下一代AI芯片,拼什么?
来源:半导体行业观察
作者:杜芹DQ
AI这“破天的富贵”,谁都不想错过。尽管摩尔定律逼近极限,芯片性能的提升变得更加困难。但各大厂商依然以令人瞩目的速度推出新一代产品,在近日召开的台北国际电脑展上,英伟达、AMD和英特尔三大芯片巨头齐聚一堂,纷纷秀出自家肌肉,推出了下一代AI芯片。
英伟达的Hopper GPU/Blackwell/Rubin、AMD的Instinct 系列、英特尔的Gaudi芯片,这场AI芯片争霸战拼什么?这是速度之争,以英伟达为首,几家巨头将芯片推出速度提升到了一年一代,展现了AI领域竞争的“芯”速度;是技术的角逐,如何让芯片的计算速度更快、功耗更低更节能、更易用上手,将是各家的本事。
尽管各家厂商在AI芯片方面各有侧重,但细看之下,其实存在着不少的共同点。
一年一代,展现AI领域“芯”速度
虽然摩尔定律已经开始有些吃力,但是AI芯片“狂欢者们”的创新步伐以及芯片推出的速度却越来越快。英伟达Blackwell还在势头之上,然而在不到3个月后的Computex大会上,英伟达就又祭出了下一代AI平台——Rubin。英伟达首席执行官黄仁勋表示,以后每年都会发布新的AI芯片。一年一代芯片,再次刷新了AI芯片的更迭速度。
英伟达的每一代GPU都会以科学家名字来命名。Rubin也是一位美国女天文学家Vera Rubin的名字命名。Rubin将配备新的GPU、名为Vera的新CPU和先进的X1600 IB网络芯片,将于2026年上市。
目前,Blackwell和Rubin都处于全面开发阶段,其一年前在2023年在Computex上发布的GH200 Grace Hopper“超级芯片”才刚全面投入生产。Blackwell将于今年晚些时候上市,Blackwell Ultra将于2025年上市,Rubin Ultra将于2027年上市。
紧跟英伟达,AMD也公布了“按年节奏”的AMD Instinct加速器路线图,每年推出一代AI加速器。Lisa Su在会上表示:“人工智能是我们的首要任务,我们正处于这个行业令人难以置信的激动人心的时代的开始。”
继去年推出了MI300X,AMD的下一代MI325X加速器将于今年第四季度上市,Instinct MI325X AI加速器可以看作是MI300X系列的强化版,Lisa Su称其速度更快,内存更大。随后,MI350系列将于2025年首次亮相,采用新一代AMD CDNA 4架构,预计与采用AMD CDNA 3的AMD Instinct MI300系列相比,AI推理性能将提高35倍。MI350对标的是英伟达的Blackwell GPU,按照AMD的数据,MI350系列预计将比英伟达B200产品多提供50%的内存和20%的计算TFLOP。基于AMD CDNA“Next”架构的AMD Instinct MI400系列预计将于2026年上市。

英特尔虽然策略相对保守,但是却正在通过价格来取胜,英特尔推出了Gaudi人工智能加速器的积极定价策略。英特尔表示,一套包含八个英特尔Gaudi 2加速器和一个通用基板的标准数据中心AI套件将以65,000美元的价格提供给系统提供商,这大约是同类竞争平台价格的三分之一。英特尔表示,一套包含八个英特尔Gaudi 3加速器的套件将以125,000美元的价格出售,这大约是同类竞争平台价格的三分之二。AMD和Nvidia虽然不公开讨论其芯片的定价,但根据定制服务器供应商Thinkmate的说法,配备八个Nvidia H100 AI芯片的同类HGX服务器系统的成本可能超过30万美元。
