下注端到端:一场具身智能的谨慎豪赌
作者 | 赖文昕
编辑 | 陈彩娴
上个月末,世界机器人大会(WRC 2024)在北京刚刚结束,27 款人形机器人果然成为了会场中的主角。
夹爪叠衣服、做汉堡,灵巧手抓鸡蛋、演手舞,轮式进商超,双足满场逛......在这场硅基生命的大 party 里,人形机器人们的才艺都得到了充分的展示,特别是在操作能力上有了显著提升。
在具身智能时代,人形机器人代表着人类创造者对通用机器人终极形态的一大向往。
前文提到,为了在技术与商业落地上快人一步,具身智能玩家们在构型上对操作能力和移动能力各自做出取舍,其中上肢的操作能力因最能显现智能水平而被寄予厚望,逐渐成为学术圈与产业界的焦点,因此衍生了对二指夹爪、三指、五指灵巧手等多种末端执行器的探讨和落地。(插入链接)
然而,无论是否选择人形,在这场具身智能的较量中,除了最外显的躯壳,玩家们还需要解决最核心的问题:实现智能,攻克软件与硬件的耦合。
为了攻克这一关卡,具身智能领域的不同团队也有差异化思考,选择了不同的解决方案来支撑机器人的能力与智能水平。
技术路线如散开的蛛网蜿蜒开来——端到端的暴力美学是否可行?分层决策是否更有优势?「大脑」和「小脑」谁的优先级更高?
选手们已各就各位,剑指具身智能。
端到端的暴力美学
具身智能渐成显学后,机器人运行的四大板块(感知、规划决策、控制和执行),逐渐被类人化地划分为负责解决高层次认知或决策问题(high level)的「大脑」,以及负责基础层面的功能性问题(low level)的「小脑」。
两大系统各司其职又互相合作:「大脑」负责解析任务需求,整合来自传感器的信息,进行任务的细化和策略规划;「小脑」则专注于精细的运动控制,确保在「大脑」制定的策略指导下,机器人能够准确无误地执行动作并进行必要的调整。
这种划分方法往往被称为分层决策结构。不过,除了分层决策外,实现这一过程采用的另一种主要方法则是端到端架构。
端到端架构将「大脑」和「小脑」合为一体,通过单一的神经网络,直接将任务目标转化为控制信号,实现从输入到输出的无缝衔接,是一个黑盒。
特斯拉的 Optimus 机器人与谷歌的 RT-2 项目便是使用端到端模型的典型代表。
在端到端神经网络的加持下,Optimus 机器人能通过搭载的 2D 摄像头以及集成的触觉和压力感应器所收集的信息,直接生成用于驱动关节的指令序列,能完成分拣、放置、叠衣服等任务。

相似地,RT-2 项目旨在训练一个能够从视觉输入直接学习到动作输出的机器人模型。作为一个基于 Transformer 的模型,RT-2 在互联网上的海量数据中对视觉-语言模型(VLM)进行预训练,然后在具体的机器人任务上进行微调,结合视觉和动作数据,形成了一个能够将图像直接转换为控制指令的视觉-语言-动作模型(VLA),能完成将草莓放入特定的碗中、将足球移至篮球旁等任务。

RT-2 还展示出类人的学习和行动能力。传统机器人需要经过专门训练才能识别和处理垃圾,RT-2 则能从网络数据中学习垃圾这个抽象概念,理解吃完的薯片袋或香蕉皮是垃圾。识别垃圾后,在无动作训练的情况下,RT-2 还学会了如何扔垃圾。
而除了大厂外,目前也有少数海外团队在走端到端路线,比如由 Karol Hausman、Sergey Levine 和 Chelsea Finn 这三位 AI + Robotics 大牛创立的 Physical Intelligence。
这么看来,端到端模型的一步到位与强大的学习能力确实是通往具身智能的「康庄大道」,但为什么纵观全球,选择端到端方案的团队却寥寥无几呢?
