对话理想智驾郎咸朋、贾鹏,一个后进生,怎么提前交卷了?

智能驾驶,一场昂贵的竞赛开始。决定排位、决定未来。
文丨程曼祺 窦亚娟
编辑丨宋玮
先后任职于特斯拉和小鹏的谷俊丽博士说,中国智能驾驶研发进度至少落后特斯拉 1.5 -2 年。理想智驾副总裁郎咸朋认为,差距没那么大,产品体验上理想最多落后半年。
理想强调自己做智驾的优势是车多、数据多,小鹏创始人何小鹏则说:“如果有人说它有很多车、很多数据” 就能做好自动驾驶,“千万别信,绝对是胡扯”。
价格战还在燃烧,中国汽车新势力们又集体挤入了一个新战场——智能驾驶,充满分歧、争议、你追我赶。
不是所有车企都买得起这张入场券。智能驾驶 30 亿研发投入起步,逐年递增。理想说,现在一年租卡要 10 亿人民币,将来要 10 亿美元。
新势力如此疯狂、不甘落后,是因为他们看到了特斯拉 FSD V12(特斯拉 2024 年 1 月开始大规模推送的完全自动驾驶新版本)的巨大进步,也看到了智驾能力对消费决策的影响。去年 9 月,华为宣布年底推出全国都能开的无图方案,问界同期围绕智驾猛烈宣传。短短一个月,一直徘徊在数千销量的问界月销量破万,年底更是冲上 3 万大关。
在华为宣布激进智驾计划不久,理想召开 2023 秋季战略会,明确智能驾驶是核心战略,绝不能输。CEO 李想说,“2024 年要成为智驾的绝对头部”。
此后,理想加速迭代,双线并进:一边使用 NPN(Neural Prior Net,先验神经算法,使用部分道路和地图的先验信息,帮助识别道路特征,减少对高精地图的依赖),终于赶在去年底开了百城 NOA;同期从去年 10 月预研无图 NOA,四个月后开始千人内测,今年 7 月全量推送。
来到今年夏季,没有喘息时间,新势力们投入下一场战役:端到端(end to end),一个大部分消费者不明就里的技术术语,成为兵家必争之地。
端到端的意义在于,它让智能驾驶研发进入了 AI 时代——不再依赖大量人工编程,只要用更多数据训练模型,系统就会不断变强,表现可能超过人类司机。马斯克认为,这让人类离完全自动驾驶近了一大截。
理想在本周开启了 “端到端 +VLM(视觉语言大模型)” 新架构的千人内测,称这是更先进的 one model 和全球首个双系统落地。One model 指自动驾驶的感知和决策模块都由一个模型完成,输入的是传感器数据,输出的是驾驶轨迹。
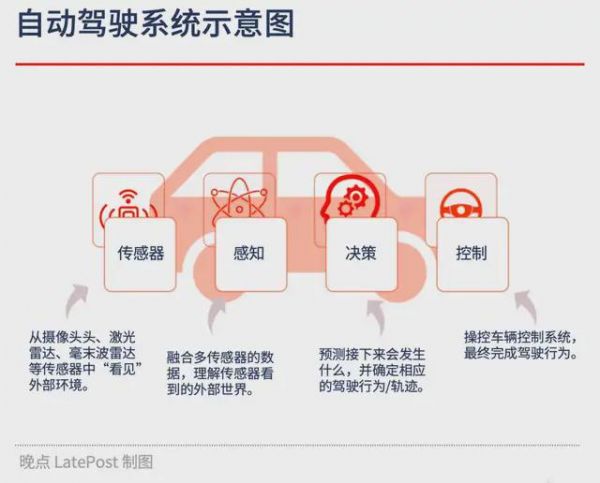
自动驾驶有感知、规划与决策和控制三个模块,靠感知 “看”,靠决策 “思考” 怎么开车,靠控制模块完成驾驶行为。端到端技术就是从感知到决策,整个过程都用一个大模型实现。
这前后,蔚来 7 月初宣布量产端到端 AEB(紧急制动功能);小鹏本周重申自己是全球唯二实现端到端大模型量产落地的车企,另一家当然是特斯拉。如果算上供应商,今年还有华为与 Momenta 完成了端到端上车。
理想 2021 年才开始自研智能驾驶,比蔚来、小鹏晚两年。理想目前的进度,就好比一个后进生突然知道了答案,然后提前交了卷。
在这个时刻,我们对话了理想智能驾驶副总裁郎咸朋与理想智能驾驶技术研发负责人贾鹏。他们解释了这一切是如何实现的。
