TPU芯片:国内面对AI大模型的另一种解法
本文来自微信公众号:电子工程世界 (ID:EEworldbbs),作者:付斌
自从AI大模型来了,英伟达喝汤喝到撑,GPU自然也就成了香饽饽。但在地缘政治局势愈发紧张的现如今,国内高端AI芯片不断被围追堵截。
就比如,7月22日就出现了戏剧性的一幕,英伟达出现一正一反的消息:一方面,美政府正考虑新的贸易限制,阻止英伟达向中国市场推出“特供版”HGX-H20 AI GPU,如果限制正式实施,英伟达可能会损失约120亿美元的收入;另一方面,英伟达正在为中国市场打造全新的特供版GPU,以刚推出的“Blackwell”为基础打造B20。
可以说,美国方面的态度非常鲜明,就是要全面围堵中国获取高端AI芯片的所有渠道,以此占领AI领域的高地。
在这种情况下,国内又该如何应对?最近一段时间内,国内开始瞄准TPU(张量处理单元),另辟蹊径。
国内也有厂商做TPU了
众所周知,AI大模型主要分为两个阶段,一是训练,二是推理。
推理芯片常见,而训练芯片不常见,这是因为训练不仅消耗算力资源巨大,同时需要处理大量的并行任务,所以GPU才会成为当前的主流。
TPU全称Tensor Processing Unit,是一种专为处理张量运算而设计的ASIC芯片,由谷歌自研在2016年推出首款产品。在深度学习的世界里,张量(多维数组)是无处不在的。TPU就是为了高效处理这些张量运算而诞生的。
TPU内置大量矩阵运算单元,使得其能够并行处理大量的矩阵运算,大大提高计算效率。
不过相比GPU或者说GPGPU,TPU太专用了,但是应付AI训练还是绰绰有余。
简单粗暴对比起来就是:TPU与同期的CPU和GPU相比,可以提供15~30倍的性能提升,以及30~80倍的效率(性能/瓦特)提升。
早在2018年,就有一家AGM Micro的国内公司提供TPU推理技术授权,不过,后来这家公司基本不怎么发布关于TPU相关的消息了。
而在最近,一家名为中昊芯英的国产公司,就展出了其中国首枚高性能TPU(张量处理器)AI训练芯片。
据了解,中昊芯英TPU“刹那”于去年成功量产,已在全国多地千卡集群规模的智算中心交付落地。该芯片以1024片芯片高速片间互联的能力构建了大规模智算集群“泰则”,系统集群性能远超传统GPU数十倍,可支撑超千亿参数AIGC大模型训练与推理。
公开资料显示,中昊芯英创始人杨龚轶凡曾在谷歌作为芯片研发核心人员深度参与了谷歌TPU 2/3/4的设计与研发,在他看来,TPU是为AI大模型而生的天然优势架构。
碳纳米管和TPU,牵手了
昨日,也传出另一个与TPU相关的消息。
消息显示,北京大学电子学院碳基电子学研究中心彭练矛-张志勇团队,在下一代芯片技术领域取得突破,成功研发出世界首个基于碳纳米管的张量处理器芯片(TPU)。
官方表示,高能效计算芯片的发展有两个重大瓶颈:一是传统冯诺依曼架构已经无法满足高速、高带宽的数据搬运和处理需求;二是构建芯片的硅基互补金属氧化物半导体晶体管,进入了尺寸缩减、功耗剧增的困境,亟需发展超薄、高载流子迁移率的半导体作为沟道材料。
而碳纳米管具有优异的电学特性和超薄结构,碳纳米管晶体管已经展现出超越商用硅基晶体管的性能和功耗潜力。不过,为了最大化发挥芯片算力和能效,必须将新材料与器件结合,北大的这一个成果就主要围绕这方面进行了研究。
作为世界首个碳纳米管基的张量处理器(TPU)芯片,可实现高能效的卷积神经网络运算。省流版总结如下:
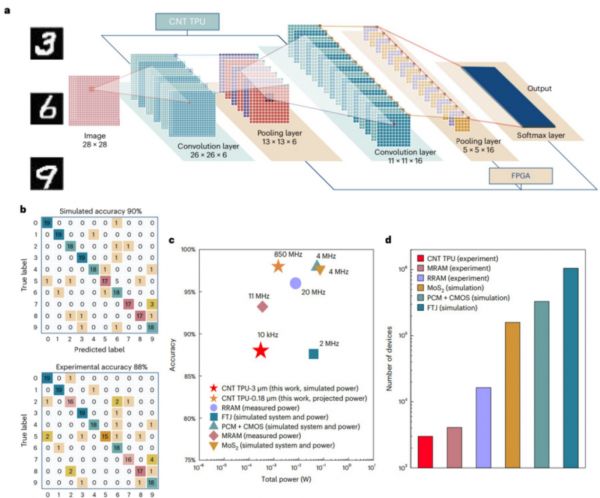
工艺:该芯片采用2bit MAC(乘累加单元),3微米工艺技术节点,集成3000个碳基晶体管,可实现图像轮廓识别、提取等功能,图像轮廓提取正确率达100%;
