对话RWKV作者彭博:单枪匹马挑战Transformer的神秘怪才
一个人,待在家里,“懒散”的有一搭没一搭,训练一个要挑战已经“一统世界”的Transformer的模型。这听起来足够夸张。
还有更夸张的。
这个模型的雏形比ChatGPT引爆世界更早出现,然后不停迭代,OpenAI也注意到了它,向作者发出邀请,被立刻回绝,理由是OpenAI不open。而当全世界最聪明的头脑都纷纷涌入这个竞技场和名利场后,这个基本没有露过面的作者宣称:
“现在的AI太简单了,傻瓜都可以做出来。”
而且,他还说,只有他才知道实现AGI的答案。
这个模型就是RWKV,这个人就是彭博。

彭博的知乎个人页面
和今天在大模型领域最常见到的名校计算机专业毕业,论文等身,师出名门,光鲜亮丽背景的天之骄子们不同。彭博是个16岁考上港大物理专业,然后在对冲基金做量化交易,后来又自己创业,制造和售卖一些台灯和音箱产品的“怪人”。以至于,在一些社交媒体上有人直接称呼他为“民科”。
然而与这些争议同时发生的事情是,RWKV这个模型被人提到的频率在增加,他是少有的从架构上做创新的中国开发者,RWKV的开源生态在壮大,社区自发为它写了论文,在“无法作弊的模型评测”Uncheatable Eval排行榜中,最新的RWKV-6-World 14B的综合评测分数比llama2 13B更强。它是首个被Huggingface引入transformer库的RNN模型。

更有意思的是,这个模型背后的很多思想,彭博作为设计者在鼓吹的很多主张,也在被更多人呼应。比如transformer那篇论文的几个作者在最近开始告诫人们世界需要更好的模型架构,比如前OpenAI著名研究员Andrej Karpathy也在提醒人们RNN的方法依然充满潜力。
我在最近见到了这名深居简出的神秘人物,和他聊了聊RWKV的故事。
在对话中,我问他,你觉得自己是堂吉诃德还是牛顿。
他回答我:
都是。
以下为对话实录。
一、RWKV,在Transformer的时代复兴RNN
硅星人:作为RWKV的唯一作者,我们先聊聊RWKV这个架构吧。从诞生到最近的RWKV-6,每个版本都发生了哪些迭代,这些架构上的修改是怎么想到的?
彭博:我们目前最新正在优化的版本是RWKV-7。
在RWKV之前,2020年时,我看了看GPT,立即发现有两个明显的改进方向:
一是引入显式decay。后续在2021年有一个ALiBi提出了类似的方法。
二是Token-shift。或者说,短卷积。当时我叫time-mixing,后来EleutherAI的lucidrains说可以叫token-shift。我设计Token-shift是为了改善in-context learning。后续在2022年有其它人指出这个,他们称之为induction head。
那么,2020年,我在github发布了一个minGPT-tuned显示了这些改进的显著效果,然后在EleutherAI的discord宣传了一下,大家一开始半信半疑,因为许多人宣称的改进实际是无效的,但大家测试后发现确实有效,于是大家就结识了。
时至今日,这两个改进是大多数“非transformer模型”必备的技巧。例如SSM团队在2021年的S4时没加token-shift,到2022年的H3就加了短卷积,后续的Mamba当然也加了。