郎咸朋是一位爱用希腊神话命名关键项目的智驾一号位,一位模式识别与智能系统博士。他在理想完成的战役包括 “卫城”“伊利亚特”“泰坦”。2018 年,郎咸朋从百度加入理想任自动驾驶总监,后晋升副总裁。
贾鹏是一位年轻的技术研发负责人,曾是英伟达中国第一批做智能驾驶的人。他看到这家芯片巨头最早提出了自动驾驶的端到端、大模型,但发现只有车企才能把这些真正落地。
全力投入端到端的各家公司,路线表述和进展不尽相同,但共享一个野心、一个技术方向:最终实现 L4 级自动驾驶。
我们看到今天关于智能驾驶、端到端的狂热,既是因为技术信仰,也是为了竞争,为了用户心智和销量榜。
这是一场昂贵的竞赛。代价不仅是招人、买 GPU、训练模型的巨额开支。在 L4 真正实现之前,坐在司机位置的还是人,安全、可靠、稳定,这些才是用户对当前智能驾驶的检验标准。
后进生交卷
《晚点》:理想 2021 年才开始自研智能驾驶,比小鹏、蔚来都晚,一直是追赶状态。直到今年,直接从 NPN 切到无图 NOA,再到本周端到端开始千人内测。有人评论说,怎么后进生突然就提前交卷了?
郎咸朋:可能是屌丝逆袭。
我们去年一年就做了三代,从有图到 “先验信息” NPN,到无图,都在做。今年 6 月又把端到端架构验证出来,同时还提出了快慢系统架构,快系统是端到端,是面对日常驾驶快速处理信息的能力;慢系统是 VLM (视觉语言模型),是面对复杂场景的能力。
而且我们的端到端是 one model,输入是传感器,输出是行驶轨迹,全部由一个模型实现,中间没有任何规则。除了特斯拉,其他整车厂都只是在某个环节实现端到端。
《晚点》:你们的第一个关键进展——从 NPN 方案到无图,去年 10 月开始验证,今年 2 月内测,7 月就全量推送了。只用了 4 个月时间就切换完成,听上去很不可思议,怎么做到的?
郎咸朋:我们就是比别人效率高、速度快。比如中间省了很多的决策流程。从决定要做,到定方案,到把团队拉起来,可能也就一周时间。如果是传统车企,也许项目启动就要 3 个月,
《晚点》:你们为此舍弃了什么?
郎咸朋:可能是个人的休息吧。大家都知道公司的目标,我们没有任何退路。
贾鹏:也习惯了。我 2020 年从英伟达离职加入理想,一直以来我们面临的环境就是——我们是个后进生,天天被家长骂。
《晚点》:这个家长是李想吗?
贾鹏:是用户。
《晚点》:看起来你们智驾技术路线的方向很清晰——就是学特斯拉,那具体是怎么学的?
郎咸朋:大家会认为技术研发需要时间,但往往需要的不是研发时间,而是试错时间。特斯拉确实是一个很好的标杆,他试错走不通的地方,我们就不走了。
特斯拉 FSD 的演进和迭代让我们看到了无图也能成功。选 NPN 还是无图?既然特斯拉跑出来了,那我们就选无图,所以我们几个月就实现了切换。
但特斯拉对我们最大的启发,还是在于怎么去走自动驾驶研发从 0 到 1 、从 1 到 10 的阶段。特斯拉最早也是用供应商 Mobileye 的方案做智能驾驶,很快发现供应商不能满足它的要求,所以从 2016 年开始自研,中间经历一个震荡期,最终达到了 Mobileye 的效果。2019 年,它自研 FSD 芯片,有硬件来支撑它做 AI 的研发,此后就是端到端的出现,它本质上是用 AI 的能力来做智能驾驶。
《晚点》:V12 的核心是端到端,事实上特斯拉 2023 年初推送的 V11 版本就实现了无图,当时你们为什么不直接学呢?
