Sora这就落伍了?Meta“最强视频模型”不用DiT,用Llama大力出奇迹了
在OpenAI Sora的主要技术负责人跑去Google、多个报道指出OpenAI Sora在内部因质量问题而导致难产的节骨眼,Meta毫不客气发了它的视频模型“Movie Gen”,并直接用一个完整的评测体系宣告自己打败了Sora们。

而且更狠的是,Meta还“杀人诛心”,虽然这模型目前和Sora一样还没对外开放,但它把新模型的95页技术报告(没有开源,但包含很多细节)公开,并且告诉大家:
这模型不仅效果上打败了Sora,而且用了新的技术路线——也就是证明了Sora的技术路线在今天也不再是最先进的了。
各位文生视频玩家们,别“抄”Sora了。
“媒体基座模型”
准确说,Meta发布的是一系列模型,一个为了实现“AI生成媒体内容”而创建的一个组合。这也是这个技术论文的标题的意思:Movie Gen: A Cast of Media Foundation Models

这个组合包括:
最大的基础文生视频生成模型 Movie Gen Video , 300 亿参数。
最大的基础视频生成音频模型 Movie Gen Audio ,130 亿参数。
进一步对 Movie Gen Video 模型进行后训练获得的 Personalized Movie Gen Video,用来根据个人的面部生成个性化视频。以及一种新的后训练过程,能够生成 Movie Gen Edit,用于精确编辑视频。
这些模型结合起来,可以用于创建最高 16 秒的逼真个性化高清视频(16 FPS)和 48kHz 的音频,并具备编辑真实或生成视频的能力。
在用户侧,能体验到的功能包括:
视频生成: 用户用一段文本提示能生成高清视频(1080p),最长可达 16 秒,帧率 高达16fps。对主体-客体关系,物流规律捕捉和摄像机的各种拍摄运动等也都完成的很好。
个性化视频生成: 用户可以上传自己的图像,结合文本提示,可以让自己出现在个性化的生成视频里。
精准视频编辑: 这是Meta重点强调的功能,除了可以对背景和风格做整体的修改,Movie Gen也提供了通过文本指令来添加、移除或替换元素的局部编辑功能。缺乏对视频的精确编辑能力,在目前视频生成产品中算是一大痛点。
音频生成: Movie Gen 不仅可以根据视频内容和文本指令生成高质量的各类音效和音乐,而且还可以做到与视频内容更高度的匹配与同步。这些音频最长可达 45 秒,而且Meta还表示,它们的音频模型可以生成任意长度视频的连贯音频。
这是它展示的一系列案例:
不用DiT了,用Llama大力出奇迹!
这其中,最重要的显然是文生视频部分。
根据论文介绍,Movie Gen Video是一个拥有300亿参数的基础模型,用于联合文本生成图像和视频,可以生成符合文本提示的高质量高清(HD)视频,时长最长可达16秒。该模型能够自然地生成多种纵横比、分辨率和时长的高质量图像和视频。模型通过联合预训练,处理约1亿个视频和约10亿张图像,通过“观看”视频来学习视觉世界。
这只是最基础的介绍,而最最重要的信息就是,它不再是一个DiT架构的模型,也就是和现在几乎所有最知名的文生视频模型架构都不一样。
用Meta视频生成团队的研究科学家Andrew Brown的话说,在这个项目里最大的发现就是:数据,算力和模型参数非常重要。然后把这个搭配上Flow Matching,就可以用一个最简单最流行的架构——也就是Meta自己的Llama,实现最强的视频模型。
这明显是冲着Sora诞生后,已经成为所有文生视频创业公司和大厂项目主流的DiT路线去的。
今天视频生成的技术路线里,扩散模型是背后最主流的思想。简单说,它通过逐步将噪声还原为图像或视频,生成过程是一个去噪的过程。具体地,扩散模型的生成过程通常是从随机噪声开始,逐步反向推导出与输入文本描述相对应的清晰视频帧。而DiT是把Transformer的能力引入到这个思想里,来更好完成模型对全局上下文信息的捕捉能力,本质上还是扩散的思路。