一路高歌猛进的芯片巨头们,新产品发布速度和定价凸显了AI芯片市场的竞争激烈程度,也让众多AI初创芯片玩家望其项背。可以预见,三大芯片巨头将分食大部分的AI市场,大量的AI初创公司分得一点点羹汤。
工艺奔向3纳米
AI芯片走向3纳米是大势所趋,这包括数据中心乃至边缘AI、终端。3纳米是目前最先进工艺节点,3纳米工艺带来的性能提升、功耗降低和晶体管密度增加是AI芯片发展的重要驱动力。对于高能耗的数据中心来说,3纳米工艺的低功耗特性至关重要,它能够有效降低数据中心的运营成本,缓解数据中心的能源压力,并为绿色数据中心的建设提供重要支撑。
英伟达的B200 GPU功耗高达1000W,而由两个B200 GPU和一个Grace CPU组成的GB200解决方案消耗高达2700W的功率。这样的功耗使得数据中心难以为这些计算GPU的大型集群提供电力和冷却,因此英伟达必须采取措施。
Rubin GPU的设计目标之一是控制功耗,天风国际证券分析师郭明錤在X上写道,Rubin GPU很可能采用台积电3纳米工艺技术制造。另据外媒介绍,Rubin GPU将采用4x光罩设计,并将使用台积电CoWoS-L封装技术。与基于Blackwell的产品相比,Rubin GPU是否真的能够降低功耗,同时明显提高性能,或者它是否会专注于性能效率,还有待观察。
AMD Instinct系列此前一直采用5纳米/6纳米双节点的Chiplet模式,而到了MI350系列,也升级为了3纳米。半导体知名分析师陆行之表示,如果英伟达在加速需求下对台积电下单需求量大,可能会让AMD得不到足够产能,转而向三星下订单。
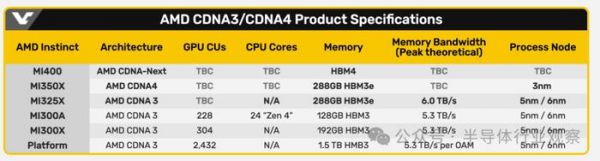 来源:videocardz
来源:videocardz英特尔用于生成式AI的主打芯片Gaudi 3采用的是台积电的5纳米,对于 Gaudi 3,这部分竞争正在略微缩小。不过,英特尔的重心似乎更侧重于AI PC,从英特尔最新发布的PC端Lunar Lake SoC来看,也已经使用了3纳米。Lunar Lake包含代号为Lion Cove的新 Lion Cove P核设计和新一波Skymont E 核,它取代了 Meteor Lake 的 Low Power Island Cresmont E 核。英特尔已披露其采用 4P+4E(8 核)设计,禁用超线程/SMT。整个计算块,包括P核和E核,都建立在台积电的N3B节点上,而SoC块则使用台积电N6节点制造。
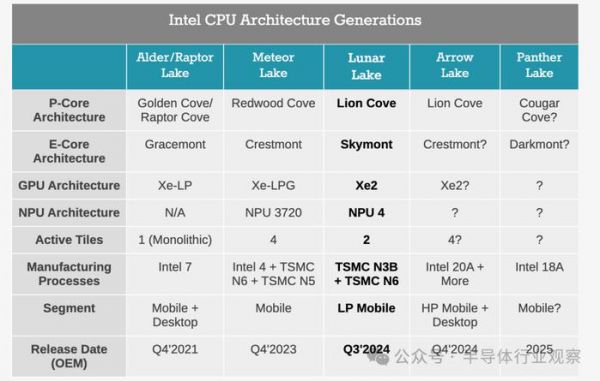
英特尔历代PC CPU架构
(来源:anandtech)
在边缘和终端AI芯片领域,IP大厂Arm也在今年5月发布了用于智能手机的第五代 Cortex-X 内核以及带有最新高性能图形单元的计算子系统 (CSS)。Arm Cortex-X925 CPU就利用了3纳米工艺节点,得益于此,该CPU单线程性能提高了36%,AI性能提升了41%,可以显著提高如大语言模型(LLM)等设备端生成式AI的响应能力。
高带宽内存(HBM)是必需品
HBM(High Bandwidth Memory,高带宽存储器)已经成为AI芯片不可或缺的关键组件。HBM技术经历了几代发展:第一代(HBM)、第二代(HBM2)、第三代(HBM2E)、第四代(HBM3)和第五代(HBM3E),目前正在积极发展第六代HBM。HBM不断突破性能极限,满足AI芯片日益增长的带宽需求。