数据和算力,是横在具身智能创企们探索端到端的两座大山——端到端的暴力美学需要通过海量的数据和算力来驱动,如此「烧钱」的做法绝非大多数企业,特别是小规模创业团队所可以模仿的。
一位具身智能创业者认为,端到端是未来机器人模型的重要组成部分,但不能完全依赖它,否则将面临诸多挑战。「端到端在机器人训练中主要依赖数据,但以现在的方法加上不足的数据,收敛性会非常差。」他指出,「端到端目前难以深入理解数据,如在处理多维物体抓取时可能无法准确把握其空间结构,需辅以物理知识以纠正。」
更早些时,端到端方案由特斯拉在自动驾驶领域引爆。到了今天,特斯拉在 Optimus 机器人的控制系统中也加上了全自动驾驶(FSD)控制器,以提高视觉处理和实时决策的能力,让机器人在无监督下自主完成复杂任务。更何况,Optimus 还能走进自家的汽车工厂实训,这意味着至少在工业场景下, Optimus 具有天然的数据沃土。
至于 RT-2,此工作建立在 RT-1 之上,后者使用 13 个机器人、耗时 17 个月,采集了 13 万条数据,使其在谷歌美国加州的办公室厨房环境中表现出色。再看 RT-2 的成员名单,团队一共有 54 人,人数超过不少具身智能初创企业。
而且,端到端方案存在的一个问题是,数据量的激增和频繁调用模型还会拖慢机器人的决策速度。
以 RT-2 为例,RT-2 集成了谷歌的具身多模态语言模型 PaLM-E,但在端到端架构下,机器人的决策速度有所降低,运行速度仅为 1~3 Hz,即反应时间可能长达 0.3 ~1 秒。这对于部分要求敏捷反应的任务而言略显迟缓,自然阻碍其在多变的实际场景下的应用潜力。
当然,如果海量数据和算力得以保障,又或者出现新的技术突破,大模型的暴力美学依旧很有希望在具身智能领域复现,因此端到端模型仍是业内公认通向具身智能的主要路径之一。
「我相信端到端、VLA 模型在 3~5 年内能有突破。」傅利叶创始人兼 CEO 顾捷对端到端的进展表示乐观,「因为算力、硬件本体以及以动作数据为核心的多模态数据会越来越多、越来越好。」
目前,千寻智能是国内少数选择端到端技术路线的具身智能创企。
首席科学家高阳是清华叉院助理教授,在伯克利读博士与博士后期间同 Pieter Abbeel、Trevor Darell 和 Sergey Levine 三位合作紧密。从 2016 年起,高阳便开始了端到端模型的研究,他指出,「端到端最大难点在于,这么大的模型如何训练才能够泛化,不只是简单预测动作,而是让预测变得可泛化,让神经网络变得部分可解释、有因果性等等。」
针对数据的质量与数量问题,高阳带领清华团队和 Pieter Abbeel 合作,发布了 Any-point Trajectory Model(ATM)框架。ATM 框架的创新之处在于通过预训练一个轨迹模型,专注视频中任意点未来轨迹的预测,而非整个图像的全面分析——这种选择性的关注点大幅降低了计算负荷,并加速了模型的运行效率。
因此,与传统方法相比,ATM 只需少量标注数据就能完成训练,还兼具鲁棒性。此工作也被机器人顶会 RSS 2024 接收,得到了所有审稿人的满分评价。根据千寻智能最新发布的 demo 来看,他们搭载 ATM 模型的机器人在制作咖啡时能识别透明反光的玻璃杯,推开挡住杯子的纸巾盒,还能扶起倒下的纸杯。
分层决策,各司其职
与端到端的黑盒不同,分层决策模型通过将感知、规划决策、控制和执行各模块分解为多个层级,分别突破「大脑」和「小脑」,利用不同的神经网络进行训练,最终再整合起来。
分层决策架构最知名的选手是与 OpenAI 合作的 Figure AI。
