腾讯混元大模型参数规模超万亿,副总裁蒋杰:通用大模型会成为“水电煤”

智东西
作者 | 程茜
编辑 | 云鹏
智东西7月5日报道,今日下午,在2024世界人工智能大会(WAIC)腾讯论坛上,据腾讯集团副总裁蒋杰透露,目前腾讯混元大模型采用MoE架构,模型整体参数量已达到万亿,Token数量超过7万亿,居国内大模型第一梯队。
此外,面向大模型应用落地,腾讯已经构建了一套全链路产品矩阵,涵盖从底层丰富基础设施到顶层多元智能应用,包括自研通用大模型、模型开发平台、智能体开发平台,以及针对不同场景定制的智能应用解决方案等。
腾讯云副总裁、腾讯云智能负责人、腾讯优图实验室负责人吴运声认为,今天的大模型技术正在往多模态、零样本学习、3D和视频生成等方向快速演进,腾讯正持续推进AI研究和应用落地。腾讯云全新升级了大模型知识引擎、图像创作引擎、视频创作引擎,比加速大模型在医疗、文娱领域的应用落地。此外,在文化研究方面,腾讯云宣布开源全球最大的甲骨文多模态数据。
当下关于Scaling Law的讨论热度居高不下,吴运声谈道,他看到目前关于Scaling Law的观点有两类,一类认为这一技术路径发展已经较为缓和,另一派认为其仍在持续发展,从他个人来看,Scaling Law整体会在一段时间内发挥作用。例如在多模态的研究中,仍有很多新的突破出现。因此,不能一锤定音对这一技术路径的发展潜力下结论,应该基于不同的场景或者技术演进进行不断探索。
吴运声谈道,优图实验室从创立之初就坚持技术落地到产业中才能产生价值,这也是AI发展的方向,因此,他们一直在围绕这一点推进。技术层面,优图实验室在进行多模态技术、小样本零样本等技术探索;在平台层面构建努力让更多产业链玩家融入进来,不断迭代平台能力,降低AI应用的门槛;第三就是知识引擎、图像创作引擎、视频创作引擎等,将一些工具能力进行封装,帮助用户利用这些工具,快速搭建智能应用,落地到具体场景中。
 ▲腾讯云副总裁、腾讯云智能负责人、腾讯优图实验室负责人吴运声
▲腾讯云副总裁、腾讯云智能负责人、腾讯优图实验室负责人吴运声一、从单模态、多模态向全模态演进,大模型落地缺少杀手级应用
腾讯集团副总裁蒋杰谈道,今年WAIC的焦点毫无疑问是大模型,截止4月底,中国推出的大模型已经超过300个,超过10亿级参数规模的大模型已经超过100个。此外,近日OpenAI还宣布停止中国大陆地区的API调用,这都展现出了实现大模型全链路自主研发的价值与必要性。
目前,腾讯混元大模型采用MoE架构,参数量已经达到万亿级别,Token数量达到7万亿。在此之上,蒋杰总结了目前大模型产业的几大现象。
未来通用大模型将成为像水电煤一样的基础设施,并且会出现不同场景、不同模态、不同尺寸的大模型,企业可以根据自己的需求进行调用、精调。
蒋杰称,目前大模型涌现出来的能力还远远没有达到天花板,当其参数规模不断突破,未来会出现不同尺寸的模型,通过大小模型协同提升性能并满足企业的定制化需求。大模型主要提供强大的模型能力和泛化性能,小模型会针对特定场景进行特殊优化,实现更快、更有效的精准推理。
腾讯混元大模型已通过腾讯云向企业及个人开发者开放,包含万亿、千亿、百亿等不同参数尺寸,接下来,多种尺寸的腾讯混元MoE模型也将对外开源,可分别支持手机端、PC端、云以及数据中心等多样化的部署场景。
此外,大模型行业正经历从单模态到多模态,再到全模态的演进。
他补充说,在文生图领域,采用DiT架构的模型融合了早前主要用于文本生成的Transformer架构,并在图像和视频生成任务中展现出了显著的优势;在文生视频领域,视频生成正朝着更高分辨率、更长时长、更精细的方向发展,一些较好的模型已经能够生成长达数分钟高清的视频,带来了广阔的应用想象空间。
在应用方面,蒋杰认为,应用场景将是未来大模型决战的必然因素。当前大模型落地主要在工作提效方面,距离真实的业务有一定距离,缺少了杀手级应用。
腾讯很早就将大模型定位为应用型大模型,并不断在内部产品上进行打磨,目前腾讯内部已经有接近700个业务和场景接入大模型,每天调用量达到3亿次左右。接下来,腾讯将基于这些实践呈现的能力和经验通过腾讯云对外开放。
二、混元大模型训练语料超7万亿,多个版本已开源
腾讯在大模型领域已经构建了一套全链路产品矩阵,涵盖从底层丰富基础设施到顶层多元智能应用。包括自研通用大模型、模型开发平台、智能体开发平台,以及针对不同场景定制的智能应用解决方案等。
吴运声谈道,过去一段时间的发展使得AI技术进阶达到新的制高点,但实际落地中,单模态技术只在部分场景表现良好,多模态的加持能扩展大模型的应用范式。如多模态大模型可以结合视觉和语言理解突破此前的技术应用局限,实现更精准的语义分析等。
学习范式上,传统模型受限于任务独立和需要大量标注数据,通过零样本和小样本学习就可以简化研发流程。如生成数字人,现在仅需一张照片就可以生成而无需其他定制过程。吴运声谈道,这类技术还可以应用到工业质检场景,通过简单的词汇提示或者缺陷图示照片就可以提高缺陷检测的效率和准确性。

