸引注意力。
但是,AI 竞赛无法产生有用的模型。
备注:
^ 我们实际上可以用硬币类比来理解模型的性能。改进模型相当于把硬币弄弯。如果我们善于把硬币弄弯,那么,这样做会让它更有可能落下来的时候正面朝上,但是,除非是 100% 的可能性,否则,我们还是无法保证“赢”。如果我们有枚正面朝上的概率为 60% 的硬币,而其他人的概率是 50%,那么,从客观上来看,我们有最好的硬币,但是,在 10 次投掷中,结果为 8 次正面朝上的概率仍然只有 17%。比该领域中其他模型拥有的 5% 要好,但是,请记住,他们有 99 个。他们当中某个人获得 8 次面朝上的累积机会超过 99%。
^^ 人们总是说,Bonferroni 校正有点保守,但是,请记住,我们对这些模型之间是否真的不同表示怀疑。我们应该保守一点。
^^^ 请注意,这里排名第一的模型获得 3 万美元的奖金,而第二名就什么也得不到。竞赛组织者觉得这样区分是合理的。
原文链接:
https://lukeoakdenrayner.wordpress.com/2019/09/19/ai-competitions-dont-produce-useful-models/
相关推荐
AI竞赛没有意义:模型根本没用,冠军全凭运气?
中国军团称霸阅读理解竞赛RACE:微信AI称王,高中生单枪匹马力压腾讯康奈尔联队
Facebook在美上线相亲功能,微软AI成为麻将冠军!| 一周热闻回顾
陆奇最新演讲:没有学习能力,看再多世界也没用
一场机器人竞赛背后,优必选科技逐渐浮现的教育大版图
AI:我又又又打败了人类冠军!小学生:叫爸爸!
AI赌神超进化:德扑六人局击溃世界冠军
AI战「疫」:百度开源业界首个口罩人脸检测及分类模型
人类彻底失守!OpenAI 2:0横扫冠军战队OG
第三代AI赌神:在六人桌德扑中胜过5个人类顶尖高手
网址: AI竞赛没有意义:模型根本没用,冠军全凭运气? http://www.xishuta.com/newsview11054.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95178
- 2人类唯一的出路:变成人工智能 20885
- 3报告:抖音海外版下载量突破1 20771
- 4移动办公如何高效?谷歌研究了 20054
- 5人类唯一的出路: 变成人工智 20036
- 62023年起,银行存取款迎来 10307
- 7网传比亚迪一员工泄露华为机密 8456
- 8五一来了,大数据杀熟又想来, 8338
- 9滴滴出行被投诉价格操纵,网约 7960
- 10顶风作案?金山WPS被指套娃 7213