郎咸朋:这就像大家都觉得高数很重要,但你要不会四则运算,怎么能学好高数?
我和吴新宙(前小鹏智能驾驶负责人)也交流过这一点。我们都认为整个过程可以加速,但不能跳过。大家都在做端到端,但从有图、NPN、无图到端到端,每一步都不能省。跳过这些步骤,实际上你跳过了很多技术的理解。
如果去年下半年我们不试图做百城 NOA,那我们对于 NPN 跑不通就不会有这么清晰的认识。仅从规模看,全国高速只有三四十万公里,但城市有几百万公里,要想全国都铺开,这个图根本做不完。
《晚点》:但你之前说,大的判断不是能不能的问题,而是敢不敢做的问题。
郎咸朋:也不是不能做,如果真要做,就是打资源战。反正要搞就是上千人去铺规模。
贾鹏:我们内部开玩笑,说这条路最后会把自己做成一个地图公司。
《晚点》:那后来加速靠的是什么?
郎咸朋:组织效率一直是理想的优势。从 NPN 到无图,再到端到端,这几次都是很大的切换,但我们说切就切了。
研发和交付的配合效率很重要,技术要突破上限,难的是做选择,但做完选择后,交付要负责提升下限。去年下半年公司战略会,李想明确提出 RD(研发)和 PD(量产交付)一起做,研发思路明确后,我们团队内部永远都有 PD、RD 两条线。去年 11、12 月做无图,到今年 1 月,差不多可以交付了, RD 立刻转 PD,2 月先给 5.1 版本,继续交付,到现在 5.2 版本,然后 Beta 1、Beta 2、Beta 3,把它打磨好。
贾鹏:我认为是快速试错。我们的流程是:找一个封闭区域,短时间来验证范式,先达到这个范式能达到的上限,一个区域跑通就立马往外扩,同步加上安全兜底策略,之后慢慢铺开。全国去试这个范式是不是 work,不 work 就迅速加数据、改策略。到产品验收环节,从鸟蛋到早鸟到千人内测,我们让用户和我们一起去做产品的测试和迭代。
《晚点》:听起来很冒险,你们当时怎么就确定用这个流程就一定能跑通?
郎咸朋:风险很大,但我们一直是这么过来的。
我们第一款车理想 ONE 用了 Mobileye 的智驾方案。后来做理想 ONE 改款快交付时,Mobileye 说不合作了,不能给白盒交付。那时已经是 2021 年,我们认为如果这时候还不掌握辅助驾驶技术,肯定不行。所以做了一个艰难的决定——自己做。如果做不出来,那是我们能力差。但如果说今天怂了,还是用了供应商,那我们可能就没有将来了。
我们 “被迫” 摸索出一条很不一样的研发流程, 5 月交付,3 月必须出原型,到 2021 年 5 月 25 日,理想 ONE 发布会前一天,我们还有一堆 bug 没解,发布会当天上午才最终改完。这就是我们现在流程的雏形:先小面积验证,然后提升能力、修补 bug、稳定质量。
当时团队只有 100 人,第一个月就走了 40 人。有人跟我说,“别人用一、两年才能交付的东西,凭什么我们三个月就能交付?你不要自欺欺人。”
《晚点》:同样是无图,小鹏去年开城速度比你们今年慢,测试人员更多,小鹏说每去一个地方开城,都要实地测试至少四轮,这才能保证安全,不给用户开盲盒。你们这套快速研发、交付,再从鸟蛋到千人内测的方法,怎么保证安全?
