OpenAI坚信“力大砖飞”,谷歌却说模型不是越大越好
近年来,模型规模呈现出愈来愈大的趋势,越来越多的人相信“力大砖飞”。
OpenAI虽然没有公布Sora的训练细节,但在Sora的技术报告中提到了:
Our largest model, Sora, is capable of generating a minute of high fidelity video. Our results suggest that scaling video generation models is a promising path towards building general purpose simulators of the physical world.(我们最大的模型Sora能够生成一分钟的高保真视频。我们的结果表明,扩展视频生成模型是构建物理世界通用模拟器的一条有前途的途径。)
OpenAI是Scaling laws的坚定拥护者。可是模型训练是否真的大力出奇迹呢?
谷歌最新的研究结论:不是!
谷歌研究院和约翰霍普金斯大学在最新的论文中指出:对于潜在扩散模型,模型不一定是越大越好。(论文链接:https://arxiv.org/abs/2404.01367)
Scaling laws争议一直存在
关于Scaling laws(中文译文:缩放定律),来自OpenAI在2020年发表的论文Scaling Laws for Neural Language Models,简单说就是:模型的效果和规模大小、数据集大小、计算量大小强相关,而与模型的具体结构(层数/深度/宽度)弱相关。(论文链接:https://arxiv.org/pdf/2001.08361.pdf)
Scaling Laws不仅适用于语言模型,还适用于其他模态以及跨模态的场景。缩放定律提出的意义是重大的,根据它研究人员和开发者可以更有效地设计模型架构,选择合适的模型大小和数据集规模,以在有限的计算资源下实现最佳性能。
关于缩放定律的研究,先前的研究主要集中在大语言模型(LLM)上,关于它的争议一直存在:
OpenAI认为[1],每增加10倍的计算量,应该让数据集大小增加为约1.8倍,模型参数量增加为约5.5倍。换句话说,模型参数量更加重要。
而DeepMind认为[2],每增加10倍的计算量,应该让数据集大小增加为约3.16倍,模型参数量也增加为约3.16倍。换句话说,数据集大小和模型参数量一样重要。
先前,关于LLM的缩放定律已经被充分研究,而谷歌的最新研究则关注图像生成模型:潜在扩散模型(Latent Diffusion Models, LDMs),从DALL·E到最近大火的Sora,我们都能看到它的影子。但是谷歌的研究结论是:
对于LDMs,在计算资源较少时,如果增加10倍的计算量,应该让数据集大小增加为10倍,而不增加模型参数量。换句话说,数据集大小更加的重要。
照这么说,Scaling Laws又失灵了吗?
小模型的生成质量更好
作者设计了11个文本生成图像的LDM,其参数量从3900万到50亿不等。如下图所示,第一行是模型参数量,第二行是其中Unet模型的第一层宽度,第三和四行分别是模型的GFLOPS(运行一次前向传播和反向传播所需的计算量)和花费(相对于原始866M模型的花费,即假设866M模型的花费为1.00)。

众所周知,模型的总计算量等于训练步骤和GFLOPS的乘积,所以在总计算量恒定的约束下,越大的模型能得到的训练步骤就越少,所以是模型大比较重要还是训练步骤多比较重要呢?
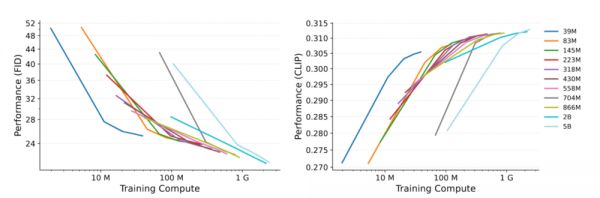
训练步骤多比较重要。在计算资源有限时,较小的模型(训练步骤多)可以胜过较大的模型(训练步骤少);模型大小以及训练步骤的选择要和计算资源适配。下面给出了一个定性的示例,可以看出小模型的效果更好一些。

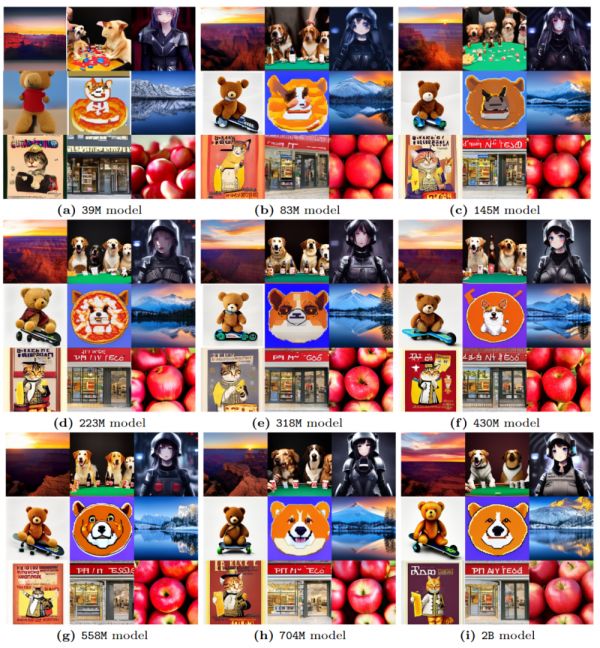
但当训练步骤恒定时,依然是模型越大越好,下面给出了一个例子:训练步骤恒为500k,不同体积模型的生成效果。
但大模型更擅长图像细节
使用前面的text2image任务作为预训练任务,分别在超分辨率任务和DreamBooth任务上做微调,发现在超分辨率任务上,相同的计算量,模型越大,FID越低(生成质量越好),而超分辨率任务最考验模型的细节生成能力。
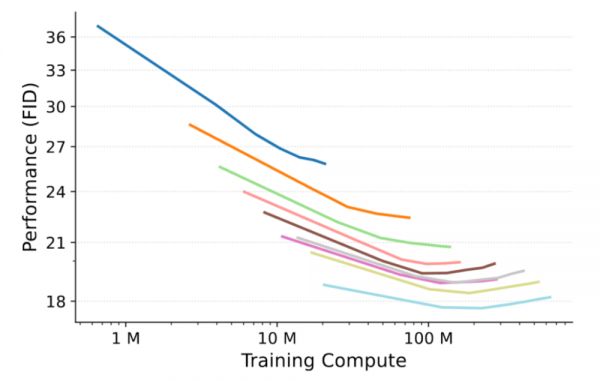
下面是一个定性的例子:

