苹果的新AI,是如何“练”成的?
前言
Siri 终于变身“AI Siri”,万众期待的 Apple Intelligence 来了。
伴随 Apple Intelligence 上线 iOS 18、iPadOS 18 和 macOS Sequoia,苹果也发布了自家大模型的技术报告,公布了大量技术细节,十分受业界关注。
据介绍,Apple Intelligence 包含了多个高效能的生成模型,它们快速、高效,专为用户日常任务而设计,并能即时适应用户当前的活动。构建到 Apple Intelligence 中的基础模型已经为用户体验进行了优化,如写作和润色文本、优先级排序和汇总通知、为与家人和朋友的对话创建有趣的图片,以及采取应用内操作以简化跨应用交互。
在技术报告中,苹果团队详细介绍了其中两个模型——一个约 30 亿参数的语言模型 AFM(Apple Foundation Model),以及一个更大的、基于服务器的 AFM-server 语言模型——是如何构建和适配的,从而高效、准确地执行专业任务。

图|AFM 的模型概况
这两个基础模型是苹果创建的更大生成模型家族的一部分,用于支持用户和开发者;这包括一个基于 AFM 语言模型的编程模型,用于构建 Xcode 中的智能;以及一个扩散模型,帮助用户在视觉上表达自己,如在信息应用中。
AFM的性能怎么样?
AFM 在开发过程中经历了严格的评估,评估结果表明,模型在预训练、后训练和特定任务上都表现出色,并符合苹果的核心价值观和负责任 AI 原则。
1. 预训练评估
苹果团队使用 HELM MMLU、HELMLite 和 OpenLLM 等公开评估基准,评估了 AFM 模型的语言理解和推理能力。结果显示,AFM 模型在多个评估指标上取得了优异的成绩,展现了强大的语言理解和推理能力,为后续的后训练和特定任务应用奠定了基础。
2. 后训练评估
苹果团队结合人类评估和自动评估基准,评估了 AFM 模型的通用能力和特定能力,比如指令遵循、工具使用和写作。评估结果如下:
人类评估:AFM 模型在多个任务上媲美或优于其他开源和商业模型,表明模型能够理解和遵循复杂指令,并生成高质量的文本。
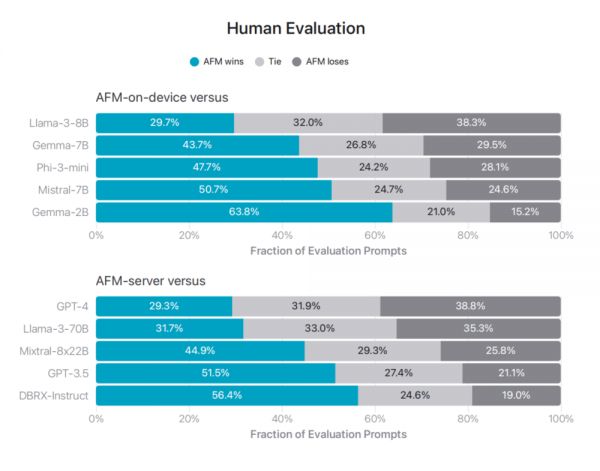
图|AFM 模型与其他开源模型和商业模型对比,人类评分者更喜欢 AFM 模型。
研究团队在神经元描述范式上评估 MAIA,研究显示,MAIA 在真实模型和合成神经元数据集上均取得了优异的描述效果,预测能力优于基线方法,并与人类专家相当。
指令遵循评估:AFM 模型在 IFEval 和 AlpacaEval 2.0 LC 等基准上取得了优异的成绩,表明模型能够有效地理解和遵循指令。
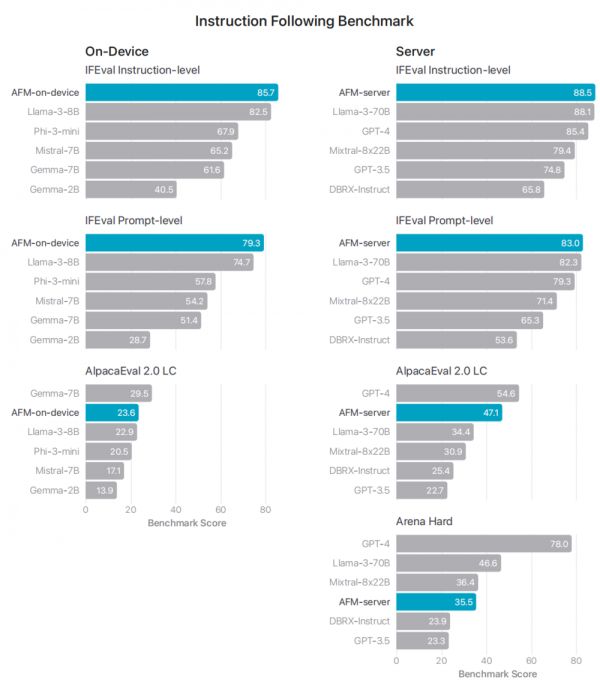
图|AFM 模型和相关模型的指令遵循能力比较,使用 IFEval 测量,值越高表示能力越好。