在目前一代的AI芯片当中,各家基本已经都相继采用了第五代HBM-HBM3E。例如英伟达Blackwell Ultra中的HBM3E增加到了12颗,AMD MI325X拥有288GB的HBM3e内存,比MI300X多96GB。英特尔的 Gaudi 3封装了八块HBM芯片,Gaudi 3能够如此拼性价比,可能很重要的一点也是它使用了较便宜的HBM2e。
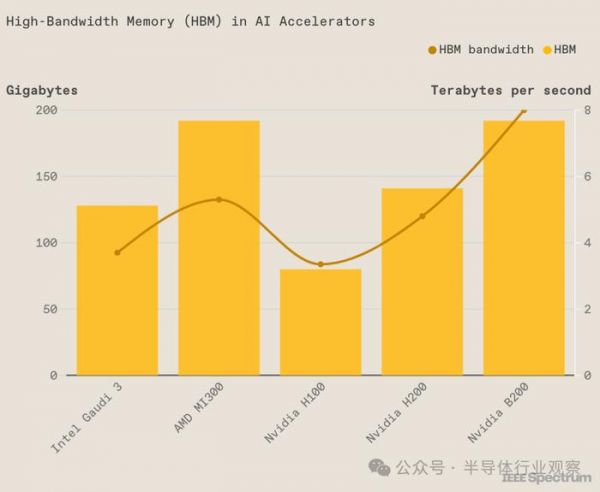
英特尔Gaudi 3的HBM比H100多,但比H200、B200或AMD的MI300都少
(来源:IEEE Spectrum)
至于下一代的AI芯片,几乎都已经拥抱了第六代HBM-HBM4。英伟达Rubin平台将升级为HBM4,Rubin GPU内置8颗HBM4,而将于2027年推出的Rubin Ultra则更多,使用了12颗HBM4。AMD的MI400也奔向了HBM4。
从HBM供应商来看,此前AMD、英伟达等主要采用的是SK海力士。但现在三星也正在积极打入这些厂商内部,AMD和三星目前都在测试三星的HBM。6月4日,在台北南港展览馆举行的新闻发布会上,黄仁勋回答了有关三星何时能成为 Nvidia 合作伙伴的问题。他表示:“我们需要的 HBM 数量非常大,因此供应速度至关重要。我们正在与三星、SK 海力士和美光合作,我们将收到这三家公司的产品。”
HBM的竞争也很白热化。SK海力士最初计划在2026年量产HBM4,但已将其时间表调整为更早。三星电子也宣布计划明年开发HBM4。三星与SK海力士围绕着HBM的竞争也很激烈,两家在今年将20%的DRAM产能转向HBM。美光也已加入到了HBM大战行列。
炙手可热的HBM也成为了AI芯片大规模量产的掣肘。目前,存储大厂SK Hynix到2025年之前的HBM4产能已基本售罄,供需矛盾日益凸显。根据SK海力士预测,AI芯片的繁荣带动HBM市场到2027年将出现82%的复合年增长率。分析师也认为,预计明年HBM市场将比今年增长一倍以上。
三星电子DRAM产品与技术执行副总裁Hwang Sang-joon在KIW 2023上表示:“我们客户当前的(HBM)订单决定比去年增加了一倍多。”三星芯片负责业务的设备解决方案部门总裁兼负责人 Kyung Kye-hyun 在公司会议上更表示,三星将努力拿下一半以上的HBM市场。三星内存业务执行副总裁Jaejune Kim对分析师表示,该公司将在2023年至2024年间将其HBM产能增加一倍。
互联:重要的拼图
AI芯片之间互联一直是个难题,随着近年来越来越多的加速器被集成到一起,如何高效传输数据成为了瓶颈。由于PCIe技术的发展速度跟不上时代需求,目前主流的AI芯片厂商都已经自研了互联技术,其中较为代表的就是英伟达的NVLink和AMD的Infinity Fabric。
NVIDIA的下一代Rubin平台,将采用NVLink 6交换机芯片,运行速度为3600GB/s,上一代的Blackwell采用的是NVLink 5.0。NVLink设计之初,就是为了解决传统的PCI Express (PCIe) 总线在处理高性能计算任务时带宽不足的问题。下图显示了英伟达各代NVLink的参数情况。
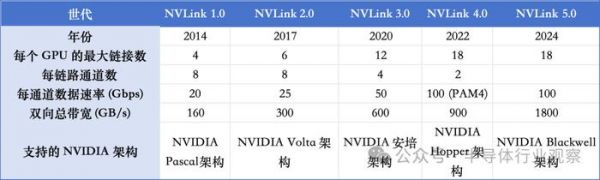 各代NVLink的性能参数