此外,在内容呈现方面,随着视频生成等技术发展,用户可以获得更沉浸式的体验,如通过3D生成技术打破传统的物理仿真局限,提高生成内容的速度和质量。
基于底层技术的突破,腾讯的大模型也在不断进化。去年9月,腾讯发布了全链路自研腾讯混元大模型,基于MoE模型达到了万亿参数规模级别,预训练语料超过7万亿Token。吴运声称,腾讯混元大模型已经稳居国内大模型的第一梯队,单日调用Token数已经超过千亿。
腾讯云上开放了混元lite 256k版本、vision多模态版本,以及代码生成、角色扮演等子模型和接口,满足不同企业和开发者的需求。
三、全链路产品矩阵,知识引擎、图像创作、视频创作升级剑指应用落地
在模型工具产品层面,今年5月,腾讯推出三个大模型PaaS产品,包括知识引擎、图像生成引擎和视频生成引擎。目前这三大产品已经实现了升级迭代。
知识引擎的动态检索能力升级,支持图文互搜、以图搜图等,还能够结合知识库中检索返回的图文片段给出图文并茂的答案。腾讯还进一步扩展了企业知识类型覆盖面,升级了对话式数据问答体验,支持超大表格、多场景的多步骤推理、多条件筛选、求和计算等。
在图像创作引擎中,其图像风格已经新增到33种,并推出了专用于头像的生成模式,使得生成的图片既能保留个人相貌特色,还可以融入多元艺术风格特征。同时,该工具还新增了商品背景生成、模特换装、创意换装等,能够降低营销和影视行业的制作成本。
腾讯在视频创作引擎中新增了超过20种热门舞蹈动作,并且基于3D建模技术和生成技术,能够提升视频的音频自然度、相似度和语速效果。

与此同时,为了帮助企业更快速打造专属模型应用,腾讯机器学习平台TI在精调数据准备、精调训练和模型验证平台方面进行了全面升级。
TI平台内置开源可扩展的数据构建,能帮开发者进行数据准备,并提升了数据标注能力;在精调训练方面,该平台支持一键启动精调任务,通过3层稳定机制并支持自研安卓框架确保大模型训练的连续性和性能提升;模型验证过程中,TI平台采用三阶段模型评测流程,包括轻量体验、客观决策、主观评测。

目前,腾讯已经围绕办公协同、数据分析、知识管理、智能营销等多个产品为用户提供全链路的模型服务。吴运声称,他们已经将知识引擎的能力应用于起点客户大模型的文本机器人之上,面向账单查询和退换货等复杂任务时,大模型机器人的配置成本相较于传统文本机器人可以减少50%以上。
服务于企业内部的知识学习协作平台腾讯乐享,目前已经服务超30万家客户,拥有上亿用户,在大模型和知识引擎的加持下,乐享围绕知识生产端和消费端实现了突破。
吴运声举例称,在知识生产端,一句话AI就可以完成协作,同时还能生成培训知识点提升不同部门的培训效率;在知识消费端,腾讯推出了智能问答,可以让AI回答更多的企业内部业务知识,提高知识获取效率。
四、已落地医疗、文娱、科研,开源全球最大甲骨文多模态数据集
在产业落地方面,腾讯已经在医疗、文娱、科学研究等领域实现突破。
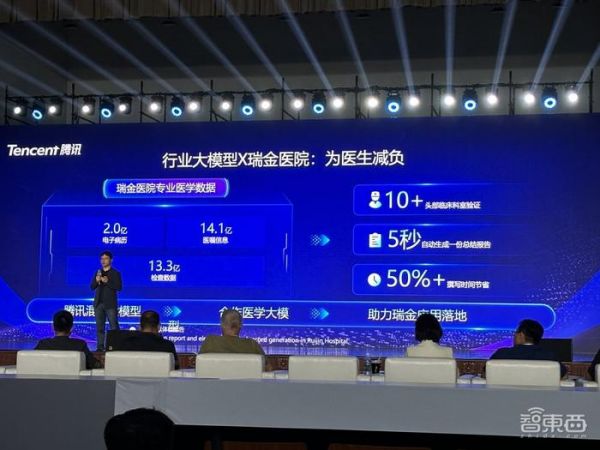
医疗领域方面,腾讯和上海市数字医学创新中心共研了医学大模型,并在瑞金医院实现了体检报告和电子病历生成等落地应用。在体检报告生成方面,大模型平均5秒就可以生成体检报告,为医生节约了超50%的撰写时间。
文娱行业,腾讯和阅文集团基于大模型文生文的能力,为作家提供了AI辅助写作助手,包括描写灵感、大纲提取、角色提取等能力,可以帮助作家写作、插图制作等。