工具使用评估:AFM 模型在 Berkeley Function Calling Leaderboard 基准上取得了最佳的整体准确率,表明模型能够有效地使用工具。
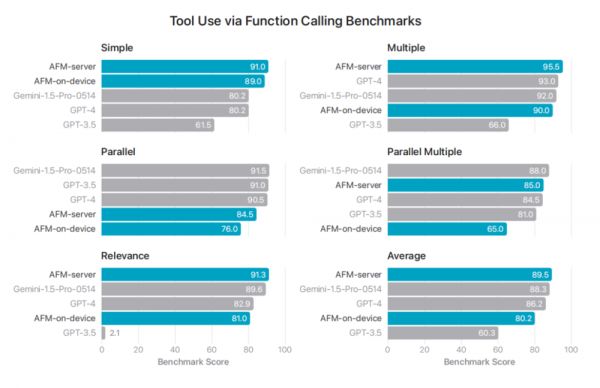
图|AFM-server 达到了最佳的整体精度,优于 Gemini-1.5-Pro-Preview-0514 和 GPT-4。
写作评估:AFM 模型在内部总结和写作基准上表现出色,表明模型能够生成流畅和高质量的文本。
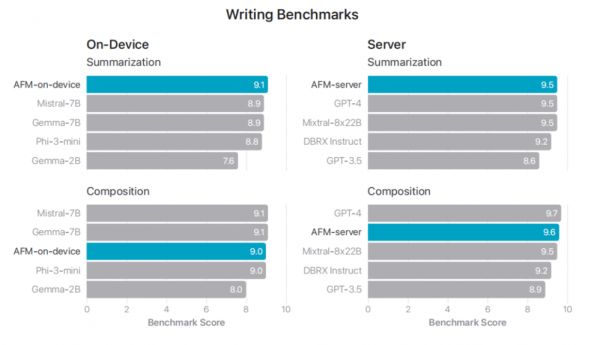
图 | AFM 与一些最杰出的模型以及较小规模的开源模型进行比较。与Gemma-7B和Mistral-7B相比,AFM-on-device 可以实现相当或更好的性能。AFM-server 显著优于 dbrx - directive,与 GPT-3.5 和 GPT-4相当。
数学评估:AFM 模型在 GSM8K 和 MATH 等基准上取得了优异的成绩,表明模型能够有效地解决数学问题。
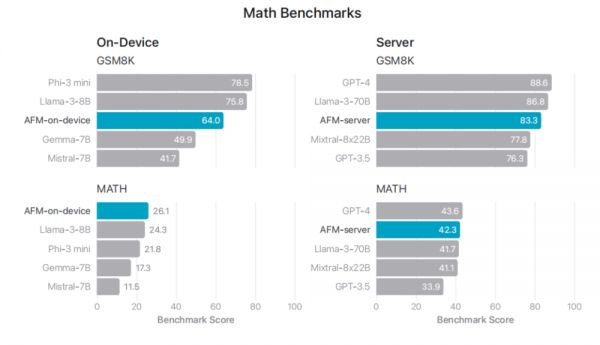
图|研究团队比较了训练后 AFM 在数学基准上的表现,包括 GSM8K 和 math。AFM-on-device 的性能明显优于 Mistral-7B 和 Gemma-7B。
此外,研究团队还对模型进行了特定任务评估和安全性评估。他们使用人类评估和特定任务评估基准,评估 AFM 模型在特定任务上的表现,例如邮件摘要、消息摘要和通知摘要。根据评估结果,AFM 模型在邮件摘要、消息摘要、通知摘要方面的表现在多个方面优于其他模型,比如准确性、完整性和可读性。
在安全性方面,研究团队使用对抗性数据集和人类评估,评估 AFM 模型对有害内容和敏感话题的抵抗力。评估结果显示,AFM 模型对对抗性数据和敏感话题表现出了良好的抵抗力,在一定程度上避免了产生有害或不当的响应。
AFM是如何“练”成的
1. 架构
与大多主流模型一样,AFM 模型基于 Transformer 架构,但也采用了一些特定的设计选择来提高效率和性能。主要组成部分如下:
Transformer 模块:AFM 使用标准的 Transformer 模块,包括多头注意力机制和前馈神经网络。
共享输入/输出嵌入矩阵:该设计减少了模型参数的数量,提高了内存效率。
预归一化和 RMSNorm:这些技术提高了训练的稳定性,并帮助模型学习更复杂的模式。
查询/键归一化:该技术进一步提高了训练的稳定性。
分组查询注意力(GQA):GQA 机制减少了内存占用,并提高了计算效率。
SwiGLU 激活函数:该激活函数提高了模型的效率。
RoPE 位置嵌入:RoPE 机制支持长文本的编码,并提高了模型对上下文的表示能力。

图|AFM-on-device 具有 3072 个参数,适用于在设备上进行推理。它使用了 26 个 Transformer 层,每个层包含 128 个头,8 个查询/键头和 24 个查询头。