各代NVLink的性能参数与英伟达的NVLink相似,AMD则推出了其Infinity Fabric技术,AMD Infinity 架构与第二代 AMD EPYC处理器一同推出,使系统构建者和云架构师能够释放最新的服务器性能,同时又不牺牲功能、可管理性或帮助保护组织最重要资产(数据)的能力。Infinity Fabric支持芯片间、芯片对芯片,以及即将推出的节点对节点的数据传输。
英特尔则是以太网的坚实拥护者,英特尔的用于生成式AI的Gaudi AI芯片则一直沿用传统的以太网互联技术。Gaudi 2每个芯片使用了24个100Gb以太网链路;Gaudi 3也使用了24个200Gbps以太网RDMA NIC,但是他们将这些链路的带宽增加了一倍,达到200Gb/秒,使芯片的外部以太网I/O总带宽达到8.4TB/秒。
拼服务
诸如ChatGPT这样的生成式AI开发任务极其复杂,大模型需要在多台计算机上运行数十亿到数万亿个参数,它需要在多个GPU上并行执行工作,采用张量并行、流水线并行、数据并行等多种并行处理方式,以尽可能快地处理任务。
因此,如何能够帮助用户更快的开发,提供良好的服务也是关键一役。
在这方面,英伟达推出了一种新型的软件NIMS,即NVIDIA Inference Microservices(推理微服务)。黄仁勋称之为“盒子里的人工智能”,NIMS中包含了英伟达的CUDA、cuDNN、TensorRT、Triton。NIMS 不仅使部署 AI 变得更容易,只需几分钟而不是几个月,它们还构成了客户可以创建新应用程序和解决新问题的构建块。如果采用,NIMS 将有助于加速创新并缩短价值实现时间。Nvidia 还宣布,NIMS 现在可供开发人员和研究人员免费使用。在生产中部署NIMS需要AI Enterprise许可证,每个GPU的价格为4500美元。
结语
下一场AI之战已然打响,综合来看,当前AI芯片市场上,英伟达、AMD和英特尔等主要芯片巨头正在展开激烈的竞争。他们不仅在速度、技术和工艺方面竞相创新,还在互联和服务等领域积极拓展,致力于为用户提供更快、更强、更智能的AI解决方案。AI芯片争霸战仍在继续,谁能最终胜出?让我们拭目以待。
相关推荐
下一代AI芯片,拼什么?
英伟达下一代AI芯片R100将在明年四季度量产
2021年,手机拼什么?
三星将为Tenstorrent制造下一代AI Chiplet
“五行缺AI”,苹果芯片的死结?
三星-LX“半导体联盟”合作开发下一代芯片
AI手机用什么忽悠用户?
先进封装,拼什么?
玻璃芯片要火,多亏了AI
Meta连甩AI加速大招!首推AI推理芯片,AI超算专供大模型训练
网址: 下一代AI芯片,拼什么? http://www.xishuta.com/newsview120425.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95273
- 2人类唯一的出路:变成人工智能 21579
- 3报告:抖音海外版下载量突破1 21553
- 4移动办公如何高效?谷歌研究了 20718
- 5人类唯一的出路: 变成人工智 20712
- 62023年起,银行存取款迎来 10377
- 7五一来了,大数据杀熟又想来, 8945
- 8网传比亚迪一员工泄露华为机密 8569
- 9滴滴出行被投诉价格操纵,网约 8567
- 10顶风作案?金山WPS被指套娃 7258