上个月问世即爆火的 Figure 02 采用三层级方案:顶层集成了 OpenAI 的大模型,负责视觉推理和语言理解(推测为 GPT-4V);中间层是神经网络策略(NNP),负责快速、灵巧的操作,将视觉信息直接转换为动作指令,并以高达 200hz 的频率输出这些指令;底层是全身控制器,负责提供稳定的基础控制,在接收 NNP 的动作指令后,能以 1khz 的频率输出各关节的扭矩指令。
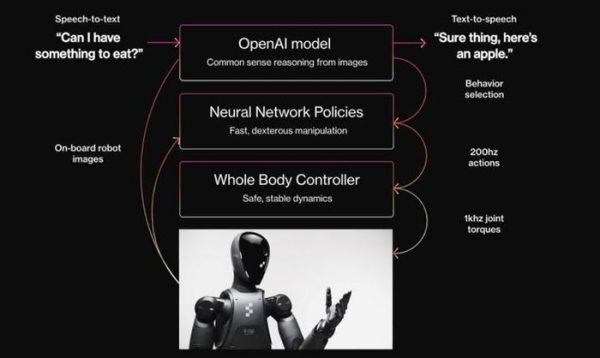
分层决策模型的最直接的优点便是即时性——Figure 02 高达 200hz 的输出频率意味着它执行动作的延时只有 5ms,比谷歌快了上百倍。
除此之外,因为各层级还能再细分为多个小模型,与端到端架构相比,分层决策架构还具有更高的可解释性和可控性,且由于可以逐一精准突破,在训练单个模型中所需的数据量相对更少。
「所有人都在赌 scaling law 是可行的,但到底是数据不够还是这个方法在具身智能不可行,目前尚不可知。」雅可比机器人创始人兼 CEO 邱迪聪表达了对纯端到端架构的顾虑,「最可怕的点在于这是个无法证实或证伪的黑洞,只能一直加量,像炼丹一样。」
因此,出于对成本和技术可实现性的考量,分层决策模型现已成为国内大多数具身智能初创公司的选择。除了简单划分为「大脑」和「小脑」外,不同的团队也根据自己的理解设计出各自的解决方案。
比如,上个月智元在发布首款产品远征 A1 时还推出了分为四级的具身智脑框架 EI-Brain ,包括技能级的云端超脑、技能级的大脑、指令级的小脑以及伺服级的脑干。
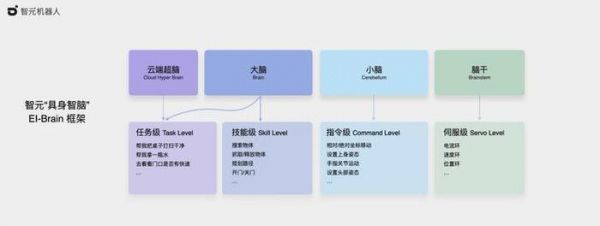
对于「大脑」,他们再细分为通用大模型和动作大模型两个模块。通用大模型负责认知世界,拆解任务步骤并感知物体位置,再由动作大模型完成具体动作,而且两者都是自研的。
智元机器人合伙人兼营销服副总裁姜青松表示,与由业界推动、数据来自互联网的通用大模型不同,动作大模型的数据来自于实际场景,需要采集真实数据。「动作大模型的数据壁垒更高,需要深入实际环境,如工业场景,需要直接在工厂部署才能获取到关键的真实数据。」
穹彻智能则是从第一性原理出发打造两级火箭大模型:一级火箭是实体世界大模型,能在训练中让机器人掌握常识性的、低维的操作物理表征,从而理解客观物理事实,并与人类概念对齐;二级火箭是机器人行为大模型,能充分耦合操作物理常识表征和执行体的高精度力反馈能力,从而作出仿人化的力位混合的行为决策,让操作兼具鲁棒性和通用性。
当两级火箭串在一起做端到端的联合训练时,数据量需求就会大幅降低、增长斜率更加明显,使训练变得足够的低成本和可规模化。
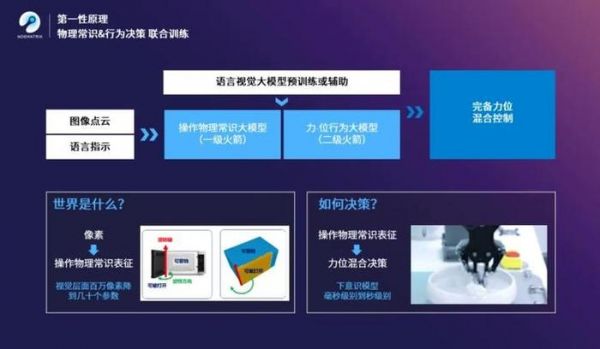
对于二级火箭,穹彻智能创始人、上海交通大学教授卢策吾认为,如果力这环不解决,具身智能很难落地。
「我们展示刮胡子技能,就是想说,具身智能的交互是需要高精密操作和高频接触的。」卢策吾解释道,「操作分为高频接触与非高频接触,非高频接触是做空间中的规划,相对的不确定性较小,但高频接触涉及力反馈,对决策和大脑提出更高的要求。」
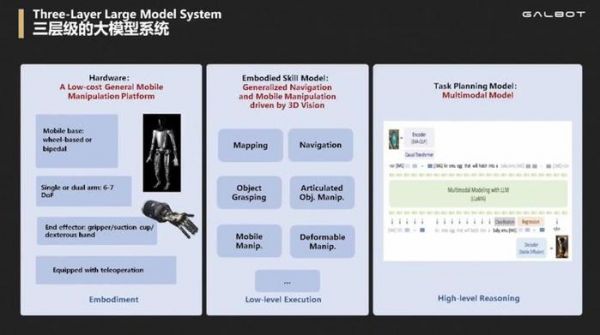
同样采用分层决策方案的还有推出三层级大模型系统的银河通用。