在这之外,吴运声也谈道,多模型的应用也会为企业带来很多现实问题。
首先,企业的工程团队资源有限,针对迭代很快的模型去自行搭建推理集群和服务平台很复杂;其次,模型的推理成本很高,并且百亿、千亿级别模型的推理部署会在吞吐量、时延方面面临瓶颈。
腾讯TI平台就是这些解决这些难题的答案。
企业只需要在TI平台上进行点选就可以快速开启训练任务,在推理方面,腾讯已经帮助阅文集团提升了相同资源条件下的内容生成速度,另外平台也提供了更直观的监控、管理工具,帮助其管理任务和资源。
在产业落地之外,大模型在科学计算、文化研究等方面的应用价值正在被放大。
在天文领域,基于AI技术加持,腾讯已经发现了3例快速射电暴和41颗脉冲星,据吴运声透露,快速射电暴是目前天文界研究的重点,相比脉冲星,快速射电暴因为发行时间短、AI训练数据少、出现频率低,因此其发现难度相比脉冲星更大。

基于此,腾讯设计了全新的端到端AI算法,引入了多示例学习和大模型的注意力机制,可以提升模型的精度和数据处理速度。
文化领域,腾讯今天开源了全球最大的甲骨文多模态综合数据集,包含拓片、摹本;单字对应位置、对应字头等。该数据集可以帮助研究人员开发甲骨文检测识别模版、生成自行。

最后,吴运声谈道,无论在产业落地还是科学文化探索、大模型技术的进阶,这些发展都离不开完整的产业链协同和生态共建。
结语:腾讯已积累大模型全链路自研技术
一直以来,从语音、图像到大模型,腾讯一直都仅仅站在AI技术发展的中心位置,通过核心技术突破在结合场景推动AI的研究与落地,目前在大模型方面,腾讯已经积累了从算力基础设施到机器学习平台以及上层应用的全链路自研技术。
随着大模型这类前沿AI技术在实体经济、文化保护、科学发现等领域的应用深入,并且上中下游的产业链协同和生态共建加速,AI正在成为全社会智能升级的强劲动力。
发布于:北京
相关推荐
全面拥抱大模型!腾讯正式开放全自研通用大模型:参数规模超千亿、预训练语料超 2 万亿 tokens
来自科技进步一等奖的肯定:腾讯破解万亿参数大模型训练难题
大模型落地竞速,腾讯用三条路线圈地
腾讯旗下协作SaaS产品全面接入混元大模型,实现智能化升级
腾讯刘煜宏:多模态大模型将重塑内容产业
腾讯为何不做通用大模型产品?
腾讯混元大模型开始应用内测,多个业务线接入测试 | 36氪独家
腾讯宣布:全面降价,立即生效!
腾讯混元携手一汽红旗及QQ,打造红旗品牌虚拟代言人
国产大模型即将决战
网址: 腾讯混元大模型参数规模超万亿,副总裁蒋杰:通用大模型会成为“水电煤” http://www.xishuta.com/newsview121816.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95064
- 2人类唯一的出路:变成人工智能 20149
- 3报告:抖音海外版下载量突破1 19949
- 4移动办公如何高效?谷歌研究了 19373
- 5人类唯一的出路: 变成人工智 19255
- 62023年起,银行存取款迎来 10226
- 7网传比亚迪一员工泄露华为机密 8342
- 8五一来了,大数据杀熟又想来, 7703
- 9滴滴出行被投诉价格操纵,网约 7326
- 10顶风作案?金山WPS被指套娃 7158



