所谓AI革命,到现在为止,是能源的一场“灾难”
6月底,谷歌新一代开源模型Gemma2发布,相比今年早些时候推出的轻量级开源模型Gemma,Gemma2有了90亿(9B)和270亿(27B)两种参数规模可用。
就在谷歌摩拳擦掌准备与OpenAI一较高下时,前几天其发布的一份报告却引来了媒体的“担忧”——谷歌最新发布的环境报告指出,自2019年以来,其温室气体总排放量增长了48%。
仅去年一年谷歌就产生了1430万吨二氧化碳,同比2022年增长13%,主要由于来自范围2的碳排放同比增长37%。
这些数据显然与谷歌“2030年实现零排放”的目标南辕北辙了,作为全球最大的互联网科技巨头之一,如此“奔放”的碳排放数据显然会为其招来各种非议。
为何碳排放大增?
在谷歌发布的环境报告中,其将碳排放量激增归因于数据中心的能源的使用和供应链排放的增加。自互联网诞生以来,数据中心一直是高能耗的代表,而今用于训练人工智能的数据中心更是如此。
谷歌在报告中称:“随着我们进一步将人工智能融入到产品中,减少碳排放变得更具有挑战性,因为人工智能计算强度的提高导致能源需求增加,而基础设施投资的增加也会导致碳排放增加。”
据报告数据显示,谷歌仅数据中心的用电量在2023年就增长了17%,预计这一“趋势”将在未来持续下去。
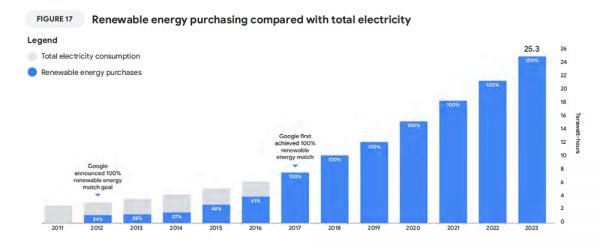
实际上,谷歌的碳排放已经是“极力优化”的结果了,报告指出截至2023年底,谷歌连续七年实现100%可再生能源消耗,并借此在2023年实现了63%的碳排放减少。
图源:谷歌2024环境报告
在此基础上,碳排放之所以仍然大幅增长,主要是因为数据中心耗能太大,但可再生能源有限,无可奈何。
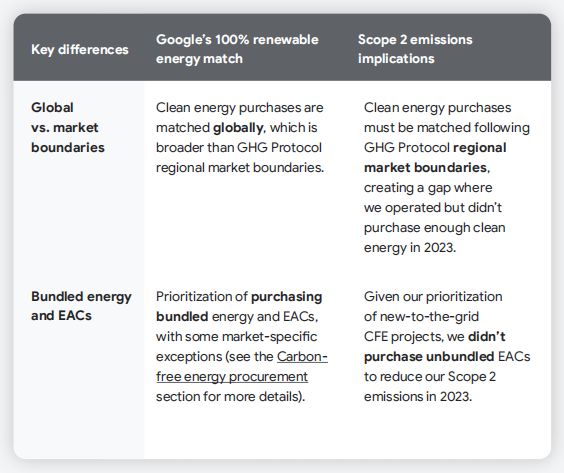
报告原文指出,谷歌已经努力在全球实现100%可再生能源匹配的目标,但GHG协议为能源采购确立了范围以减少范围2的排放。这就导致在一些地区我们购买的清洁能源比我们的电力消耗量更多(例如欧洲),但在其他地区(如亚太地区)由于清洁能源采购具备一定挑战,导致采购不足。这之间的差异是范围2碳排放统计增加的原因。
图源:谷歌2024环境报告
总而言之,谷歌想表达的无非是“我很努力,但在AI革命的浪潮下无计可施”,颇有一种“发展才是硬道理的意思”。
的确,以如今AI爆发的势头,如果让能源卡了自己的脖子,导致大模型落后于OpenAI,以至于丢了人工智能时代的“船票”,那可不是谷歌愿意看到的结果。
虽然谷歌在报告中给出了后续解法,比如正在努力提高其人工智能模型、硬件和数据中心的能源效率,以及计划到2030 年实现24/7全天候无碳能源(CFE)这一终极目标。但随着人工智能的不断发展,大模型的不断迭代,谷歌需要的能耗依然是只会多不会少。
未来,谷歌大概率将持续面对来自公众及媒体关于气候议题的压力。
AI何以成为“吃电狂魔”?
