训练Llama3产生万吨碳排放,费电还不环保?
Meta在开源了Llama3系列两个较小参数规模的版本后,扎克伯格放出口风,已经开始准备训练Llama4了,要继续砸100亿美元甚至1000亿美元在算力基础上设施上。
小扎不差钱为自己的“星门计划”买得起数十万张GPU,但是数据中心会面临日益严峻的电力供应和二氧化碳排放问题。
Meta为训练Llama3 系列的两个数据中心电力近100兆瓦,产生了超过万吨的二氧化碳排放。今年它的AI算力集群组合,将达到1吉瓦(GW)电力规模。
大模型扩展继续生效
数据中心能源扩展,对应着大模型扩展定律。后者驱动着算力集群规模的升级,也驱动训练下一代SOTA模型的权力,逐步收敛到科技巨头手上。
从Llama2到Llama3,最大参数规模扩展了近6倍;已公布的预训练数据集规模,从2T token扩展到15T token,使得Llama3-8B的水平,与Llama2-70B基本相当。而且,Meta在训练中发现,模型性能提升仍未饱和。
Meta的AI研究超级集群(RSC)经历过至少两次大规模升级。2017年时是2.2万张V100,至2022年中是1.6万张A100,训练了Llama与Llama2;2023年初,升级为两个各超2.4万张H100的算力集群,并计划在年底建成相等于总计60万张H100算力基础设施。

Meta的超级算力集群
Llama3就是由最新的H100集群训练的。它也承担Meta其他模型的训练任务,如Reels模型、Facebook新闻推送和Instagram推送模型的训练。但当前所有的算力都已经集中到更大的4050亿参数规模的Llama3-400B+的训练中。
在英伟达B200发布后,Meta马上宣布大量采购,用于下一代大模型的训练。这将是该公司AI研究超级集群的第三次重大升级。
1GW电力的超级算力集群组合
要让如此庞大的算力集群跑起来,不仅仅需要GPU,还需要CPU、内存与各种网络连接组件。每个数据中心都会根据自己的实际应用场景选择合适的组件,并调整各自的占比与架构。
英伟达自己搭建了一个H100为中心的算力集群DGX SuperPOD,供行业参考,共用到了127个DGX H100服务器,每个服务器内含8个H100的GPU。根据它公布的组件构成,要运行这样一个算力集群,预期平均电力(EAP)达到了1.41MW。也就是在现实环境中跑起来,算力集群中的每个H100要正常工作,理论上需要均摊到1389W电力。
如果完全按这套标准来构建算力集群,那么2.4万张H100,它的关键IT电力(Critical IT Power Consumed),即保证计算正常执行的所有相关IT设备的电力,约为33兆瓦(MW)。
但要维持如此庞大的算力集群的运行,照明和冷却系统等同样重要。它们的电力占比越低,说明数据中心的电源使用效率(PUE)越高。这种关系可以通过比较数据中心的总电力与IT设备的实际电力来衡量,即:
PUE = 数据中心实际总电力 / 关键IT电力
当前,大多数 AI 数据中心的目标是PUE低于1.3。按这个标准计算,2.4万张H100的单一数据中心,在完全投入使用的过程中,整体电力将接近45兆瓦。等效60万张H100的算力基础设施的组合,整体电力超过了1000兆瓦,即1吉瓦。一个三峡大坝,大约能跑20个这样的超级算力集群组合。
扎克伯格在最近一次采访中,对下一代AI算力集群的能源扩展感到担忧。他称,目前很多单一数据中心的整体电力规模,大约在50兆瓦和100兆瓦之间。“当我们谈论300兆瓦、500兆瓦或者1吉瓦的时候,情况就不同了。目前没有人能够建造出一个吉瓦级别的单一训练集群。”
这是工程问题,也是政策问题。征地、环保、供电等,这些问题很快将随着大模型扩展定律的持续生效而到来。
Llama3的碳足迹过万吨
能源扩展意味着碳足迹的扩展。按照惯例,Meta公布了Llama3系列模型的碳足迹,其中训练Llama3-8B约产生了390吨二氧化碳,训练Llama3-70B约产生了1900吨。一年前,Meta训练Llama2-70B约产生了290吨二氧化碳。