架构:该芯片采用脉动阵列架构设计,可实现高效地数据复用,大大节约张量运算所需的数据存储、搬运等操作,精准匹配了神经网络的运算特点;
识别率:其上搭建了5层卷积神经网络,实现手写数字识别的应用,理论正确率90%,实际正确率可达86%;
功耗:仅为295µW,器件总数也为新型卷积加速硬件中的最低值;
实际应用效果:该芯片可使用180 nm碳基技术进行流片加工,仿真结果表示,碳基神经网络加速芯片可在1 V电压下工作,可运行的最高主频为850 MHz,能效可以达到1TOPS/w。
“群殴”英伟达
相比其它AI芯片来说,TPU的关注度的确很多。今年6月,就有消息称,生成式AI技术大厂OpenAI为了自研AI芯片,几乎所有新招募的研究人员均为谷歌TPU团队的前员工。可以说,在大规模训练和推理上,TPU是相对成熟的方案。
作为TPU的发明者,谷歌之所以推出TPU,其目标便是为企业提供Nvidia GPU的替代品。前阵子的Google I/O 2024上,谷歌推出第六代TPU,性能有显著提升。
与TPU v5e相比,Trillium TPU峰值计算性能提高了4.7倍。为了实现更高的性能,谷歌投入了大量精力扩展执行计算的矩阵乘法单元或MXU的大小,并提高了其整体时钟速度。此外,Trillium GPU的高带宽内存容量和带宽是原来的两倍,而芯片间互连带宽也增加了一倍。
为了让客户更放心的替代英伟达,谷歌也在谋划先让自己完全用TPU替换掉GPU,可能在今年底停止外部AI算力芯片的采购,转而完全依赖自研的TPU。谷歌的算力总量,结合自研TPU和先前的芯片采购,预计可达全球算力总量的25%。
总之,现在的英伟达四面楚歌,谁都想取代他。随着特供版接连被围堵,国内市场似乎对英伟达不买账了,转向采购国产芯片。但在AI芯片市场上,从来没有什么稳赚不赔,前两天就有一家日本AI芯片厂商宣布解散。可以从此看出,TPU的立足之本,便是更好的能效比和软件生态,在此方向上,国产在路上。
参考文献
[1]杭州经信:解锁制造新图景④|AI训练芯片为大模型装上“智商”进化器.2024.7.22.https://mp.weixin.qq.com/s/JQGP5AMZFiOYSaM-Nfmupw
[2]北京大学:https://ele.pku.edu.cn/info/1012/3201.htm
相关推荐
TPU芯片:国内面对AI大模型的另一种解法
从谷歌TPU,看AI芯片的未来
谷歌“AI周边”大放送:想做大模型时代的大平台?
谷歌千元级TPU芯片发布,TensorFlow更换Logo推出2.0最新版
为大模型定制一颗芯片?
为什么谷歌不学英伟达,卖自己的TPU?
OpenAI突袭谷歌TPU芯片人才,奥特曼亲自下手,准备从微软另起炉灶?
大模型时代,AI芯片「破局」之战
谷歌TPU秘密武器,6小时完成芯片布局,新AI算法登Nature
谷歌的自研芯片帝国
网址: TPU芯片:国内面对AI大模型的另一种解法 http://www.xishuta.com/newsview122698.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95075
- 2人类唯一的出路:变成人工智能 20224
- 3报告:抖音海外版下载量突破1 20035
- 4移动办公如何高效?谷歌研究了 19450
- 5人类唯一的出路: 变成人工智 19339
- 62023年起,银行存取款迎来 10235
- 7网传比亚迪一员工泄露华为机密 8354
- 8五一来了,大数据杀熟又想来, 7777
- 9滴滴出行被投诉价格操纵,网约 7401
- 10顶风作案?金山WPS被指套娃 7163



