“你打篮球像蔡徐坤”:微信翻译这个bug是怎么回事?
(原标题:“你打篮球像蔡徐坤”:微信翻译这个bug是怎么回事?)
为了微信的一个bug,蔡徐坤的粉丝们差点跟腾讯势不两立。
上周末,一组微信“神翻译”的截图,在微博、知乎、豆瓣和虎扑等社交网络上传开。有人输入诸如 "you play basketball like caixukun" 等句子,用微信自带的翻译功能,得到的却是含义完全错误的译文:

其他遭殃被一起拿来调戏微信翻译的男星,还有吴亦凡、谢广坤等。
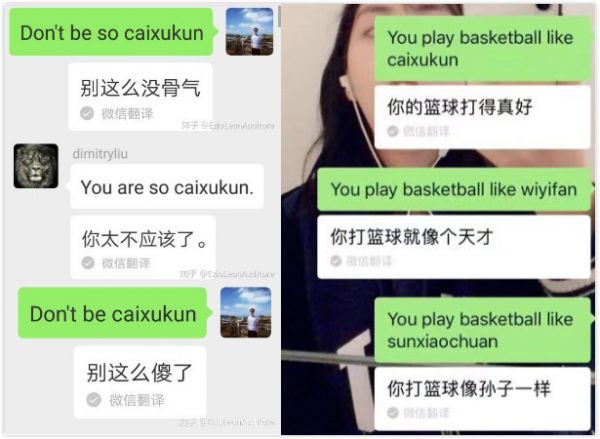

蔡徐坤是目前中国娱乐界流量第一的明星,粉丝肯定不好惹。

微信团队目前已经部分下线了翻译功能。根据硅星人实测,类似"you are so" 的句式,以及涉及"caixukun"等词的语句,现在已经无法翻译到中文了。
与此同时,官方账号@腾讯微信团队也在微博上宣布,翻译功能目前正在紧急修复中。截至发稿,相关语句仍然无法被微信正常翻译。
注意,微信官方提供了一小段解释:
翻译引擎在翻译一些没有进行过训练的非正式英文词汇时出现误翻,导致部分语句翻译出现问题。
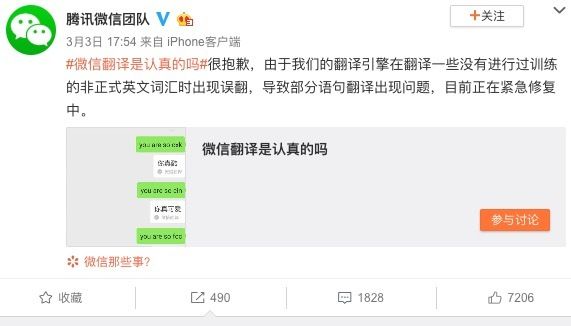
在"caixukun"后,又有网友发现了更多会触发bug的词。比如,微信翻译似乎在大学英文简称上表现比较差劲。输入"your school is WHU",翻不出武汉大学,却给出了“你的学校很烂”的结果。
没过多久,涉及大学英文简称的字句也翻译不出来了。
硅星人认为,微信应该进一步、更加详细地告知我们:这个 bug为什么会出现,由哪些因素所导致。
一方面,微信翻译背后的技术确实比较复杂。解释它,有助于用户去理解它的工作原理,明白这个翻译结果的背后,可能有着十分复杂的技术原因。
另一方面,你关掉了"you are so"句式,还会出现学校简称;关了学校简称,还会有更多会触发 bug 的词被发现。发现一次关一次?这样伤害的是正常使用翻译功能用户的体验,长此以往总不是办法。
遗憾的是,微信方面表示,以上面微博为准,不再更多置评(或许是因为不想继续惹恼蔡徐坤的粉丝吧。)同时,中文互联网上完全找不到针对此事靠谱的技术解答,即便在知乎上,相关主题下面也都是用户在分享自己发现的 bug 截图,没有人解释原因。
既然这样,不妨让硅星人来试试?
我们采访了多位机器学习专家,并在接下来的篇幅里1)解释微信翻译用的到底是什么技术;2)再尝试回答"you play basketball like caixukun" 这句话,为什么在微信翻译里被翻错了。

微信翻译用的是什么技术?
硅星人经过多方面了解,确信微信英汉互译系统采用的是目前机器学习领域比较火的“神经机器翻译”(Neural Machine Translation, 简称? NMT) 技术,由微信 AI 团队自研。
从外行人的角度来看,NMT 在翻译一句话时,做了这些事情:
Step 1: 在一定程度上模仿人脑的思维方式,NMT 根据一个单词在整个句子(可以是长句)当中的语境,为这个单词建立一个神经网络的模型,形成一个语义表示。比如单词是英语的 dog,可以理解为 NMT 在它的“大脑”里形成了一条狗的印象。
Step 2: 按照在句子甚至段落中的语境,将模型重新转化成另一种语言。比如 dog 翻译成法语就是 “le chien”;但如果语境是“一条狗生下了小狗”,那么 dog 就会被翻译成阴性的"la chienne"。