那么,训练中的Llama3-405B的碳足迹会是多少?这首先要知道训练这样一个模型,大概需要多少GPU时(即实际投入运算的GPU数量与每块GPU具体运算时间的乘积,也可以直观地理解为用一块GPU需要跑的总时间),也就是需要知道在其他条件不变的情况下,训练这样一个模型大概需要多少算力。
Meta透露,在训练Llama3-8B时,共花了130万个GPU时,吞吐量为400 TFLOPS(每秒万亿次浮点运算)。那么,它的训练算力需求约为2e24FLOPs。同理,Llama3-70B的训练算力需求约为9e24FLOPs。
如果套用未尽研究去年在《生成式AI 2023》报告里采用的经验公式,即6×参数规模×token数量,则训练Llama3-8B所需算力约为1e24 FLOPs,训练Llama3-70B所需算力约6e24 FLOPs,与前一种方法基本相当。
如果Llama3-400B+的训练环境不变,它所需算力可能达到了约40e24 FLOPs级别,相当于2700万个GPU时。
预训练大模型的碳足迹,相当于:训练阶段的电力消耗X数据中心的碳排放因子。训练阶段的电力消耗,Meta简化为“训练模型所需的总GPU 时间”与“每个GPU设备的TDP”以及“数据中心的PUE”,但没有披露数据中心的PUE,也没有披露数据中心的碳排放因子,即消耗的这些电有多少来自清洁能源。
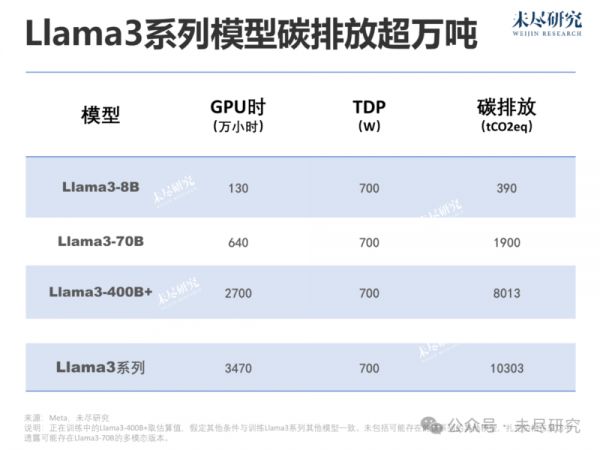
由于训练Llama3系列模型的算力集群,短期内PUE与碳排放因子不会剧烈波动,我们可以将这些变量综合简化为特定系数。那么,在相同的算力集群上花2700万个GPU时训练Llama3-400B+的碳排放将达到8013吨二氧化碳,整个Llama3系列超过万吨碳足迹。
尽管Meta是目前少有的仍然愿意公开谈论碳排放的大模型厂商,但它的碳足迹算法还是避重就轻了。事实上,它只计算了H100运行中释放的碳足迹,还没有包括内存等其他关键IT设备的碳足迹。如果加上,它的碳排放还将扩大约1倍。它也没有计算制造和运输这些关键IT设备的过程中涉及的总碳排放量,即范围三。一些人大致估计,范围三约占大模型训练一次的碳足迹的10%。
Meta很骄傲地表示,它选择了开源,就意味着其他人没必要再重复排放预训练部分的二氧化碳。
本文来自微信公众号:未尽研究 (ID:Weijin_Research),作者:未尽研究
相关推荐
用起来少费电的模型,可能比GPT-5更重要
谈碳 | 腾讯SSV副总裁许浩:没什么碳排放的腾讯,为什么要碳中和?
牛的碳排放接近美国,如何“碳中和”一头牛?
iPhone不送充电头两年了,地球减少了0.05%的碳排放 | 焦点分析
碳排放交易正式启航,哪些行业率先“吃肉”? 哪些行业有望“喝汤”?
农业科技公司「极飞」:去年减少96万吨碳排放,正在种植“超级农场”
Llama3发布,GPT-5你到底在哪里呢?
闲鱼亮相COP28,定下“服务10亿用户,减碳5500万吨”目标
哈啰:用户累计骑行里程471亿公里 减少碳排放超220万吨
地沟油会梦见环保飞机吗?
网址: 训练Llama3产生万吨碳排放,费电还不环保? http://www.xishuta.com/newsview116157.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95018
- 2人类唯一的出路:变成人工智能 19836
- 3报告:抖音海外版下载量突破1 19612
- 4移动办公如何高效?谷歌研究了 19071
- 5人类唯一的出路: 变成人工智 18940
- 62023年起,银行存取款迎来 10192
- 7网传比亚迪一员工泄露华为机密 8291
- 8五一来了,大数据杀熟又想来, 7420
- 9顶风作案?金山WPS被指套娃 7139
- 10大数据杀熟往返套票比单程购买 7086



