OpenAI o1模型“我思故我在”,是怎么做到的?
OpenAI发布了第一组慢思考模型系列,会花上10~30秒的时间进行一番“长考”,然后给出答案。它在数学、编程、生物、物理等领域能回答更为复杂和多步骤的问题,并且还能展示出一些推理的过程,似乎增加了智能的“可解释性”。
这组模型不再是GPT系列,而是OpenAI的o1系列,用户可以通过ChatGPT或者API使用,目前推出了预览版的o1 Preview和轻型的o1 mini两个模型,绰号“草莓”。
OpenAI在关于该模型安全的系统报告中称,这一模型“更加接近AGI”。“随着我们的系统越来越接近通用人工智能(AGI),我们在模型开发方面变得更加谨慎,特别是在涉及灾难性风险的情况下。”
OpenAI称,这开创了大模型的一个新时代,这种会“思考”的大模型,以后将按照编号o1、o2、o3......发展下去。尽管OpenAI称以后还会保留GPT系列的番号,但有一点似乎已经比较明确了,沿着更大参数和更大数据做出更大模型的性价比短期内并不可行,即所谓那种依靠算力的“粗暴”运算,让智能不明觉厉地“涌现”的方法,短期内是无法取得突破,亦无补于解决大模型的幻觉问题。
远的不说,对电力和环境造成的直接影响就难以持续。就在模型发布的当天,英伟达的黄仁勋、OpenAI的奥特曼、微软总裁、谷歌总裁、AWS CEO、Anthropic创始人等跑到华盛顿,游说拜登政府建立一个工作小组,在能源和基础设施等方面为加快数据中心的部署提供支持。
一、扩展定律 (scaling law) 新范式
OpenAI负责推理研究的布朗(Noam Brown)称o1模型的发布为“新的扩展范式”,通过强化学习训练,在回答问题之前通过私人思维链进行“思考”。“它思考的时间越长,在推理任务上的表现就越好。这开辟了一个新的扩展维度。我们不再受预训练的限制。我们现在也可以扩展推理计算能力。” 通过训练,它们学会了完善思维过程,尝试不同的策略,并认识到自己的错误。
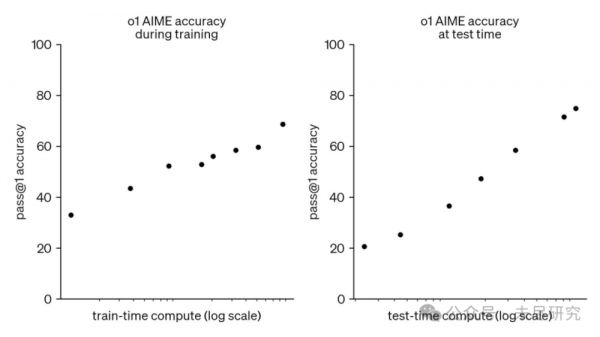
o1 的性能在训练时和测试时的计算量增加时,都能平稳提升。
在推理计算能力上进行扩展,布朗的想法更为大胆,“o1模型能够思考数秒,但我们的目标是让未来版本能够思考数小时、数天,甚至数周。推理成本会更高,但对于一种新的癌症药物,你愿意付出多少成本?对于突破性的电池技术呢?对于黎曼猜想的证明又如何?人工智能不仅仅可以是聊天机器人。”
这也是推理范式的一大转变,大模型从追求快速的推理、在一秒钟内吐出数百上千个token,到几十秒钟的“长考”,OpenAI为预训练扩展独木桥上的大模型,又开辟了一条路径。布朗是AI扑克游戏和外交游戏之王。他去年7月加入OpenAI,专门研究用强化学习加强大模型的推理能力。
英伟达科学家Jim Fan也认为,o1对扩展定律实现了一次范式转变:“我们终于看到推理时间扩展的范式在生产中得到普及和部署。正如Sutton在《苦涩的教训》中所说,只有两种技术可以无限扩展计算能力:学习和搜索。现在是时候将重点转移到后者了。”大量计算从预训练/后训练转移到服务推理。
OpenAI没有透露任何模型的细节,但显然草莓模型并不大。Fan认为,并不需要一个巨大的模型来进行推理。大量参数专用于记忆事实,以便在琐事问答等基准测试中表现良好。可以将推理从知识中分离出来,即一个小型的“推理核心”,知道如何调用浏览器和代码验证器等工具。预训练计算可能会减少。
当年思维链论文的作者之一、OpenAI的Jason Wei称,o1 mini能做对60%的美国奥数竞赛题,是小模型了不起的成就。实际上,推理的内核并不大,多数参数都是用于知识和记忆,在推理时可以剔除。
Wei认为,不要仅仅通过提示来展开思维链,而是使用强化学习训练模型以获得更好的思维链。“在深度学习的历史中,我们一直试图扩展训练计算能力,但思维链是一种可以在推理时进行扩展的自适应计算形式。”