郎咸朋:现在自动驾驶系统的评测方式跟之前很不一样。之前的智驾,先设计功能再研发,要一项项测试功能来验证。而现在数据驱动的自动驾驶,是以能力而不是功能为核心,“能力” 只能通过 “考试” 来评估。
我们用世界模型 + 影子模式来考试。世界模型重建和生成真实场景,车在里面跑,相当于模拟考,评估研发过程中的能力。通过模拟考试后,我们用早鸟 、内测车辆,影子模式做实车考试,如果考不过,就持续迭代,直到通过为止。
《晚点》:如果命题作文有答案,那理想能跑得比别人快,但答案不会永远有,多数技术问题可能是开放式问题。
郎咸朋:大家今天看到的是所谓命题作文我们追赶速度比较快,但追上之后我们可能更快,因为整个体系搭建起来了。
不是说我们 2021 年才开始自研,就可以交付比同行差的产品。从我们交付的第一天开始,就要跟班上最优秀的学生去比成绩。这也意味着,如果用对方的学习方法去学,我一定学不过他。所以我们就是要用自己的方式做事。
濒临无人区
《晚点》:端到端不是新概念,英伟达、Waymo 几年前都提出过端到端,但为什么把这件事做成并推广的是特斯拉?
贾鹏:因为它既提出了技术的思路,又给大家看到了使用效果。
郎咸朋:特斯拉的很多人是因为相信才看见,但更多人是因为看见才相信。
《晚点》:如果没有特斯拉在前面探路,理想会落后更长时间吗?
郎咸朋:算法上我们是晚,因为原先条件不足、资源不够。但数据积累和研发体系建设上并不晚,所以才能赶上。
从一开始,我们就清楚特斯拉的理念——数据驱动是对的,那我们就按照它来搭建研发底层。在 2019 年第一代理想 ONE 上,我们做了数据闭环系统——波塞冬,一套采集、挖掘、标注、训练数据的工具链。我们当时没有资源自研,但也在 Mobileye 的摄像头旁边多放了一个摄像头,这就是来收集和分析问题的。
举个例子,路测遇到问题,传统方法是随车人员记下来,再开到同样场景复现。我们是遇到问题,数据能同步回到后台了,测试还没结束,数据已经被分析,甚至问题已经开始被解决。传统企业要几天甚至一周做的事,我们可能一小时就完成了。
数据积累上,理想用户使用自动驾驶的总里程数已经超过 20 亿公里,其中近 10 亿公里是用的 NOA。特斯拉做得早,保有量也更大,里程数更长。
《晚点》:这更多是李想的坚持,还是你的?
郎咸朋:我们是一致的。我 2018 年来理想面试时李想问我,最终实现 L4,要解决的最主要问题是什么?我说是数据——没有数据闭环体系,不管是样本还是问题,分析效率都不高。人可以挖,算法可以搞,但数据问题不解决,一定做不好。
《晚点》:蔚来前不久刚量产端到端 AEB;小鹏本周开发布会说它们是全球唯二自研量产端到端的车企,另一家毫无疑问是特斯拉。各家的端到端到底有什么区别?
贾鹏:目前小鹏 5.2 的架构跟我们 7 月刚全量推的无图类似,感知是一个模型,决策是一个模型,中间再串起来,他们刚把这事做完。华为已经发布的 ADS 3.0 也是分段的端到端。
特斯拉则是从感知到决策都是一个模型。而我们的最新版本也实现了将感知到决策融合成一个模型,本周已经开启了千人测试。
《晚点》:感知、决策 one model 的端到端和分段式端到端的区别是什么?是谁比谁更领先吗?
郎咸朋:还是看目标是什么,分段式更适合 L2 + 级辅助驾驶,one model 才真正可以做 L3、L4 级自动驾驶。
因为分段端到端虽然在决策模块内部用数据驱动取代了一些规则,但整个流程里还是有规则,本质上和以前的智能驾驶架构类似,研发流程也类似,仍然分模块。而 one model 里不含任何规则,传感器数据进来,规划轨迹出来,是纯数据驱动。
《晚点》:可否一句话解释下端到端的最大价值是什么?
贾鹏:从用户角度,驾驶行为更像人了,细节操控更丝滑。研发上看,迭代效率更高。
郎咸朋:端到端是第一次用纯数据驱动来做自动驾驶,研发方式从以功能、场景出发变成了提升系统能力,真正进入了人工智能时代:只要让系统不断变强,它就会有超出预期的表现。
《晚点》:如何用更短时间训练出一个更聪明的模型?