硬件(如末端执行器)为最底层,旨在打造低成本的通用移动操作平台;中间层是负责 low level 执行的具身技能模型,是由 3D 视觉驱动的通用导航和移动操作,能完成自主建图、自主导航、物体抓取、开门开抽屉开冰箱、挂衣服叠衣服柔性物体操作等任务;最上层是负责 high level 推理规划的多模态大模型,可以调度中间技能 API,来实现完整的从任务的感知、规划到执行的全流程。
值得一提的是,银河通用在中间的「小脑」层采用 100% 仿真合成数据,不用任何真实世界数据训练可泛化的技能,以求解决数据不足的痛点。
大脑 vs.小脑
显然,无论是哪种分层决策模型,都需要解决「大小脑」,实现从感知到执行的闭环。
先说说「大脑」。
「大脑」负责 high level 的感知和规划决策系统,是多模态大模型。与传统机器人相比,具身智能时代的机器人在这两个版块的泛化性和自主性都有了大幅提升。
首先,在感知环节,传统机器人的感知技术主要依赖于各种传感器来获取内部状态信息和外部环境信息,如视觉、力觉、触觉、嗅觉和味觉等,实现对物体的识别、测量距离、避开障碍物等功能。
而具身智能则更进一步,不仅包括了传统机器人的感知技术,还强调智能体与环境的交互和融合,以及在动态环境中自主、实时的决策和学习。基于多模态大模型(或更高阶的世界模型),机器人能学习、理解、融合和对齐各传感器采集而来的跨模态信息,实现对复杂环境的鲁棒建模与更精准、通用的感知。
到了规划决策板块,在大模型时代前,这主要由人类工程师负责,先理解任务、拆解动作,再编程给机器人下达具体指令。现在大模型直接化身 AI 工程师,使机器人能自主规划任务,提升了环境适应性和灵活性。
目前,业内将主打产品设为「大脑」的企业主要是穹彻智能和有鹿机器人,双方都主张研发通用的「大脑」来赋能包括但不限于人形机器人的载体上。
穹彻智能发布的具身大脑 Noematrix Brain 包括自研实体世界大模型和机器人行为大模型,使大脑具备规划、记忆、执行的核心能力。
因此,搭载穹彻大脑的实体机器人能对无限自由度物体做出操作,如无需预建模即可折叠杂乱衣物,以及执行不规则曲面任务,如刮胡子和削黄瓜皮。在穹彻的计划中,Noematrix Brain 将与各种类型的机器人本体、甚至工业设备都能有机结合。

而专注于开发「通用具身大脑」的有鹿机器人,也旨在为各类专业机器和人形机器人形态提供通用大脑。
最开始有鹿甚至打算仅以软件形式进行销售,但考虑到软件的无形性,很难在前期让客户切实感受到智能性,转而采取软硬件结合的形式,推出通用具身大脑 Master 2000。「这不仅限适用于工业、清洁、物流等领域,如叉车和铲车等,也适用于人形机器人,即插即用。」有鹿机器人介绍道,「具身智能并不局限在人形上。」
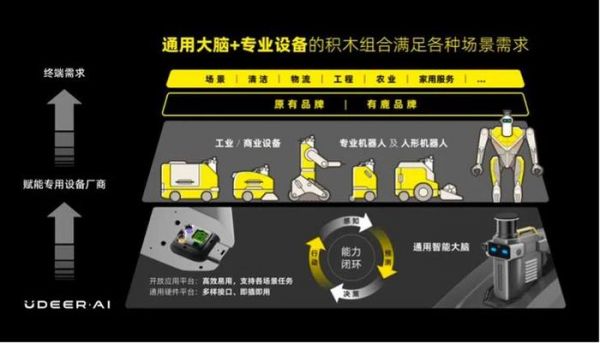
再看负责 low level 控制和执行模块的「小脑」。
它需要将「大脑」的决策转换为动作指令并执行出来,并将传感器采集的数据传递回去,一般由多个具体的小模型组合(如物体抓取模型、拧螺丝模型等),类似于一个可不断扩充、升级的技能库。
但与纯软件的「大脑」不同,「小脑」作为连接智能与身体的中间环节,承担着耦合软硬件的作用,依赖海量动作数据来训练。数据不足作为具身智能的最大痛点,也主要集中于此,所以关于仿真数据、模拟器、Sim2Real的探索也愈发火热。
不少从业者认为,当前具身智能的研究重点在于解决机器人的 low level 问题,因为 high level 已由大模型解决。
「low level 涉及实际的物理交互,如抓取、移动物体等基本技能。基础任务未解决前,大模型的顶层规划能力无法有效发挥,因为机器人可能连简单的动作如开冰箱门都做不到。因此,实现物理世界的顺畅交互是关键。」清华具身智能实验室主任、星海图联创许华哲说。