二、“系统2”从研究到产品
关于大模型“慢思考”的研究方向,早在GPT-4去年3月份发布后,微软的那篇著名的“AGI的火花”论文,就已经指出,GPT-4之所长,类似于人类意识中的“系统1”,即直觉性和联想性较强的“快思考”,但是要消除幻觉,进行更缜密的推理和思考,还需要做到人类意识中的“系统2”,即“慢思考”。这些思路,来自去世不久的诺奖行为经济学家和心理学家卡尼曼的思想。
在推理环节进行扩展,加强上下文学习,早已经成为让大模型“思考”起来的重要研究方向。
在学术界最近对推理扩展定律的研究最近才有点热起来,如今年到最近的几篇论文:
《大语言猴子:通过重复采样扩展推理计算》(Large Language Monkeys: Scaling Inference Compute with Repeated Sampling. Brown et al.)DeepSeek-Coder在SWE-Bench上从一次采样的15.9%提高到250次采样的56%,超过了Sonnet-3.5。
《优化LLM测试时计算的扩展可能比扩展模型参数更有效》(Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters. Snell et al.)PaLM 2-S在测试时搜索中在MATH上击败了一个14倍大的模型。
《大语言模型(LLMs)无法进行规划,但可以在 LLM-Modulo 框架中帮助规划》(LLMs Can't Plan, But Can Help Planning in LLM-Modulo Frameworks,Kambhampati et al.)。
但OpenAI较早关注到了这一领域,从去年挖到布朗入局,到年底传出Q*模型却将实现AGI,都在一步步印证OpenAI提前在推理扩展方面布局。这再一次体现出OpenAI的过人之处,它总是能更深地洞察研究的前沿,更重要的是它能最先推出产品原型。
三、o1是如何“思考”的,一种机制的推测
Subbarao Kambhampati(కంభంపాటి సుబ్బారావు)是亚利桑那州立大学计算机教授。他上个月在ACL大会上发表了一个著名的演讲“大模型能推理和规划吗”,并提出了ABC方块问题,难住了所有的大模型,但布朗说o1模型解决了。
Kambhampati推测了草莓的工作机制,并称之为一个AlphaGo嵌入到大语言模型中,可以称之为GPTGo。他写了一段长推文:
其中提到了两个东西——“强化学习(RL)”和“私人思维链(Private CoT)”。想象你正试图将一个“广义AlphaGo”——我们称之为GPTGo——移植到底层LLM的token预测子状态上。
要做到这一点,你需要知道:
(1) GPTGo的“动作”是什么?对于AlphaGo,我们有围棋的落子。当任务仅仅是“扩展提示词”时,什么才是正确的“动作”?
(2) 它从哪里获得外部的成功/失败信号?对于AlphaGo,我们有模拟器/验证器给出成功/失败信号。将自我对弈的想法应用到通用AI代理时,最有趣的问题是它从哪里获得这个信号?
我猜测这些“动作”是自动生成的思维链(CoTs)(因此动作有很高的分支因子)。出于简化,让我们假设有一个生成CoT的LLM,它根据提示词生成这些CoTs。成功信号来自带有正确答案的训练数据。当扩展后的提示词似乎包含正确答案时(可能由LLM判断?),那就是成功。如果不是,则失败。
强化学习的任务是:给定原始问题提示词,生成并选择一个CoT,并用它继续扩展提示词(可能在每几个阶段后生成子目标CoTs)。获取该示例的最终成功/失败信号(对于你确实有答案的示例)。在大量带有答案的训练示例上循环,每个示例多次(带答案的训练示例可以来自基准测试,也可以来自带问题和解决方案的合成数据——使用外部求解器)。