RWKV-1是我将这两种技巧加入Apple的Attention Free Transformer,使得AFT实现了显著的性能提升。RWKV-2是我在看到ALiBi用了和我类似的显式decay后,突然想到,如果使用exponential decay,就可以将RWKV写成RNN。这是令人愉快的时刻之一。然后我测试发现,性能确实挺好。
RWKV-3使用更全面的token-shift,效果显著。RWKV-4是解决RWKV-3的数值稳定性问题,也是我想的一个解决方法。最近的xLSTM使用了与我类似的解决方法。RWKV-4是我很满意的架构,因为它的state非常小,令人惊讶。因此我认为,在模型充分大时(例如1T以上参数),RWKV-4将很有竞争力。
到了RWKV-5,在它之前,我一直专注于在“最小的state下实现最大的性能”。因为,在同样的参数下,虽然state越大性能越好,但是state越小越通往真正的智能。
后来微软的RetNet说用Linear Transformer作为基础(这个的state大几十几百倍)性能好,然后我想,大多数人还是喜欢看性能好,而且在现阶段,性能好的也更实用。所以我把我的技巧加进Linear Transformer,效果当然显著比RetNet好,这就是RWKV-5。
RWKV-6有data-dependent dynamic decay,这是传统RNN的东西。这个我在RWKV-2的时候就计划做,在我github上RWKV-2的介绍图就写了,但是写CUDA费事,就一直没做。后来听说Mamba做了,那么我就做呗,我用自己的方法。如果你看过我CUDA,我的方法有点意思。
RWKV-7是delta rule的改进,这其实也是几十年前的东西。这在RWKV-6之后就一直在我的计划里,有时做做。后来看到有人做了(DeltaNet,TTT),那我就做完呗,也用自己的方法。其实这些如果对自己狠一点,几天就做了。
硅星人:信息量好大,可以先介绍一下最初你做的这两个改进么,什么是显性Decay?以及我记得Time Mixing之外你还做了Channel Mixing。
彭博:显性Decay就是说你的信息是有一个Decay(衰退)的过程。为什么要Decay呢,首先因为离得越近的信息可能是越重要的,越远的信息它没有那么重要。还有一个原因就是,如果你不把旧的信息Decay掉,信息会积压在一起,会分不出、分不清主次,会有这样的问题。所以我们发现Decay是特别重要的一个东西。
对。我还做了Channel mixing。它比较像Transformer中的那个全连接网络FFN。Transformer其实是两部分,一部分attention,一部分是FFN。FFN对应我们的Channel Mixing,然后Attention对于我们的time mixing,也就是说我们把它的attention机制换成了Rwkv机制,这是最大的一个区别。
硅星人:当时各种架构里没有么还是?
彭博:之前没有人加。我也很奇怪了,然后我加进去,效果就明显好很多了。
硅星人:2020年么。
彭博:2020年我开始做模型。当时我看了下Transformer,看了下GPT3。觉得可以加了。那时候是GPT3之后,我看了它的效果觉得它当时已经很厉害了,后续空间非常大。只不过普通人当时用不上,还没有出现Chat这种让普通人用上的形式,大家不知道。
然后我就去研究了一下AI写小说。因为那时的话我的主要兴趣就在于写小说。我对于AI写小说非常感兴趣,因为这首先很有意思,第二它是一个很高的检验标准,第三我想看看AI它有没有能力写出真正有力量的东西。