贾鹏:数据,尤其是优质数据很重要。我们从 80 万车主的 200 亿公里数据中筛出最好的数据,训练了超过 100 万公里的数据,年底超过 500 万公里。
第二是训练方法,在模仿学习的基础上,我们加了强化学习,让模型知道什么是错的。
郎咸朋:最后是算力,理想有等同 5000 张 A100、A800 算力的 GPU。如果租卡,一年要 10 亿,这需要健康的利润来支持。
《晚点》:你们反复强调有数据所以能赶上,但本周何小鹏说,“如果有人说它有很多车、很多数据” 就能做好自动驾驶,“千万别信,绝对是胡扯”。
郎咸朋:我们也希望大家能客观地对待产品。但现在还处于爱迪生和特斯拉证明直流电好还是交流电好的时代,一个人把交流电用作电刑,另一个演示用交流电穿越人体也没事。
《晚点》:特斯拉的数据最多,算力投入也最大,这是否意味着它无法被超越?
贾鹏:目前特斯拉的限制是硬件,因为 HW 3.0(特斯拉第三代智能驾驶硬件)的算力是 144 TOPS,能支持的模型参数不会特别大,加太多数据,会出现 “灾难性遗忘”。这也是为什么 V12.4 更新后,有些场景变好了,有些却变差了,如空旷场景开始乱变道。
《晚点》:但换一个角度来看,FSD 能够在 2018 年上车的 HW 3.0 上丝滑跑起来,说明特斯拉软硬结合的能力很强。
贾鹏:确实很强。但我认为 FSD 进入中国有挑战。一是美国道路大部分相对简单;二是特斯拉在美国能拿到道路拓扑信息,而这在国内是拿不到的。所以 FSD 其实是轻图,而我们是真的无图,没有任何地图先验信息。
《晚点》:今年 7 月,先后任职过特斯拉和小鹏的谷俊丽博士说,“特斯拉的研发进度领先国内智能驾驶 1.5-2 年”。你是否同意?
郎咸朋:不太同意。
无图版本代表了有规则的上限。端到端代表了数据驱动的上限,它中间没有任何规则,就一个模型。但无图、端到端都走不到自动驾驶,因为它还是在解决长尾问题,没遇到过的情况就处理不了。要走到 L4,必须让系统学会处理未知场景。这个能力,我们认为必须用 VLM 来解决,而不是端到端。
所以我们的新架构是端到端 +VLM,前者是对应快思考的系统 1——处理要快速反应的大部分驾驶场景;后者是做慢思考和长时决策的系统 2——它能学到一些常识以应对未知情况,比如识别没见过的非常规红绿灯,各种形式的潮汐车道标识,学校周边特征等等,提前告诉车不能进入或要减速。
系统 1 + 系统 2,理想是第一个做这个架构的。
贾鹏:从公开信息看,特斯拉目前的技术架构没有 VLM。
《晚点》:英伟达和软银投资的英国自动驾驶公司 Wayve 今年 4 月发布的 Lingo-2 ,也是在车端加入了语言大模型,你们是受 Wayve 启发吗?
郎咸朋:它没有系统 1 ,Wayve 的 Lingo-2 和云端模型都是多模态大语言模型,类似 VLM。它的思路是一个模型解决系统 1 加系统 2 。但在量产时会发现,Orin 的算力摆在那儿,支撑不了系统 2 的大模型。Wayve 能做,是因为它不是量产车,在车后面背了一个服务器才能跑 Lingo-2。
贾鹏:我们最早受的启发是 Google 的机器人系统 RT-1 和 RT-2,它是一个 VLA(Visual-Language-action) 模型,最后行为也是由模型输出。它可能是一个终局:如果我硬件足够好,理论上能把 VLA 跑到实时。
《晚点》:所以灵感不来自汽车行业,来自机器人?
郎咸朋:因为我们把自动驾驶看作一个人工智能的典型应用。这套双系统方案实际是提出了一个通用具身智能架构,它在车上是自动驾驶,在机器人上就是智能机器人。
《晚点》:你们提出的 “端到端 +VLM” 架构,前者来自特斯拉,后者来自 Google RT 的启发,而且 VLM 的论文还是和清华大学合作的。是否说明现阶段你们更习惯组合创新?