让强化学习来搞定该示例中使用的CoTs的功劳-责任分配。将这个RL反馈信号纳入CoT生成器的权重中(?)。此时,你就有了一个比RL阶段之前更好的CoT生成器。
在推理阶段,你基本上可以进行展开(类似于原始AlphaGo)以进一步提高移动(“内部CoTs”)的有效性。展开越多,时间越长。
我猜测o1给出的(思维链)摘要只是“获胜路径”的摘要(根据它的判断)——而不是完整的展开树。
假设我在猜测o1的做法上是正确的,有几个推论:
1. 这至少可以比仅仅在合成数据上进行微调要好——我们通过学习移动(自动CoT)生成器来更好地利用数据。(想想行为克隆vs.强化学习)
2. 仍然不能保证提供的答案是“正确的”——它们可能在概率上稍微更正确(取决于训练数据)。如果你想要保证,即使在此基础上,你仍然需要某种LLM-Modulo方法。
3. 目前还不清楚是否有人真的愿意在推理过程中等待很长时间(等待10秒来连接10个单词的最后一个字母已经很痛苦了!)。那些愿意等待更长时间的人肯定会想要得到某种保证——而且对于许多这样的情况,有很多深层且狭窄的系统2可以使用。
4. 将o1称为LLM感觉有点像“忒修斯之船”——考虑到它与其他LLM模型(所有这些模型本质上都有教师强制训练和近乎实时的下一个token预测)的差异有多大。话虽如此,这确实是一种有趣的方法,可以在LLM基础上构建一个广义的系统2式组件——但没有保证。我认为我们需要了解这如何与其他获得系统2行为的努力相结合——包括为特定类别提供保证的LLM-Modulo。
四、“博士生水平”
OpenAI称,它在测试中发现,等到下一次模型更新,即o1的正式发布时,o1在物理、化学和生物学的挑战性基准任务中表现与博士生相当。
o1 在绝大多数以推理为主的任务上显著优于 GPT-4o。

在具有挑战性的推理基准测试中,o1 大幅优于 GPT-4o。实心柱显示 pass@1 准确率,阴影区域展示了在64个样本下的多数投票(共识)性能。
在许多以推理为主的基准测试中,o1 的表现可与人类专家相媲美。OpenAI在 AIME(美国中学生数学竞赛)上评估了数学表现,该考试旨在挑战美国最优秀的高中数学学生。在 2024 年的 AIME 考试中,GPT-4o 平均只解决了 12%(1.8/15)的问题。o1 在每个问题使用单个样本时平均解决了74%(11.1/15),在64个样本达成共识时为 83%(12.5/15),而在使用学习得分函数对1000个样本重新排名时达到了 93%(13.9/15)。13.9 分使其跻身全国前 500 名学生之列,并超过了美国数学奥林匹克的入围分数线。
GPQA Diamond是一项难度较高的智能基准测试,包括了化学、物理和生物学方面的专业知识。为了将模型与人类进行比较,OpenAI招募了拥有博士学位的专家来回答 GPQA Diamond 的问题,发现 o1 超越了这些人类专家的表现,成为首个在该基准测试中达到此水平的模型。这些结果并不意味着 o1 在所有方面都比博士更有能力——仅仅表明该模型在解决一些博士预期能够解决的问题上更为熟练。在其他几个机器学习基准测试中,o1 也超过了现有的最先进水平。启用视觉感知能力后,o1 在 MMMU 上获得了 78.2% 的得分,成为第一个能够与人类专家竞争的模型。它还在 57 个 MMLU 子类别中的 54 个上超过了 GPT-4o。
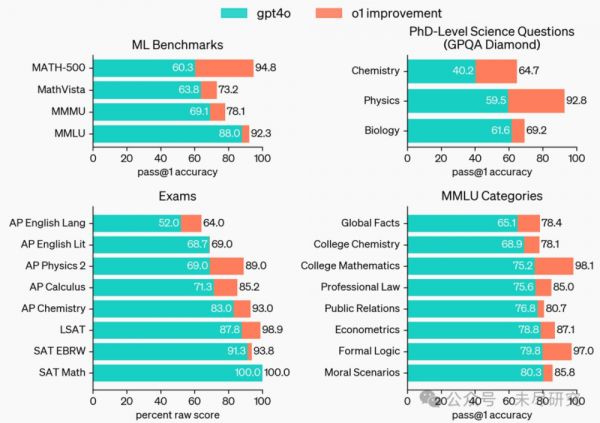
o1 在广泛的基准测试中优于 GPT-4o,包括57个 MMLU 子类别中的54个。为便于说明,我们展示了其中的七个。
o1着力开发的编程能力,在国际信息科技比赛中初步得到了验证。经过多次提交,模型的表现超过了金牌门槛。在模拟Codeforces的编程比赛中,表现也优于93%的选手。