应该说我们离这个目标还是非常远的吧。
硅星人:目前还很远。
彭博:你让GPT-4写小说都是很垃圾的。
硅星人:我看你那段时间也在自己做一些Chatbot,甚至是文生图的小产品。
彭博:对对对,应该说我对生成式AI非常感兴趣,因为我们通常认为这是创造力的一部分,关键是AI它有没有可能出现新的东西?
但目前来说我看还是不可能。目前来说它更像是把现有的东西做一些——按照大家说的话就是“尸体碎片”。其实真的是“尸体碎片”。
硅星人:排列组合。
彭博:对,排列组合。
硅星人:那最初2020年做这个RWKV1的时候,相当于它还是一个Transformer的改进,并不是你后来强调的RNN。
彭博:我当时先研究Transformer,后来2021年看了苹果的AFT论文,我觉得它的想法很好有前途,但他们自己调的效果不好,加了我的效果之后就好了。
然后到RWKV二代,我发现可以把它变成一个RNN的形式。
也就是一开始的话,我们不是说先要做RNN然后把它做出来的,其实这样做可能反而做不出来。我反而是在把attention机制做一些优化的时候,发现它可以写成一个RNN,然后才注意到这个事情。
硅星人:可以写成RNN意味着什么。
彭博:Attention的公式可以写成RNN的话,那RNN有很多优点就可以被利用了。当然就像我说的,原始的Transformer其实也可以写成RNN,不过它的state会越来越大,也就是KV Cache。因为你现在去研究一下做工程的,做大规模推理和部署的话,他都会说KV Cache一开始会越来越大,占的显存越来越多,所以它运行越来越慢,都是因为KV Cache。
我一开始我并没有意识到RNN是正确的,是发现Transformer它可以写成RNN,而且效果还很好后,我就知道RNN肯定就是正确的。
因为RNN在形式上是要elegant很多的。
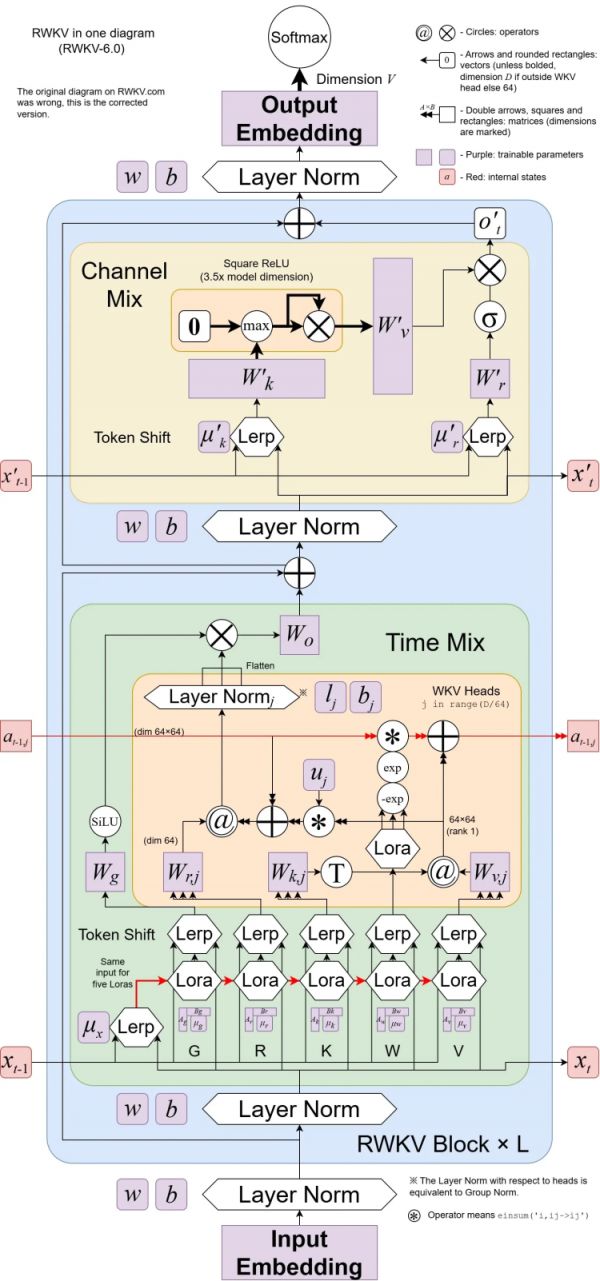
RWKV-6的架构图
硅星人:所以,RWKV到底是一个复兴了RNN的架构,还是一个融合了Transformer和RNN的架构,还是可以认为是一个全新的创新架构?
彭博:RWKV是RNN的复兴。
我是相信RNN是正确的,但现在的RNN远远没有做到它真正的水平,它的上限其实是非常高的,现在我们还远远没有到那个地步,还有很多空间。因为RNN更接近人脑和宇宙的运作方式。例如,在物理上,宇宙的下一状态只与上一状态有关,这是所谓的locality和causality,量子场论遵循这一原则。
实际Transformer是一种state(KV cache)不断增大的RNN。这显而易见,近期也有人说过。所以,严格说,RWKV是state大小恒定的RNN。
硅星人:我问的就挺抽象,你似乎用了一个更高维的理论解释了本来就挺抽象的问题。这是一个物理的概念是么?
彭博:物理比较准确。
硅星人:这是个什么理论?
彭博:是这样的。这个理论在说你可以认为没有超距作用,没有超关系作用。
你看不看科幻小说?比如你看三体里面,提到光锥,一切都在光锥之内,如果在它之外就影响不到,在这个瞬间这个位置发生的事情,它只能影响到它附近的东西和时空。
那么你看Transformer就不同,它每个字都要和前面的字比对一遍,其实距离很长的。而RNN的话,它每个字它只和它现在本地的状态来比对,所以它就具有这种局域性的特性。
硅星人:所以这在物理学上是主流观点?
