Kimi能读200万字长文?警惕AI大模型热潮下的“创骗”新篇章
当年,共享单车、共享汽车、互联网咖啡等创业项目如雨后春笋般涌现,它们以新颖的模式和创新的理念迅速吸引了无数创业者和风投机构的目光。这些项目的共同目标简单而直接——通过快速扩张、提高估值,最终实现上市圈钱套现,这也被业内戏称为“创骗”。然而,时光荏苒,随着技术的不断进步和市场环境的变迁,AI大模型逐渐崭露头角,成为创投行业的新宠。
AI大模型的火爆并非空穴来风。随着计算能力的提升和数据的爆炸式增长,深度学习、自然语言处理等技术取得了突破性进展。这些技术使得AI大模型能够处理海量数据,拥有强大的学习和推理能力。在这样的背景下,国内众多创业公司纷纷涉足AI大模型领域,希望通过技术创新实现弯道超车。
在众多AI大模型中,一个名为Kimi AI的大模型以其独特的技术优势迅速脱颖而出。这款大模型号称能够阅读并理解长达200万字甚至1000万字的长文本,这在业界引起了广泛的关注。随着Kimi AI的知名度不断提升,其母公司月之暗面的估值也水涨船高,上线一年就被炒到了惊人的180亿元。然而,在这光鲜亮丽的背后,却隐藏着一些不为人知的秘密。

前不久,有传闻称Kimi AI的母公司月之暗面的创始人“90后”杨植麟已经迫不及待地套现了4000万美元。这一举动立即引发了外界的广泛关注和质疑。有人认为这是杨植麟在Kimi AI估值被炒高后,利用套现离场的方式获取巨额利润。而更多的人则开始怀疑Kimi AI的技术实力和市场前景,甚至有人猜测这是否又是一场类似共享单车、共享汽车的典型“创骗”。
从技术角度来看,Kimi AI声称能够读懂200万字长文本确实令人难以置信。要实现这一功能,需要从多个方面入手。
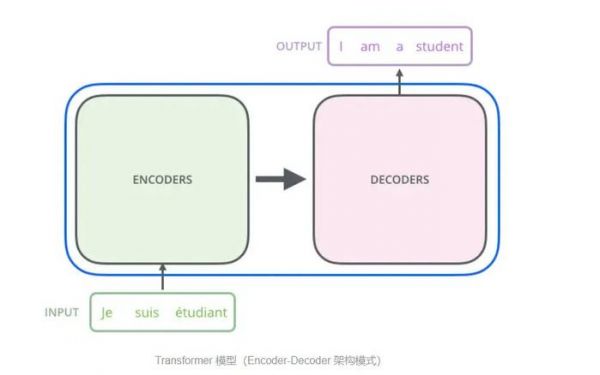
首先,狂堆算力是一个必不可少的步骤。现在所有大语言模型都采用了transformer架构,这种架构在处理长文本时存在天然的局限性。每生成一个新字,都需要与之前的字进行交互,导致计算量呈指数级增长。
因此,要实现200万字长文本的阅读功能,就需要消耗巨大的算力资源。然而,算力本身就是一项昂贵的投资,OpenAI等巨头在算力成本上的投入已经相当惊人,至今尚未实现盈利。对于像Kimi这样的创业公司来说,要承担如此巨大的算力成本几乎是不可能的。
除了狂堆算力外,还有一些外挂技术可以帮助实现长文本阅读功能。其中一种是滑动窗口技术,它通过将长文本截成若干段并分别处理,最后再将处理结果汇总来实现长文本的阅读。然而,这种技术存在信息丢失的问题,无法完全保留长文本中的细节信息。
另一种外挂技术是RAG检索增强技术,它利用搜索引擎等技术获取与长文本相关的外部信息,并将其与长文本本身进行融合处理。这种技术可以获取更多的细节信息,但同样存在一些问题。例如,它依赖于外部数据源的质量和覆盖范围,对于某些特定领域或专业知识的处理可能不够准确。
然而,Kimi AI却声称自己拥有独特的技术优势,能够完美解决以上问题并实现长文本阅读功能。这不禁让人怀疑其技术实力和市场前景的真实性。实际上,Kimi AI的技术能力很可能被过度夸大和炒作,以吸引更多的投资人和用户。若属实,这种炒作行为不仅损害了投资者的利益,也对整个AI大模型行业的发展带来了负面影响。
回顾历史,我们可以看到许多类似夸大其词的创业,最后都烧钱无数,一地鸡毛,比如共享单车行业就烧掉了至少300亿元。大量创业项目演变为“创骗”行为。
如今,随着AI大模型的火爆和创投行业的热情高涨,新一轮的“创骗”行为似乎又在AI大模型领域上演。这让我们不禁要问:在追求技术创新和商业成功的同时,我们是否也应该保持一份理性和警惕?毕竟,只有真实的技术实力和市场前景才能支撑起一个企业的长远发展。
发布于:山东
相关推荐
Kimi能读200万字长文?警惕AI大模型热潮下的“创骗”新篇章
大模型Kimi爆火,能解国产GPT的“意难平”么?
AI企业疯狂“卷”文本
Kimi爆火后,大厂角逐长文本
Kimi爆了 国产大模型应用元年还远吗?
第一批AI大模型独角兽,创始人已经开始套现了?
真假“长文本”,国产大模型混战
Kimi概念股爆火,国产AI突然又行了?
三个清华校友,争抢大模型一哥
月之暗面反割阿里一把?
网址: Kimi能读200万字长文?警惕AI大模型热潮下的“创骗”新篇章 http://www.xishuta.com/newsview120321.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95228
- 2人类唯一的出路:变成人工智能 21183
- 3报告:抖音海外版下载量突破1 21148
- 4移动办公如何高效?谷歌研究了 20339
- 5人类唯一的出路: 变成人工智 20338
- 62023年起,银行存取款迎来 10336
- 7五一来了,大数据杀熟又想来, 8596
- 8网传比亚迪一员工泄露华为机密 8505
- 9滴滴出行被投诉价格操纵,网约 8215
- 10顶风作案?金山WPS被指套娃 7230