大模型在编程中的应用,是最为看好的领域。o1强大的编程能力,使它有可能会加快产生完全自主的AI程序员。号称开发出首个AI码农的独角兽企业Devin,在使用了o1的API之后发现远胜于GPT-4o。其他特别适合的领域包括数学、物理、生命科学等。显然o1模型的用户在知识精英领域,尤其是可能在AI for Science应用方面首先取得突破,对于一个国家的研发创新能力有重大意义。
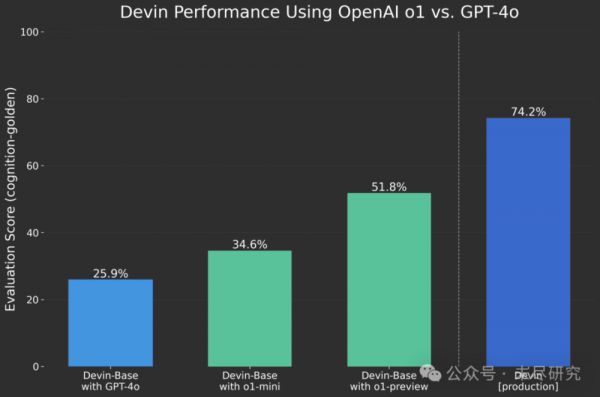
但o1也并非全面胜过GPT-4o。人类训练师查看了来自 o1-preview 和 GPT-4o 的匿名回复,并对他们更喜欢的回复进行了投票。在推理密集型的类别中,如数据分析、编程和数学,o1-preview 明显更受偏爱。然而,在某些自然语言任务中,o1-preview 并不占优,这表明它并不适合所有的应用场景。
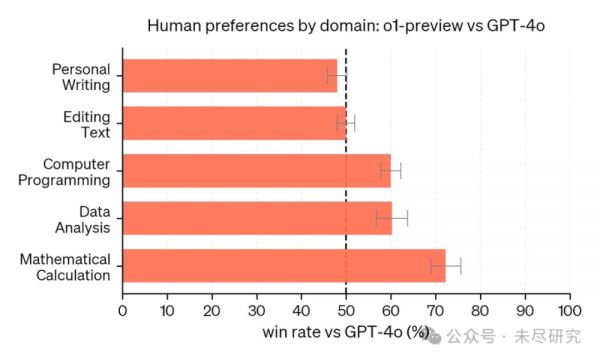
在人们更看重推理能力的领域,o1-preview 更受偏爱。
五、可解释性与安全
初步看来,“慢思考”通过提示展开思维链,再对思维链进行强化学习,在扩展中不断优化。通过展示思维链知道了所以然,对齐和安全性取得了新的进展。
OpenAI认为,将模型行为的政策整合到推理型的思维链中,是一种有效且稳健的方式来传授人类价值观和原则。通过对模型进行安全规则的教育,并让它学会在上下文中进行推理,推理能力直接提高了模型的稳健性:o1-preview 在关键的越狱评估以及最严格的内部评估中表现出显著改进,可以找到模型的边界,拒绝不安全请求。评估的详细结果可以在随附的系统卡中找到。
六、One more thing
OpenAI请了四位各学科顶级的人才来试用o1,它们是经济学教授,AI编程独角兽公司创始人,量子物理学家,遗传学家。
借鉴朋友的方法,我们也试了下:
用上小学时常玩的24点算术游戏,给它出了一道题: 用加减乘除法,用四个4算出个24。第一遍,它想了27秒做错了。第二遍,它想了29秒,

在做这道简单的算术题时,界面上会不停地显示出o1“正在思考”、“尝试不同方法”、“检验不同方案”、“使用不同的公式”、“改善方法”、“新的组合”、“纠正失误”等等,让用户直观地以为它正在勤奋严谨地思考,但也给人一种嘟嘟囔囔的感觉。
最后,GPT-5还会有吗?不知道,但最起码应该是休克了。
本文来自微信公众号:未尽研究,作者:未尽研究
相关推荐
“编程作为一个职业在今日终结”,OpenAI新模型o1的可怕之处
重磅!颠覆AI领域!OpenAI发布o1模型,解锁博士级科学难题
OpenAI最强模型o1,仍分不出“9.11和9.8哪个大”
Open AI发布新一代大模型“o1”:会像人类一样“花时间思考”
陶哲轩点评OpenAI o1 :像指导一个水平一般但不算太无能的研究生
OpenAI震撼发布新模型,Sam Altman:耐心时刻结束了
OpenAI「草莓」值万亿吗?
OpenAI“草莓”值万亿吗?
OpenAI刷屏的Sora模型,是如何做到这么强的?
ChatGPT搅翻科技圈后,OpenAI瞄准了人形机器人
网址: OpenAI o1模型“我思故我在”,是怎么做到的? http://www.xishuta.com/newsview125397.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95228
- 2人类唯一的出路:变成人工智能 21183
- 3报告:抖音海外版下载量突破1 21148
- 4移动办公如何高效?谷歌研究了 20339
- 5人类唯一的出路: 变成人工智 20338
- 62023年起,银行存取款迎来 10336
- 7五一来了,大数据杀熟又想来, 8596
- 8网传比亚迪一员工泄露华为机密 8505
- 9滴滴出行被投诉价格操纵,网约 8215
- 10顶风作案?金山WPS被指套娃 7230