2. 预训练
AFM 模型的预训练过程旨在训练强大的语言模型,以支持 Apple Intelligence 系统的各种功能。AFM 模型使用 AXLearn 框架在 Cloud TPU 群上训练,该框架支持大规模模型和序列长度的训练,并提供了高效的训练和推理性能。
AFM 预训练数据集由多种类型的优质数据组成,包括:
网页内容:使用 Applebot 爬取的公开可用信息,并进行了过滤。
授权数据集:从出版商获得的高质量数据集,提供多样化的长文本数据。
代码:从 GitHub 上获取的开源代码数据,覆盖多种编程语言。
数学:包含数学问题、论坛、博客、教程和研讨会等数学内容的网页数据。
公共数据集:经过评估和筛选的公开可用数据集。
AFM 预训练分为三个阶段:
核心阶段:使用最大规模的数据集进行训练,主要目标是学习基础的语言知识和模式。
持续阶段:在核心阶段的基础上,增加代码和数学数据,并降低网页数据的权重,以进一步扩展模型的知识范围。
上下文扩展阶段:在持续阶段的基础上,使用更长的序列长度和合成长文本数据,以提高模型对长文本的处理能力。
3. 后训练
AFM 在预训练阶段获得了强大的语言理解能力,但为了将其应用于特定任务,比如邮件摘要、消息摘要和通知摘要,还需要进行后训练。包括:
监督微调(SFT):
数据收集:使用人类标注数据和合成数据,确保数据质量多样且涵盖各种自然语言使用场景。
数据混合:仔细选择和组合人类数据和合成数据,形成高质量的数据混合。
微调方法:使用 LoRA 适配器对模型进行微调,仅调整适配器参数,保留模型的通用知识。
基于人类反馈的强化学习(RLHF):
奖励模型:使用人类偏好数据训练奖励模型,评估模型响应的质量。
迭代教学委员会(iTeC):使用多种偏好优化算法,包括拒绝采样、直接偏好优化和在线强化学习,迭代地改进模型。
在线 RLHF 算法(MDLOO):使用 Mirror Descent 策略优化和 Leave-One-Out 优势估计器来最大化奖励,提高模型质量。
后训练的优势:
模型质量提升:后训练显著提高了 AFM 模型的质量和性能,使其在特定任务上表现出色。
符合苹果核心价值观和负责任 AI 原则:后训练过程充分考虑了数据质量、安全性和有害内容的过滤,确保模型符合苹果的核心价值观和负责任 AI 原则。
可扩展性:后训练方法可扩展到其他任务,使 AFM 模型能够支持更多 Apple Intelligence 功能。
4. 推理优化
AFM 不仅需要具备强大的语言理解能力,还需要能够高效地运行在 iPhone、iPad 和 Mac 等设备上,以及 Apple 硅服务器上的 Private Cloud Compute。为了实现这一目标,苹果开发了一系列优化技术,以确保 AFM 模型在特定任务上的高效运行,同时保持整体模型质量。
优化方法:
模型量化:使用 4 位量化技术对 AFM 模型进行量化,显著降低模型大小和推理成本。