谷歌并不是唯一一家碳排放不断增加的科技公司。
今年5月,微软透露自2020年以来,其二氧化碳排放量增加了近30%。而为OpenAI提供大量计算的雷德蒙德也将排放量的增加归咎于其云计算和人工智能业务部门的数据中心设施的建设和配置。
可以说,正在自己开发大模型的互联网科技公司几乎都有“能耗/碳排放巨大”的问题。
大模型究竟有多耗电?灵碳智能创始人李博杰告诉虎嗅,根据推测,以GPT-4为例,其训练使用了25000张a100,并花了90-100天进行训练,预计总耗电量在51,000mwh - 62,000mwh左右。
而一户普通人家一年的用电量大概在1000kwh左右,因此全部训练耗能相当于5万户人家一年的用电量;同时,此耗电量相当于三峡大坝一年发电量(按一年发电1000亿千瓦时计算)的0.05%,发电侧使用的水量约为2.3亿立方米(三峡电站标准)。
从使用侧来看,1次GPT-4查询估计消耗约0.005 kwh。根据OpenAI公布的数据,GPT每天在全球有数亿次查询,保守估计每天消耗的电量为1gwh。
按一户普通人家一年用电1000kwh算,每天模型推理耗能相当于1000户人家一年的用电量;若按年计算,OpenAI消耗的能源在90-200gwh左右,相当于三峡大坝一年发电量(按一年发电1000亿千瓦时计算)的0.2%,发电侧使用的水量约为9亿立方米(三峡电站标准)。
荷兰科学家亚历克斯·德弗里斯也在他的论文中指出,到2027年,AI耗电量或将接近人口超过1000万的瑞典或1700万人口的荷兰一年的总用电量,相当于当前全球用电量的0.5%。
一笔账算完堪称恐怖,也怪不得黄仁勋与山姆·奥特曼都会喊出“未来AI的技术取决于能源”这一论调了。
一个很重要的问题是,为什么人工智能大模型如此耗能?
从技术原理的角度看,李博杰认为主要有4点原因:
目前主流的LLM模型采用了基于transformer架构的深度神经网络算法,这种架构的算法通过自注意力机制处理数据,并考虑序列的不同部分或句子的整个上下文,从而生成对模型结果的预测。市面上先进的LLM通常包含了万亿级别的参数,参数越多,模型复杂度越高,训练时的计算量就越大。
模型训练的基础数据(如大规模语料库)的存储、处理都需要消耗大量的能源。
目前的LLM都采用了并行化的方式进行计算,所以对高性能的GPU集群有着大量的要求。高性能的GPU的运作不仅消耗大量的能源,同时也对冷却系统提出了很高的要求。
LLM的推理阶段,用户每一次查询都涉及能源的消耗。
这些因素共同导致了人工智能大模型在训练和推理过程中会消耗大量能源。
而当下巨头混战大模型的背后,映射的也是全球能源消耗的大增。根据国际能源署的数据,2022年美国2,700个数据中心消耗了全国总电力的 4% 以上;到2026年,全球数据中心的电力消耗可能会翻一番。
随后,高盛在2024年4月的一项分析预测,至本世纪末全球数据中心的用电量将增加1.8倍至3.4倍。
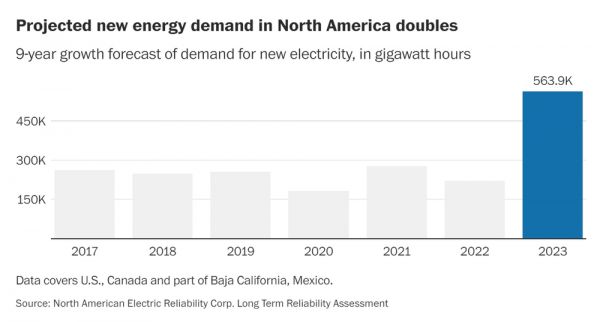
华盛顿邮报则是直接指出,不断飙升的用电需求引发了人们的争夺,试图从老化的电网中榨取更多的电力。但据美国能源信息署数据显示,2023年,美国全口径净发电量为41781.71亿千瓦时,比上一年下降1.2%。近十年来,美国的全年净发电量一直在40000亿千瓦时的边缘徘徊。
图源:华盛顿邮报
无可否认,能源危机(主要是电)已近在眼前,且很可能成为制约AI发展的关键因素。
高能耗还得持续下去
AI要想发展必须得维持这样的高能耗吗?