(NMT 不是真的在大脑中形成狗的视觉印象,事实上整个过程跟图像完全没有任何关系。这个所谓的“印象”,通过一连串向量 (vector) 表示。狗的例子来自于 Microsoft Translator)
NMT 的主要优势是对长句子(甚至段落)有着不俗的翻译能力,阅读起来上下文连贯程度接近人翻。问世之后,NMT?也逐渐被微软、Google、百度、腾讯等大公司的翻译产品所采用。
“机翻技术一直在不断迭代更新,以前基于规则,过去十年主要基于统计,现在我们开始用神经网络。神经机器翻译是目前机器翻译上比较火的一项技术。我们绝大多数的大语种翻译已经基于这个技术了,“在美国一家顶级科技公司的研究分支担任资深研究员的王夏*告诉硅星人。
“在机翻技术发展的每个阶段,科研人员都会遇到一些问题。NMT 也存在一些问题,比如整个过程的可解释性是非常低的,”他说。
硅星人翻译一下这句话的意思:在具体案例的层面上,一个 NMT 的系统为什么会把一句话 ABCDE 翻译成 abcde,研究者目前是很难将翻译过程解释清楚的。

这句话为什么被翻错了?
当 NMT 翻错了的时候,可能发生了哪些情况?
其实错没错、错误严重不严重,都是人来决定的。在机器眼里没有对错,选定的答案就是机器认为概率最高或最有可能的那个答案,因为一切都按照模型、算法运转着。
接受这一点,你才能理解这句话为什么翻错。
接下来进入正题?
可能原因1:训练集噪音
在接受硅星人采访的多位机器学习专家当中,大部分人都给这条原因投了票。
形象一点比喻,噪音 (noise)?就是训练翻译系统的数据集里出现的”不正确“的,“脏”的数据。
训练一个优秀的 NMT 系统,需要大量高质量的平行语料数据——”高质量“指的是准确的翻译,”平行语料“指的是一句英文一句中文的,”I love you = 我爱你“,等等。
这些数据要去哪里找?英汉辞典是一个来源。除此之外,最流行的做法是去互联网上抓取,从全网大量的数据里,抓取到所需要的高质量平行语料。
"you play basketball like caixukun" 被翻译成了”你的篮球打得真好“,噪音是哪来的?硅星人发现有两种可能性:
比如,网上已经存在了大量”caixukun=好“的语料。这些语料在爬取中被微信翻译当成了平行语料并采用了。但是实际上,这属于”噪音“,因为在翻译的语境下建立不了相关性,没办法确保是准确的。微信 AI 可能在以后加强类似领域的去噪音。创办了一家机器学习公司的韩辰*指出:在训练中,微信翻译团队人员可能使用生成对抗攻击 (generative adversarial attack) 的方式,做了类似手动加入噪音,在训练过程中主动对类似的翻译结果进行纠错的操作,最终干扰了翻译结果——这是一种可能发生的情况,我们并不揣测动机。
用噪音干扰计算机视觉图像识别的示例:人类无法辨认的图片,被深度神经网络识别为不同的物体。示例与本文主题无关,仅作参考。
在有噪音等异常情况存在的前提下,系统仍然能够正常训练、工作,给出高质量翻译结果——这样的能力在计算机科学里叫做“鲁棒性”(robustness)。
王夏指出,鲁棒性是 NMT 以及今后的机器翻译技术都需要改进和注意的。
可能原因2:集外词
一种可能出现的情况是,在微信翻译训练用的数据集中,压根就没有出现过"caixukun"这个词。
当 NMT 遇到集外词时,可能会进行拆解找到集内词。这个拆解的过程也是随机的,比方说它可能拆成了 caix ukun,得到的仍然是集外词。
集外词翻译不好是很正常。如果没见过,那就不会翻,出现偏差也是情理之中的。
可能原因 3:领域不匹配
”另一种可能出现的情况是领域不匹配 (domains do not match),“王夏表示,并指出这并不一定是具体案例的情况。
在这个具体案例中,句子里出现了 basketball(篮球),而微信翻译的训练数据集可能没有篮球领域的,或者跟篮球有关的非常少。一个不匹配的领域,再加上句子里还有一个集外词,共同作用使得翻译结果很难正确。
这个解释行得通。比方说商贸往来是大部分微信用户使用翻译的原因,那么微信在训练 NMT 时可能用了贸易领域的数据集;篮球不是微信翻译用户的主要场景,那么在训练时也许就没有用篮球的数据集。
如果因为集外词和领域不匹配而出了错,你也不能怪它。没学过的东西,它又怎么可能会呢?