彭博:我们做一个东西的话,我希望它不仅仅是符合人类的认知,还要符合这个世界的规律,到目前为止物理的一个基础假设是这样子的。而你要做一个理论的话,可能是要建立在一定的基础之上,你要做一些假设,因为我们对这个世界的认知只能靠假设。假设和实际吻合,那么就是一个好的假设。
硅星人:够深刻的。我尝试去理解的话,人们讨论RNN和Transformer的时候似乎更具体的在讨论Self-Attention对RNN的替代。它们本质都是如何建立token之间的联系,也就是你说的state,RWKV是不是相当于是从这个角度入手,本质上是提出了一个新的公式新的计算方法,在继续保留transfomer attention的并行特性下,用更少的资源记录更关键甚至更长的关系信息。背后是因为RNN符合你对世界的理解。
彭博:对。其实这里是有个很重要的区别,就是Transformer它的每个token都要和前面的token去建立联系,就说离得很远的token它也要去建立一遍联系。就每生成一个字都要来一遍这样过程,但我们的话其实不是token和token之间联系,而是token和state之间建立联系。这是很大的区别。
硅星人:其实Attention机制里也有Layer,是Layer之间做联系。
彭博:对没错。Layer之间是一层层往下走的。
但我们更像人。像人类在说话的时候,我们只和我们的大脑的状态之间有联系,其实我们自己说的话我们也忘记了,但是我们为什么还可以继续说呢?就说明其实人也是这样工作的。
Transformer的state会越来越大,而RWKV的state是固定大小的。这个很重要,因为正是固定大小的限制让模型学到真正的东西,激发它的某种倾向和动力,去把世界压缩到它的state里去。
硅星人:你认为人的设计也是这样。
彭博:肯定是这样。肯定是token-state。忘记东西的话也可以记在手机里,记在草稿,全部都记到你脑子里是不对的。
硅星人:Transformer源自Attention is all you need这篇文章,今天其实很多人忘了当时的情况。当时这个标题本身其实是冲着RNN去的,强调当时人们做模型时都逃不开的RNN可以不再被需要。这在当时是个很大的突破,也宣告了RNN的落伍。
彭博:Attention是一个很有用的一个东西。因为当时他们主要解决的问题是翻译,翻译是个很典型的任务,每一个字都要找到前面对应的是哪个字,有时候可能对应的就是一些更加抽象的语法和结构了。如果你仔细想的话,很多任务都可以认为是翻译,所以它是特别适合翻译的一个思想。
那个时候Transformer起来更多是因为算力发展有一定轨迹,当时RNN没法很好用上算力,这个才是最重要的。现在大家知道RNN如何用上算力,攻守之势就要变。
硅星人:你的意思是它现在被大家认为是一个泛化通用的模型,但源头设计的时候是为了翻译这个任务,那RWKV有这么个任务么?
彭博:RWKV不是一个task drive的。但如果非要说task,我想说写小说。我认为这种是真正有创造力的东西很难,或者是解真正复杂的数学题。
硅星人:你也是脑子里想着这两个任务在设计模型么。
彭博:我认为任务可以分两种,一种是机械任务。翻译就是典型的机械任务。还有一种是非机械任务,就是开放式的问题,我关心开放式的问题,开放式问题我觉得才是真正的更加玄妙的东西。机械任务Transformer做的很好了,甚至混合模型都没有缺点了。我们做点别的。
我们目标是做真正的智能。现在都是过渡方案,以后一定是纯RWKV。
硅星人:野心很大,听下来你不只想挑战Transformer。那RWKV为什么能赢?
彭博:其一,RWKV始终是赛道的引领者。现在的“六代机”有Mamba Mamba2 GLA等等,都比RWKV-6弱。现在的“七代机”有DeltaNet TTT等等,都比RWKV-7弱。
其二,RWKV有明确的后续路线规划。常人觉得架构的空间不大,但在我看来,后续还有广阔的空间,可以再做很多代。
其三,RWKV走正确的道路。我们走社区和开源路线,我们与最广大的开发者站在一起。
其四,做事的人都知道,运气最重要。从经历看,我是个运气挺好的人,哈哈。
硅星人:有意思,一个个问你啊,你说RWKV的效果最强,有什么支撑吗?