精度恢复适配器:使用 LoRA 适配器来恢复量化模型的精度,使其接近未量化模型的表现。
混合精度量化:使用 4 位和 2 位量化精度对模型的各个层进行量化,进一步降低内存占用,同时保持模型质量。
交互式模型分析:使用 Talaria 工具分析模型的延迟和功耗,指导比特率选择,优化模型性能。
运行时可替换的适配器:使用 LoRA 适配器来微调模型,使其能够针对特定任务进行调整,同时保持模型的通用知识。
优化案例——邮件摘要:
数据收集:收集包含电子邮件、消息和通知摘要的输入数据,并进行数据清洗和去重。
合成摘要生成:使用 AFM 服务器生成符合产品要求的合成摘要,并使用规则和模型进行过滤,确保数据质量。
提示注入:将 AFM 服务器生成的摘要添加到训练数据中,帮助 AFM 设备模型更好地理解和生成摘要。
此外,Apple Intelligence 遵循一系列负责任的 AI 原则,包括赋能用户、代表用户、谨慎设计、保护隐私等。在这篇技术报告中,苹果反驳了有关其采用道德上有问题的方法来训练某些模型的指控,重申它没有使用私人用户数据,而是将公开可用的数据和授权数据结合起来用于 Apple Intelligence。他们强调, AFM 模型的训练数据是以“负责任”的方式获取的。
更多详细内容,请查看技术报告:https://machinelearning.apple.com/papers/apple_intelligence_foundation_language_models.pdf
本文来自微信公众号:学术头条,作者:马雪薇
相关推荐
苹果的新AI,是如何“练”成的?
AI面试盛行,韩国求职者烧钱上补习班:练习用眼睛微笑
直播跟练的受伤风险,是时候被重视了
AI面试催生韩国新型补习班:200元一小时,面对摄像头练习用眼睛微笑
为什么苹果认为自己是 AI 的领导者?(上)
彭练矛院士:没有芯片就没有中国未来的现代化
十年,苹果是如何改变耳机行业规则的?
老会员权益如今要买更贵畅练卡才能享受?Keep回应质疑
英特尔是如何丢掉苹果生意的?
为什么苹果认为自己是 AI 的领导者?(下)
网址: 苹果的新AI,是如何“练”成的? http://www.xishuta.com/newsview123197.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95228
- 2人类唯一的出路:变成人工智能 21183
- 3报告:抖音海外版下载量突破1 21148
- 4移动办公如何高效?谷歌研究了 20339
- 5人类唯一的出路: 变成人工智 20338
- 62023年起,银行存取款迎来 10336
- 7五一来了,大数据杀熟又想来, 8596
- 8网传比亚迪一员工泄露华为机密 8505
- 9滴滴出行被投诉价格操纵,网约 8215
- 10顶风作案?金山WPS被指套娃 7230