郎咸朋:和清华赵行老师合作时,我们是观点相互碰撞,也不是他提观点,我们来实现。
《晚点》:你们把自动驾驶视为通用具身智能的一部分,它是否也有 Scaling Laws ,以及你是否相信 Scaling Laws?
郎咸朋:端到端的 Scaling Laws 不会特别明显,因为参数有限,可能千万级数据就喂满了,再加就开始遗忘,我们已经能从特斯拉 FSD V12.4 上看到这个现象。
但 VLM 的 Scaling Laws 肯定存在,它可以做到几百亿甚至几千亿参数。只要数据够多、参数够大,性能就会涨。这条路对我们吸引力很大。
《晚点》:如果 VLM 能在车上跑得足够快、延时足够低,是否就不需要系统 1 了?
贾鹏:理论上是的。现在我们 VLM 在车上能做到 3.4 HZ(注:HZ 是单位时间内周期性事件发生的次数,数值越大,时延越小),它是一个 2.2B(22 亿)参数的模型,但要能替代端到端,需要跑到十几 HZ,对应 100-200 毫秒的时延,这是人的反应速度。某些场景对时延的要求还会更高,比如 AEB(紧急制动)。
《晚点》:这套架构有多独特?华为也在讲系统 1 和 2;小鹏的 “大语言模型 XBrain” 也是处理未知场景的,是否类似你们说的系统 2?
郎咸朋:我们是第一个在业界提出双系统的;以及我们的 VLM 是在量产的车端芯片 Orin X 上部署,之前其它公司类似的尝试是在工控机上。
不管是 one model 的端到端还是 VLM,这个架构已经交付,在做千人测试了。
《晚点》:你们也提到在做云端的世界模型,这在整个架构中起到什么作用?
贾鹏:这是我们的系统 3。云端世界模型做两件事:一是 VLM 可以用云端的世界模型蒸馏出来,就是先在云端训练一个超大模型,比如 Meta 最近发布的 400 B 参数的 Lamma 3.1,再去蒸馏一个 8 B 的模型,这比从头训练 8 B 模型效果更好。
二是世界模型可以考察系统 1、系统 2 的能力。我们在做端到端无图的过程中发现全国验证非常难,有 1000 万公里的路,之前只能铺人力去测。
《晚点》:特斯拉也在研究世界模型。但行业需要这么多世界模型吗?毕竟我们只有一个世界。
郎咸朋:0 到 1 的过程中,会有很多路线和尝试。就像我们也不需要这么多电动车品牌,但高峰时有几百家。
《晚点》:之前行业内认为中国智驾的排名是华为、Momenta、小鹏、理想,这个排名什么时候会改写?以及下一个改变智驾排名的赛点是什么?
郎咸朋:已经改写了。再往后,各团队都会到无人区:无图解决了全国都能开,端到端会让全国都能开得还不错,那接下来就是 L4。
量产 L4 到底怎么做?一开始肯定是百花齐放,再收敛。但大家也不会再回到同一个起跑线,因为数据和算力差距只会越来越大。
复盘理想智驾六次关键战役
《晚点》:听说你很会给战役取名。
郎咸朋:我们对待取名是认真的。
智驾团队打过六大关键战役,第一战是卫城计划,然后是伊利亚特计划和奥德赛计划,荷马史诗上下部;接着泰坦计划、金苹果计划,泰坦之战后,新神打败了旧神。再到现在的达摩克里斯计划,也就是端到端项目,这个项目有挑战、很危险,如果做不好,达摩克里斯之剑会掉下来。
《晚点》:每次战役遇到的最大挑战和收获各是什么?