彭博:其实很有意思,现在很多人发论文会把其他人的模型练的差一些,这个不好比。但最近你看到很多论文是用RWKV达到SOTA的结果。这些都没有跟我们联系过。
另外测试上,我自己也测过比它们强很多。有一个Uncheatable的评估集,它会选最新的数据,训练没有见过的数据。来测测看大家的语言建模能力。我们现在排在第三,我们肯定比Llama 3差,因为我们数据比它少。我们还会再加数据。
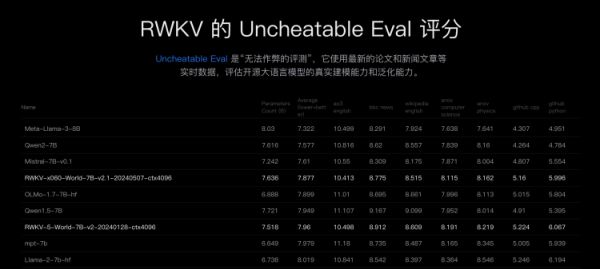
图源:RWKV官网
硅星人:我看你是在RWKV 5后开始注重效果的。
彭博:对,因为大家其实还是看效果的。普通人来说,你跟他说长线,说理念的话,大家不理的不懂的,对吧?还是看效果,能把效果做上去。
硅星人:目标变了。
彭博:为什么我们现在也会搞混合模型?这就是一种妥协了。当然现在是比较实用的东西,大家看效果的话都是实用。希望生态起来。
硅星人:人们提到RWKV,往往也会跟着提到Mamba,而且它们好像声量更大。
彭博:它是斯坦福做的。可以说他根正苗红,所以大家推他是正常的,他们也好不容易做出这个效果,他们也用了我一些东西。
硅星人:听说不怎么给RWKV Credit。
彭博:没事没事,我也用他东西,互相参考。当然它们写博客还是会提下RWKV的。
反正现在还是一个争夺定义权的过程,比如说Mamba想把一切都定义为SSM,对,那我就把一切都定义为RNN。对不对。

RWKV的社区合作撰写的论文
二、“我接下来在模型架构上要做的,他们做梦也想不到”
硅星人:当时ChatGPT出来的时候你的感受如何?
彭博:我觉得不意外。当时它出来的时候,春节时候,有人说它没那么大,我第一时间就说,它是个MOE模型。包括GPT4出来,在那些传闻出来之前我就说它是个1.75T的,肯定是十倍。因为我知道他们的风格,我猜得到他们怎么做的。
硅星人:OpenAI也是当时联系你的是么,当时是怎样的情况。
彭博:嗯春节的时候。一开始有OpenAI的人在微信群里找我,问我的邮箱。后来他们的外国同事发了一个邮件给我。
硅星人:负责训练的人还是招聘的人。
彭博:做技术的,应该不是特别高位,带领团队的中高层。他关注到我了,要招人。我第一时间就拒了。
我说如果你们做的是开源的我非常欢迎一起合作。但大家都知道你是做ClosedAI。
硅星人:后来他们还继续联系你了么。
彭博:那肯定没有,我都说他要是变成Open AI才行,他肯定不会变成Open的。
硅星人:所以当时ChatGPT出来全世界都惊讶,你不怎么惊讶。
彭博:当时我在知乎上说,这个事情很简单,大家马上追上来。你看Sora出来,我也说这个很简单的。
我跟你说,现在AI的问题就在于它太简单了,傻瓜都可以做出来。所以它是没有壁垒、没有门槛的事情,所以这也是我认为AI的商业模式有很大的问题的一个原因,因为太简单,就是无脑的堆算力,堆数据就行。
硅星人:Scaling Law?