微信 AI 的官方网站
可能原因 4:奇怪单词+无法引入常识
这个原因也是由 NMT 的工作原理导致的。
NMT 对于长句子、段落,甚至一整篇文章的翻译效果很不错。这得益于它的机制,在翻译某个词时能够贴合上下文的语境。
但是在短句上,它就不一定灵了——特别是当这个句子完全不通顺的时候。
可能因为在"you play basketball like caixukun"这句话中,caixukun 是一个非常奇怪的单词。它既没有出现在任何一本英语辞典当中,看上去跟句子的上下文也没什么关系。

微信翻译的训练,可能发生在蔡徐坤成为 NBA 中国新春贺岁大使之前
人类在翻译的时候,能够参考已有的常识、知识,翻不出来也可以去查资料。NMT 却做不到这一点,当它在工作的时候,它并不具备一个常识库可以去参考。
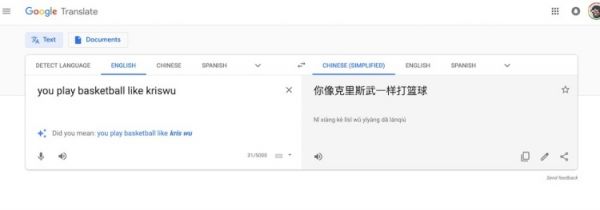
而且,这一点并不是微信做不好——现在去用同样的句子考考 Google Translate,得到的结果也不令人完全满意。
“这个(无法引入常识的)问题不仅体现在翻译任务上,还包括阅读理解、问答等任务。如何在这一点上做改进,是个很有趣的方向,大家也都还在探索,”王夏表示。
所以,微信做错了吗?
上述情况如若出现,必然会导致翻译错误,因为?NMT 就是这样工作的。就算不发生在微信上,也会发生在 Google Translate,或者任何其他一个基于 NMT 的翻译产品上。这样来看,微信产品本身没有任何过错。
但微信团队并非完全无辜的。因为除了技术上,bug 出现也有可能是流程管控上出了问题。
在一个9亿用户量级的全民级 app 里,开发任何功能都应该经过仔细的论证,上线前也应该有严格的测试,尽量确保万无一失。然而,微信的前工程师曾透露,至少在微信翻译上线时候并非如此。
当时,工程师在知乎上是这样回答的:

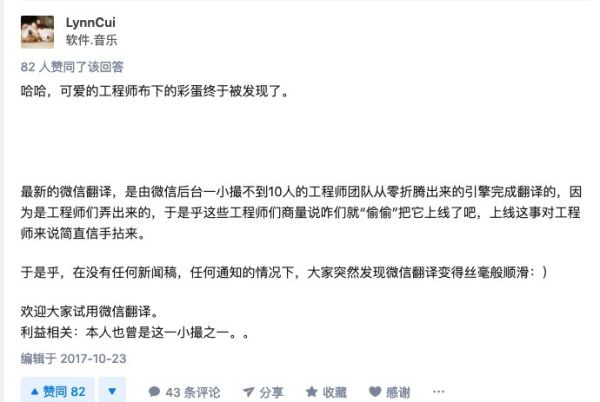
说来腾讯/微信也不是第一次出这种问题了。
去年腾讯 AI 负责博鳌亚洲论坛的同声传译,直接把一个基于 seq2seq 的机翻系统带过去了,先是把“一带一路”翻译成了“一条公路和一条腰带”和“道路和传送带”,接着又干脆抽风罢工。

“数据量大,活糙敢干。”
这是韩辰对这次微信翻译 bug 的评价。
接受硅星人采访时,一位不愿意透露姓名的蔡徐坤粉丝说,不希望看到有个别人通过技术的手段,去纵容针对艺人的网络暴力。
“艺人是无辜的,这样的翻译本身会给艺人带来负面影响。而网友的群嘲,可能对艺人带来心理上的二次伤害,“她表示,”这次微信官方的反应比较快,很赞。我希望微信是没有恶意的,也希望所有全民级 app 和社交媒体都有基本的道德底线。“
那么,

*王夏、韩辰为化名。
相关推荐
“你打篮球像蔡徐坤”:微信翻译这个bug是怎么回事?
“你打篮球像蔡徐坤”:微信翻译这个bug是怎么回事?
微信翻译闹笑话蔡徐坤躺枪,AI翻译为何总“翻车”?
惨败给周杰伦后,蔡徐坤粉丝要退出微博所有数据战
周杰伦蔡徐坤粉丝之争,最后赢家是社交平台?
星援App流量造假:蔡徐坤只是被害的出头鸟
蔡徐坤1亿转发量幕后推手“星援app”被端
最前线|B站、蔡徐坤、吴亦凡的粉丝又掐起来了,这回是因为《大碗宽面》
B站回应收到蔡徐坤律师函:相信法律自有公断
B站收到蔡徐坤律师函:因侵犯其名誉权等权利
网址: “你打篮球像蔡徐坤”:微信翻译这个bug是怎么回事? http://www.xishuta.com/newsview1121.html
推荐科技快讯






- 1问界商标转让释放信号:赛力斯 95037
- 2人类唯一的出路:变成人工智能 19948
- 3报告:抖音海外版下载量突破1 19737
- 4移动办公如何高效?谷歌研究了 19179
- 5人类唯一的出路: 变成人工智 19048
- 62023年起,银行存取款迎来 10198
- 7网传比亚迪一员工泄露华为机密 8311
- 8五一来了,大数据杀熟又想来, 7519
- 9顶风作案?金山WPS被指套娃 7143
- 10滴滴出行被投诉价格操纵,网约 7136



