科技巨头狂撒千亿美元 “买照片”,只为训练AI模型?

高质量的数据,越来越值钱。
你能想象,那些被遗忘在网盘的陈年老图,有朝一日能价值千金?
就在最近,路透社报道称,苹果公司正与图像托管网站Photobucket协商,希望得到这家公司近130亿张照片、视频组成的庞大图像库,并以此来训练AI模型。

苹果不是这家网站的唯一买家,其他硅谷大厂们都在寻求与之达成协议。而这些巨头们也毫不吝啬,甚至愿意掏出数十亿美元的真金白银购买这些素材。
不只是Photobucket,Reddit、Youtube等知名网站都成了科技巨头们的疯抢目标。
苹果为训练AI买图片,网友担忧隐私
Photobucket是一个提供影像寄存、视频寄存、幻灯片制作与照片分享服务网站,成立于2003年。在当时,用户把这个网站当作个人相册,与功能与现在流行的在线相册非常相似。
在巅峰期,该网站曾拥有7000万用户。而到2007年,Photobucket就声称已有超过28亿张图像上传到其网站。不过随着越来越多的功能更强大的在线相册App出现之后,这种网站式的在线相册也逐渐失去了热度。
不过毕竟是一家成立二十多年的网站,别的不说,数据是真的多,130亿张图片与视频,足够AI模型消化很久。
据悉,苹果购买的图片的主要目的就是提高生成式AI的水平。
除此之外,苹果公司在早些时候与另一家图片素材网站Shutterstock达成了数百万张图片的授权协议,据悉这笔交易的价值在2500万美元到5000万美元之间。
随着 今年6月份WWDC大会日益临近,每个人都在期待苹果公司能带来“令人惊叹”的AI功能。
但和上笔交易不同,不少网友开始为了隐私担心。有人评论表示,Photobucket的图片来源都是基于网友的“托管,这就意外着这些图片虽然已经是陈年老图,但仍属于用户的个人秘密。
而Shutterstock的数据大多是免版税的图片、矢量图和插图库,包括影片剪辑以及音乐曲目,本身就可以授权给用户使用。这么一对比,网友对于Photobucket的数据隐私安全问题也可以理解了。
除了涉及隐私以外,不少网友还对这些库存照片的质量提出了质疑。如果给AI喂食这些本来就带有错误的图片,那么是否会生成质量更低的图片呢?

总之,就苹果购买Photobucket图片的行为,大多数网友并不赞同。
但即使冒着泄露隐私的风险,苹果和其他公司们还是得“铤而走险”搞来这些数据。主要原因还是高质量的互联网数据,可能没几年就要耗尽了。
其实早在多年前,各大科技巨头就已经碰到训练语料缺失的瓶颈。
据《纽约时报》报道,OpenAI在训练GPT-4时,就曾遇到英文文本资料缺失的情况。
为了处理这个问题,OpenAI推出一款名为Whisper语音识别工具,用来转录谷歌旗下视频平台Youtube的视频音频,生成大量的对话文本。

据报道称,这款工具以开源的名义转录了超过一百万小时的Youtube视频,实际上已经违反了Youtube的隐私规则,而这些资料也成为ChatGPT的基础。
这并不是OpenAI第一次因为偷扒数据犯错。包括《纽约时报》在内,多家数字新闻媒体对OpenAI提起版权侵权诉讼,认为他们的数千篇报道被OpenAI用来训练ChatGPT。
当然,通过“爬虫”等手段搜刮训练数据的科技公司不止OpenAI这一家,“受害者”谷歌也曾通过修改服务条款的方式,将“使用公开信息训练AI模型”偷偷写进隐私细则中,从而允许工程师们利用公开的文档、在线资料等开发AI产品。
不过随着OpenAI在版权问题上越陷越深,其他科技巨头也只能乖乖掏钱为训练数据付费。
至少比起互联网上免费抓取的数据,Photobucket近130亿的数据量还是相对来说质量更高点。
花钱买数据,或许还不够
可怕的是,即便是130亿的数据量,也可能喂不饱现在的AI的模型。
研究机构Epoch直白地表示,现在科技公司使用数据的速度已经超过数据生产的速度,这些公司最快会在2026年就耗尽互联网上的高质量数据。
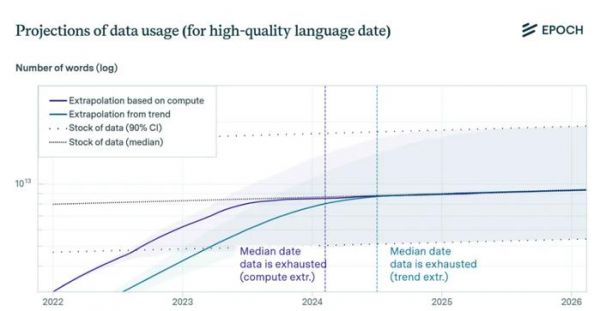
有数据统计,在2020年11月发布的GPT-3上,使用了3000亿个Token的训练数据。而到了2024年,谷歌PaLM 2的训练数据量则达到3.6万亿个Token。
数据量是一回事,数据的质量更是直接影响AI大模型的生成能力。正如网友所担忧的那样,低质量的数据甚至可能让AI陷入不可逆转的方向。
面对这样的问题,OpenAI开始尝试使用合成数据(AI生成的数据)来训练AI。这样既可以减少对受版权保护数据的依赖,同时也能训练出更强大的结果。
对此OpenAI和一系列机构开始研究使用两个不同的模型来生成更有用、更可靠的合成数据,其中一个模型用来生成数据,另一个则用来对生成的数据进行审核。
不只是OpenAI,英伟达很早就在用合成数据弥补现实世界的数据。在2021年11月,英伟达对外推出合成数据生成引擎Omniverse Replicator 。
英伟达将其描述为“用于生成具有基本事实的合成数据以训练 AI 网络的引擎”,其作用就是用来训练AI。
此产品推出后,由该引擎生成的合成数据在自动驾驶、机器人等多个场景里都得到了验证,因此英伟达也在近些年希望将其推广到更多领域,包括聊天机器人。
然而,合成数据在工业场景里的成功案例,并不代表在其他领域都能遵循物理规律。
有时候AI连真实图片都无法理解,更不要说理解二次生成的图片了。
本文作者:jh,观点仅代表个人,题图源:网络
发布于:江苏
相关推荐
科技巨头狂撒千亿美元 “买照片”,只为训练AI模型?
AI巨头们,都在用盗版书籍训练模型?
AI要被卡脖子了?训练大模型的数据或在2026年耗尽
我在AI训练库里,找到200多张周杰伦的照片
藏在AI背后的“吃电狂魔”
AI大模型“太贵”,VC投钱望而生畏
一年四单,腾讯狂买英国,只收科技明星
瞄准AI训练市场,「燧原科技」发布首款人工智能训练产品“云燧T10”
AI 降温,这家千亿巨头该何去何从?
麦当劳也在买AI创企,2019五大美国科技巨头AI收购战
网址: 科技巨头狂撒千亿美元 “买照片”,只为训练AI模型? http://www.xishuta.com/newsview114756.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95263
- 2人类唯一的出路:变成人工智能 21515
- 3报告:抖音海外版下载量突破1 21493
- 4移动办公如何高效?谷歌研究了 20661
- 5人类唯一的出路: 变成人工智 20652
- 62023年起,银行存取款迎来 10369
- 7五一来了,大数据杀熟又想来, 8890
- 8网传比亚迪一员工泄露华为机密 8561
- 9滴滴出行被投诉价格操纵,网约 8513
- 10顶风作案?金山WPS被指套娃 7255