彭博:这种power law其实完全符合物理和数学的直觉。就是幂律,在物理中是很重要和典型的东西,它关注的是临界的现象,我们关注在秩序和混沌之间的东西,它往往符合这种规律。我一点也不奇怪。
但现在它更是一种话术,告诉资源的供给者:只要你砸资源,就有收获。而且砸得越多,收获越多。如此有确定性的东西,大家喜欢。
然而,scaling law要砸的资源上升如此之快,与人类的学习所需资源是完全背离的。有些人试图论证人类学习所需的资源也不少,不值一驳。简而言之,AI不知道自己在学什么,人类知道自己在学什么。
硅星人:那你的想法是什么。
彭博:我觉得人的有些想法,真正的一些灵感,比如说有些超越时代的东西,或者说以前从来没有过的东西,人是可以有这样的东西,但是AI的话你想不到它怎么才能有,这种问题我其实知道要怎么解决,但是要很久以后。
我的一些想法可以说这个世界上没有一个人想得到。因为真的很奇怪。就不像是正常人类会想到的东西,正常人是做梦都想不到的。
硅星人:那前面RWKV的最初的想法算么。
彭博:那这当然不算,真正的我不会说出来的。
根据我的观察,我知道一些事情是全世界没有人知道的,这些东西要很久以后才能发挥出效果。好多年之后,需要时间。
硅星人:我看在知乎上你经常会发一些东西,而且给你已经带来不少争论了。
彭博:是的,这一直是我的风格。有人喜欢,有人不喜欢,没事,有人喜欢就行,黑红也是红。
做Transformer的人会黑我了。有人说我民科,是的我是民科,我就是民科。谢谢。
硅星人:你前面提到好几次你比较幸运。
彭博:我是比较幸运的,我举个例子。我16岁高考,后来本科在香港大学读物理系,毕业也没去找工作,一个朋友在图书馆遇到我,说有Hedge fund在找人他觉得我适合,无意中聊了几句,介绍我去那边聊了一下,对方问我有没有兴趣去他那里。就去了。随机的,我都不知道Hedge Fund做什么的,后来去了就做量化模型,来做一些交易,管理一些钱。
硅星人:你前面还提到好几次,有些工作懒得做就没做,后来发现别人做了赶快做了。这种比较松散的状态跟你要做的宏大目标会不会有落差啊。
彭博:维持一个张弛相结合的状态,因为你要做这种高强度的这个工作的时候,必须在一个紧绷的状态才能做的。平时可以散漫,平时散漫就是为了关键时刻可以紧绷。
另外我看到大家做了什么东西,我就可以也把它们做一下超过它们。因为我自己有未来的计划,我的东西就慢慢做呗,不用太紧绷。因为现在这些东西第一是没有那么重要,第二是要分清主次。
硅星人:那你作为公司CEO的一天是怎样度过的。
彭博:醒来,检查炼丹情况,处理微信和公司事务,看RWKV的国内外社群,看新论文和新动态,记录新想法,推进各种项目和合作,写重要的代码,散步,思考,跑步机或划船机,洗洗睡。
硅星人:你们公司现在的商业化进展如何,你们现在融资情况如何?
彭博:目前我们有2B的商业项目,也有2C的产品项目。正在进行第二轮融资。
我们的资源比起头部公司无疑有差距,但我们有自己的打法,擅长花小钱成大事,建立健康的现金流。因为我做过制造业公司,这些是写在基因里面的。
硅星人:最后聊聊接下来RWKV的进化重点吧。
彭博:重点是RWKV7和8,先把7做好。8会是一个非常有意思的东西。不能剧透,我只能说我后面做的方向是他们做梦也想不到的。我会按照计划,一代代迭代。
漫长的路,自己选的,自己走。
相关推荐
对话RWKV作者彭博:单枪匹马挑战Transformer的神秘怪才
那些挑战Transformer的模型架构都在做些什么?
黄仁勋对话Transformer论文的七位作者,都说了啥?
端侧大模型,手机厂商的下一次入口级机会
Transformer的后浪来了?
Transformer还不够好,它的作者决定让大模型自主进化
黄仁勋对话 Transformer 八子:大模型的起源、现在和未来
中国军团称霸阅读理解竞赛RACE:微信AI称王,高中生单枪匹马力压腾讯康奈尔联队
挑战 Transformer 霸权? Yan 架构竟以半价成本实现百万级参数大模型
对话彭永东:贝壳模式比阿里更重更复杂
网址: 对话RWKV作者彭博:单枪匹马挑战Transformer的神秘怪才 http://www.xishuta.com/newsview123569.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95185
- 2人类唯一的出路:变成人工智能 20919
- 3报告:抖音海外版下载量突破1 20809
- 4移动办公如何高效?谷歌研究了 20085
- 5人类唯一的出路: 变成人工智 20072
- 62023年起,银行存取款迎来 10313
- 7网传比亚迪一员工泄露华为机密 8460
- 8五一来了,大数据杀熟又想来, 8367
- 9滴滴出行被投诉价格操纵,网约 7989
- 10顶风作案?金山WPS被指套娃 7216