比尔盖茨曾经在接受媒体采访时表示不用担心,因为人工智能虽然消耗能源,但技术会进步,未来的能耗会持续下降。
但关键问题在于,当下大模型的训练是否有尽头?
在第六届北京智源大会上,杨植麟、王小川等4位大模型CEO就AGI的实现进行了一次交流,4位CEO的共识是AGI太遥远,只有模型降价最能推动现实落地。
李博杰也认为,即便是算力一直无限增加,按照目前主流大模型的技术路线,不会达到理想的AGI阶段:“AGI代表了AI算法拥有类似人脑的思考模式。目前深度神经网络只是对人脑运作时的电信号传播的一种简化模拟。根据目前人类对人脑运作模式的了解,人脑的运作还包含神经递质传递,基因调控,分子信号传导,非神经细胞调节,体液因子调节等多个不同的信号运输和调节机制。因此,基于深度神经网络的LLM发展,不会达到类脑智能的水平。”
从另一个角度讲,语言只是人类意识的其中一个维度映射,在这个过程中存在大量的信息丢失和扭曲。人类在认识世界的过程中,还包含了视觉、听觉、触觉、嗅觉、味觉等多个不同维度。同时,人类自身的运动学习,情绪,社会化的行为和自我意识都是AGI的重要组成部分。
“真正的AGI智能,一定是低能耗的,不过在探索的过程中,会消耗大量的能源,能源消耗是人类社会的终极问题,”李博杰表示:“从可以预测的未来看,能耗问题给人工智能发展带来的最大的问题是加速全球社会的不平等。能源条件差的国家会在这一轮技术变革中掉队。”
如今,行业虽然正在尝试解决AI高耗能的问题,比如通过模型的压缩和蒸馏、更高性价比的专用AI芯片和硬件架构等等,但未来高能耗还将维持一段不短的时间。
就如同科技的发展是螺旋上升的过程,AGI的实现也需要依赖各种学科的同步发展。当下能够期盼的是,假如大模型算法有尽头,希望当我们走到尽头时,AI能够带来真正的生产力革命吧。

相关推荐
AI是一场革命,我真不是在跟风
专访比尔·盖茨:通过技术创新,可以阻止人类滑向灾难
一场灾难引发的电网崩溃和人员伤亡
零碳革命,一场“85万亿”美元的生意
是时候对飞机发起一场电动革命了
氢燃料电池:一场迟来的能源变局
为什么灾难总能成为阴谋论的温床?
麦当劳正在迎来一场革命,未来帮你点单和炸薯条的可能都不是人
是乌托邦还是生态杀手?农业机器人可能使人类陷入意外的灾难
能源革命形势下,我国能源安全战略与对策探讨
网址: 所谓AI革命,到现在为止,是能源的一场“灾难” http://www.xishuta.com/newsview121988.html
推荐科技快讯






- 1问界商标转让释放信号:赛力斯 94804
- 2人类唯一的出路:变成人工智能 18078
- 3报告:抖音海外版下载量突破1 17596
- 4移动办公如何高效?谷歌研究了 17349
- 5人类唯一的出路: 变成人工智 17185
- 62023年起,银行存取款迎来 9989
- 7网传比亚迪一员工泄露华为机密 7960
- 812306客服回应崩了 12 6350
- 9顶风作案?金山WPS被指套娃 6252
- 10大数据杀熟往返套票比单程购买 6233