在下面DreamBooth上的表现证明了同样的结论,即大模型更擅长图像细节。

不同体积模型的CFG相关性竟然基本一致
先简单介绍一下CFG:
CFG速率(Classifier-Free Guidance Rate)是一种在扩散模型中使用的技术,在文本到图像的生成任务中,它通过调整模型在随机生成和文本条件生成之间的平衡来实现这一目标。
扩散模型在生成过程中,通常会从一个纯噪声状态开始,逐步降噪直至产生清晰的图像。在这一过程中,CFG技术引入了一个额外的“引导”步骤,通过该步骤可以更加强烈地推动生成的图像朝着给定文本描述相符合的方向发展,CFG速率定义了这种引导的强度。

具体来说,CFG修改了模型在生成过程中使用的文本信息的权重。CFG速率为0意味着完全不使用文本信息,而较高的CFG速率意味着文本信息对生成过程的影响更大。通过调整CFG速率,可以在图文相关性与图像质量之间找到最佳平衡。
下图是不同模型和采样步骤下,最优的CFG热力图:

你会发现,同一行的颜色基本是一致的,这说明不同体积的模型受CFG的影响是基本一致的,下面给出了一个定性的示例,从左到右的CFG逐渐提高。

虽然下面一行的整体质量比上面好,但是两行从左到右的整体变化趋势基本一样。甚至作者在蒸馏模型中进行同样的实验,依然能得到同样的结论。
模型效率与品质的探索
这项研究无疑将对开发更高效的图像生成AI系统产生深远影响,因为它提出了实现模型效率与质量之间最佳平衡的指导性建议。通过深入探索潜在扩散模型(LDM)的扩展特性及模型大小与性能的关系,研究人员得以精准调整,以达到效率和质量的和谐统一。
这些成果也与AI领域的最新动态相契合,比如LLaMa、Falcon等小型语言模型在多项任务中超越大型对手。这股推动开源、更小巧、更高效模型的发展势头,旨在推动AI技术的民主化,使开发者得以在不依赖庞大计算资源的情况下,于边缘设备上构建个性化的AI系统。
参考资料
[1]Kaplan J, McCandlish S, Henighan T, et al. Scaling laws for neural language models[J] arXiv preprint arXiv:2001.08361, 2020.
[2]Hoffmann J, Borgeaud S, Mensch A, et al. Training compute-optimal large language models [J] arXiv preprint arXiv:2203.15556, 2022.
本文来自微信公众号:夕小瑶科技说(ID:xixiaoyaoQAQ),作者:Zicy
相关推荐
OpenAI坚信“力大砖飞”,谷歌却说模型不是越大越好
OpenAI CEO:大语言模型规模已接近极限,并非越大越好
【PW热点】OpenAI CEO:大语言模型规模已接近极限,并非越大越好
不是大模型用不起,而是小模型更有性价比
“力大砖飞”的光刻厂到底是个啥玩意儿?
摆脱OpenAI依赖,微软组建王牌AI团队专攻“小模型”,为大模型降本增效
大厂混战大模型:四大流派,没有赢家
大模型就是做得多亏得多,连微软、谷歌也逃不过?
OpenAI忙着“宫斗”时,竞争对手发布新款大模型
谷歌营收增速乏力,没有吃到大模型第一波红利
网址: OpenAI坚信“力大砖飞”,谷歌却说模型不是越大越好 http://www.xishuta.com/newsview114590.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95042
- 2人类唯一的出路:变成人工智能 20011
- 3报告:抖音海外版下载量突破1 19799
- 4移动办公如何高效?谷歌研究了 19237
- 5人类唯一的出路: 变成人工智 19111
- 62023年起,银行存取款迎来 10206
- 7网传比亚迪一员工泄露华为机密 8318
- 8五一来了,大数据杀熟又想来, 7574
- 9滴滴出行被投诉价格操纵,网约 7192
- 10顶风作案?金山WPS被指套娃 7146