香港科技大学机器人研究院创始院长、戴盟首席科学家王煜则提出了「具身技能」的概念。「如果把具身智能称为大脑,那么中脑或小脑则是大关节控制,精细操作为细小脑,也可叫具身技能,需要有硬件、学习方法、数据的支持。」王煜教授解释道,「不到具身技能的层次其实无法发挥人形机器人的作用。」
结语
无论和哪一位具身智能创业者聊起其创业契机,必然会得到的回答之一便是「大模型让通用机器人有了实现的可能」。
短短一年,具身智能雄起,赛道之火热,俨然已瓜分了大模型的主角光环。
选择端到端还是分层决策架构,有点类似于是否「直接上人形」的讨论,取决于对项目落地速度和可靠性的要求——
前者是「登月派」,多由明星学者或有强融资能力的创始人坐镇,不需考虑短期的商业化落地,可以自由探索,目标是像 Open AI 一样直接「憋个大招」;
后者是「落地派」,期望逐步突破各应用场景,因此稳定性和模型的可解释性变得重要,需要更便于逐层优化和约束的分层结构来加速商业化落地的进程。
「随着数据和训练能力的增长,分层决策结构中各模块可能会逐步打通,最终融合简化成一个端到端模型。」美国湾区创企 Anyware Robotics 创始人兼 CEO 汤特认为路线选择是动态变化的,在足够大的市场里,任何一种路都有可能走通。
「就像特斯拉最初做自动驾驶也是采用分层结构,随着公司发展,逐步向端到端融合过渡,现在做人形机器人就直接端到端了。」
开普勒机器人 CEO 胡德波在与客户的交流中也发现,需求方并不介意技术路径究竟是分层还是端到端,重点是在于稳定可靠、高安全性以及性价比。
「从商业落地和实用主义的角度出发,我们不排斥各种算法,比如现在是大小脑,但如果有了特别好的端到端模型,参数量小、部署效果好,那我们也会使用。」
不过,无论是端到端的暴力美学,「大小脑」的高速实时协同,还是技术路径的动态变化,数据都是导致训练效果参差不齐的最大阻碍。
因此,在连续做出对构型和模型架构的抉择后,具身智能玩家们还得共同面临数据这个公认的最大痛点。
如何提高数据的质量和数量?模仿学习与强化学习哪种训练效果更优?真实数据和仿真数据谁更胜一筹?
让我们且走且看。
雷峰网本文作者anna042023将持续关注具身智能,欢迎添加雷峰网作者交流,互通有无。
发布于:广东
相关推荐
何为“具身智能”?
世界机器人大会风靡,具身智能如何落地?
中国机器人将统治具身智能时代?
晚点独家丨地平线组建具身智能实验室
国内规模高达200亿,AI 新浪潮真的是“具身智能”吗?|钛媒体AGI
“万亿”具身智能的师徒“江湖”
具身智能离现实有多远:热潮、泡沫和商业化
“人工智能那一套,对具身智能来说远远不够”
AI Pioneers|星海图高继扬:人形机器人不是具身智能的唯一答案
具身智能临近“iPhone 4”时刻,国产落地派有何惊喜?
网址: 下注端到端:一场具身智能的谨慎豪赌 http://www.xishuta.com/newsview126065.html
推荐科技快讯






- 1问界商标转让释放信号:赛力斯 95249
- 2人类唯一的出路:变成人工智能 21368
- 3报告:抖音海外版下载量突破1 21335
- 4移动办公如何高效?谷歌研究了 20508
- 5人类唯一的出路: 变成人工智 20508
- 62023年起,银行存取款迎来 10354
- 7五一来了,大数据杀熟又想来, 8753
- 8网传比亚迪一员工泄露华为机密 8533
- 9滴滴出行被投诉价格操纵,网约 8376
- 10顶风作案?金山WPS被指套娃 7240