郎咸朋:
卫城计划是我们第一个自研项目——在 2021 年 5 月发布的理想 ONE 上交付 AEB、ACC 自适应巡航、车道保持这些基础功能,这些技术都很成熟,但给我们的时间只有 90 天,拼的就是强有力的执行。从那一天开始,我们就想着如何才能快速追上别人。2022 年我们开始伊利亚特计划 —— 在 L9 车型上交付 Orin X 项目。之前在地平线 J3 上的算法不适用了, 我们要在 Orin 上要重新开发系统。还赶上疫情,芯片断供,博世无法提供足够的角毫米波雷达芯片。我们不得不做了一个选择,去掉角毫米波雷达,用纯视觉方案做盲区检测、避障等功能。最后用三个月交付了方案,比友商交付 Orin 的时间早了几个月。和伊利亚特同期,贾鹏负责开发基于地平线 J5 的 Pro 平台,也就是奥德赛计划。最大挑战是人少。当时整个团队只有 500 人,2021 年,小鹏和蔚来都有上千人,华为当时号称 2000 多人。2023 年,我们的 Orin 平台已经比较稳定了,在硬件上追平了,下一场仗我们判断是城市 NOA,能赢的才有资格进入第一梯队。这个叫泰坦计划。金苹果计划是在 2023 年上海车展上提出的百城 NOA,也出自希腊神话,是大力神赫拉克里斯去找金苹果,但金苹果被百头巨龙看守,我们要得到金苹果,就要把巨龙的头一个个砍下来,把百城一个个都解决掉。达摩克里斯计划是今年开始研发的端到端项目,意味着做不好达摩克里斯之剑就会掉落。
《晚点》:其他公司现在也没有拿掉四颗角毫米波雷达,你们考虑过拿掉后对系统的安全性影响么?
郎咸朋:我们拿掉毫米波雷达有两个原因,一是保交付,当时博世角雷达芯片断供,不得不作出选择。要么用视觉代替雷达,要么就交付不出来。二是技术选择,当时特斯拉要走纯视觉的方案,视觉更接近于人类认知周围环境的能力。如果车身上同时有角毫米波雷达和视觉传感器,两者发生分歧时,需要用到人写的规则逻辑去判断它,难免会有错误。
还有一个附加的好处是技术降本,省了大概 5 个亿。
但要用几个摄像头来替代角毫米波雷达,技术难度和风险是非常大的。我们做了很多测试,最终结果是准确率和成功率比带角雷达的还略微增加了一点点。
《晚点》:你提到之前资源不够的问题。现在这个问题解决了吗?
郎咸朋:我们去年九月的秋季战略会提出了 “三大战略”,第一战略就是智能驾驶战略。所以下半年开始招了好多人。公司的要求和预期也提升了,不管是百城还是别的,需要赶上头部梯队。
《晚点》:所以此前智驾并不是理想的核心战略?
郎咸朋:这次是正式明确了。
《晚点》:这是因为你们意识到,智驾对产品销量的影响,和华为的距离在拉大?
贾鹏:是的,所以 2023 年秋季战略会确定理想今年要做到智驾的绝对头部,因为我们判断整个行业的买车逻辑会变成智驾为先。
《晚点》:六次战役,你们沉淀下来的东西是什么?
郎咸朋:想赢,就要用怎么赢来思考。也就是以终为始,找到必要性,想清楚解决一个问题要做到什么。去掉角雷达、NPN 切无图都是例子。
《晚点》:理想难道不是以竞争为出发点吗?比如去年百城计划的赛跑。
郎咸朋:去年华为宣布要推出全国都能开的 ADS(华为的无图 NOA 方案) 之后,我们过于强调竞争和对标华为的一些指标,如接管率等,反而忽视了用户体验,这也是今年春季战略会上被大家批评的一点。
后来我们反思,所有产品验收与交付应该以用户评价为出发点。
《晚点》:你们怎么设计智驾研发和产品组织来应对今天的高强度竞争?
郎咸朋:我们的智能驾驶是一个横纵结合的组织,我负责纵向业务部门,做研发和交付。但最终产品的组织、执行和经营,包括外部竞争对标和研发资源投入,都是由智能驾驶 PDT(Product Development Team,跨职能的产品开发团队)来操盘。
我会参与一些人才战略和计划制定,一旦计划定下来,我们就坚定地执行好。
《晚点》:去年秋季理想大规模招人,智驾团队从 700 多人扩张到 1000 多人,今年 5 月又裁了两三百人,6 月又召回一些关键岗位员工。短时间从招人到裁人再到召回,说明了什么?