但Flow Matching则不再从这个扩散过程入手做训练,而是更“暴力”,直接寻找更抽象的“近路”,而不是一步步寻找找路过程里的脚印:
Flow Matching基于轨迹学习,它直接在潜在空间(latent space)中学习从输入噪声到目标视频序列的映射轨迹。它通过优化一个连续的ODE(常微分方程)系统,找到从初始随机分布到目标分布的最佳“路径”。
而Meta这次把Flow Matching直接加到Llama架构上,第一次彻底不用扩散的思路来做生成并打败了DiT路线的一众代表模型。
要实现这个效果,自然是离不开“大力出奇迹”的配套方法。
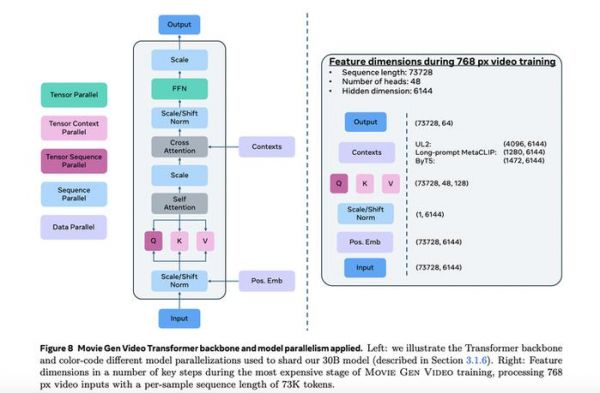
根据Meta的论文,他们使用了多达 6144 个 H100 GPU 训练了媒体生成模型,每个 GPU 的运行功率为 700W TDP,配备 80GB HBM3,采用 Meta 的 Grand Teton AI 服务器平台(Baumgartner 和 Bowman,2022)。在一台服务器内,有八个 GPU 通过 NVSwitch 进行均匀连接。服务器之间的 GPU 则通过 400Gbps RoCE RDMA 网卡相互连接。训练任务由 Meta 的全球规模训练调度器Mast进行调度。
扎克伯格囤的那些卡用在了哪里,用在了这。
除此之外,在这个详尽的论文里,Meta还介绍了在模型各个环节里的多个创新技巧。比如时空自动编码器(Temporal Autoencoder, TAE),通过它将视频和图像编码到压缩的时空潜在空间中,大幅减少生成视频时的计算量。这些技术让Meta可以“用一个更通用的架构来处理媒体生成任务”,它把图像和视频生成统一了起来。
简单说,Movie Gen用Llama大力出奇迹打败了Sora路线。
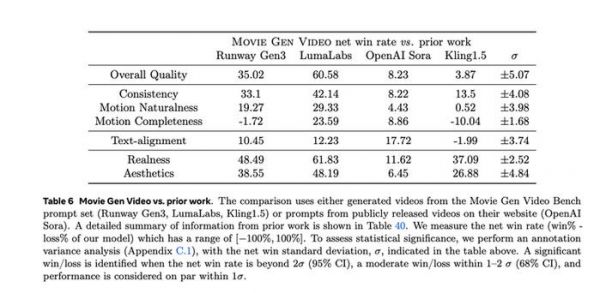
在Meta的各路人马对此次模型的宣传里,其实有一个很明显的意图:在证明了Sora路线不是最优路线后,它希望更多的开发者来基于Llama做文生视频的模型开发和研究。显然这对Meta的开源战略也很重要。
而另一个有意思的地方是,Meta这次的“模型家族”,其实不只是追求榜单和评测上的表现,它已经呈现出明显的实际应用导向,这让它本身看起来可能不会走开源路线,它的目标是用在Meta自己的社交媒体,乃至Orion为代表的下一代的计算平台生态里。
在Meta的官方博客里这样写道:
想象一下,您可以用文字提示来制作并编辑一个“日常生活”的动画视频分享到Reels,或者为朋友定制一个个性化的生日动画祝福,并通过WhatsApp发送给他们。随着创造力和自我表达的主导,可能性将是无限的。
相关推荐
Sora一旦推出,峰值算力需要75万张H100GPU
Llama 3性能炸裂!Meta要用“开源”争夺大模型王座
被吹爆的Sora ,为何恐怕是过誉了?
四款视频大模型5大场景测评:Sora到底有多炸裂?
AI规模法则:大力何以出奇迹?
技惊四座的Sora模型,参数只有30亿?
性能炸裂!Llama 3用开源对抗GPT?
Sora “拯救”元宇宙,世界模型的潜力才刚释放
Sora首批专业级视频公布,OpenAI要给好莱坞亿点点震撼
提前曝光Llama3.1,Meta为什么想做“大模型界Linux”?
网址: Sora这就落伍了?Meta“最强视频模型”不用DiT,用Llama大力出奇迹了 http://www.xishuta.com/newsview126186.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 94640
- 2人类唯一的出路:变成人工智能 16719
- 3报告:抖音海外版下载量突破1 16166
- 4移动办公如何高效?谷歌研究了 16014
- 5人类唯一的出路: 变成人工智 15778
- 62023年起,银行存取款迎来 9851
- 7网传比亚迪一员工泄露华为机密 7755
- 812306客服回应崩了 12 6217
- 9从TikTok在美困境看全球 5969
- 10山东省大数据局副局长禹金涛率 5891