郎咸朋:本质是技术迭代了。以前智驾系统里有大量规则,需要人工编程、管理进度、做测试。但端到端更多是 AI 模型,上述岗位大幅减少。后来再召回少数人,更多还是基于业务需求进行的调整。其实特斯拉智驾团队一直是 200 到 300 人,交付了全球最大的自动驾驶车队。
《晚点》:特斯拉的端到端,是一个印度技术人员 Dhaval Shroff 在内部最先提出来,自下而上被采纳。理想的研发组织是否有自下而上创新的土壤?
郎咸朋:其实 VLM 这些想法就是来自于我们的预研和研发团队。我们也没有很早规划出来这么一个双系统。
《晚点》:怎么评价你们的人才储备?小鹏之前有吴新宙,蔚来有任少卿。有人认为,理想智驾团队一直缺少这种技术大牛。
郎咸朋:到了这个级别,技术能力和拿结果的能力都重要。我们的技术 leader,包括我、贾鹏、王佳佳,很多都是 14、15 年就在做自动驾驶。我们现在新招的人也比较强,今年 200 多个应届生大多是 QS100(英国 QS 世界高校排名)前 50 的学生。而且我们有算力、数据储备,这是人才成长的土壤。
《晚点》:你虽然进入智驾领域很早,但最初在百度是做地图相关的算法,不是智能驾驶本身。
郎咸朋:百度的经历很重要。那段经历让我在管理上遇到任何事不会怂,我相信找到合适方法,一定可以用更短时间做出更好的效果。
我在百度第一个项目和理想第一代自研相似,都是周期特别紧。我 2013 年 4 月底加入百度,4 个月后就要在百度大会上上线街景项目。这个团队一开始只有 4 个人,最后我们做到了大会前一天的零点完成了上线。
这里面两个关键。一是要用新技术。做街景,要模糊车牌和人脸,当年的常规做法是人工来做;而我们用了视觉算法,更快,更准确,还省了一大批人。另一个就是数据。这个算法我们本来想和百度 IDL 的余凯(后创立地平线)、倪凯(后创立禾多)团队合作,但他们的东西在这个场景也只有 86% 的准确率,我们后来自己做到了车牌 99%、人脸 97%,关键就是我们标了大几万张数据。
算法上我们肯定不如他们,那是世界上算法最好的一批人。但这只是 80 分到 90 分的差距;而场景数据上,我们多了一个数量级。所以后来面试时,李想问我,要解决自动驾驶,最主要的问题是什么?我会说是数据。
《晚点》:这几年中,很多人顶不住压力、或者不相信理想能做成这件事选择离职,为什么最后你们留下了?
郎咸朋:我们这群人就是想把 L4 这件事做成,而我认为这件事只有在理想才能做到。
贾鹏:来理想之前我在英伟达待了 5 年,无论端到端还是大模型,是英伟达最早提出来,但当时就是不落地。到了车企,终于有机会把自动驾驶做成一个闭环了,很爽。
题图来源:《天才枪手》
相关推荐
对话理想智驾郎咸朋、贾鹏,一个后进生,怎么提前交卷了?
自研自动驾驶:理想放弃幻想,面对dirty work
李想“认错”:理想ONE有缺陷,做产品学乔布斯不学特斯拉
理想汽车,认错了
36氪独家 | 理想汽车CTO王凯将离职,联创马东辉执掌研发大权
城市NOA智驾,一场把车卖得更贵的阳谋?
理想汽车渴望的新爆品,被延后到下个季度
小鹏智驾负责人吴新宙将离职 将重构智能团队
对话 Momenta 曹旭东:超越智驾的摩尔定律
让智驾从“能用”到“好用”,小鹏能否实现对华为的反超?
网址: 对话理想智驾郎咸朋、贾鹏,一个后进生,怎么提前交卷了? http://www.xishuta.com/newsview123300.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95263
- 2人类唯一的出路:变成人工智能 21515
- 3报告:抖音海外版下载量突破1 21493
- 4移动办公如何高效?谷歌研究了 20661
- 5人类唯一的出路: 变成人工智 20652
- 62023年起,银行存取款迎来 10369
- 7五一来了,大数据杀熟又想来, 8890
- 8网传比亚迪一员工泄露华为机密 8561
- 9滴滴出行被投诉价格操纵,网约 8513
- 10顶风作案?金山WPS被指套娃 7255



