大模型企业分化,算力成买方市场
本文来自微信公众号:经济观察报 (ID:eeo-com-cn),作者:沈怡然周悦,原文标题:《大模型企业分化 算力成买方市场》
从2024年开始,采购和租用算力设备的企业减少了;2024年下半年以来,算力中心的机架出现了一定程度的空置;曾被炒到15万元一块的英伟达高性能加速卡A100的价格不再上涨,另一款性能配置相对较低的4090显卡被算力企业频繁采购用作算力加速芯片。
2024年至今,人工智能产业发生了阶段性转变。
根据经济观察报统计,截至2024年10月9日,网信办共通过188项生成式人工智能备案,也就是有188个大模型可以上线提供生成式人工智能服务。超过三成的大模型在通过备案后未进一步公开其进展情况;仅有约一成的大模型仍在加速训练模型;接近一半的大模型则转向了AI应用的开发。
这与过去一年多来的“百模大战”形成鲜明对比。
这一变化也传导至上游的算力市场。2024年9月27日—29日中国算力大会召开期间,经济观察报从算力运营方、建设方和芯片供应商处获悉,国内算力的供需关系已不再紧张。
2022年以来,互联网公司、人工智能企业争相采购算力设备,以运营商为代表的央国企投入巨资建设算力中心。供应链上的AI服务器经常缺货,算力GPU一卡难求,数月内价格翻倍。
从2024年开始,采购和租用算力设备的企业减少了;2024年下半年以来,算力中心的机架出现了一定程度的空置;曾被炒到15万元一块的英伟达高性能加速卡A100的价格不再上涨,另一款性能配置相对较低的4090显卡被算力企业频繁采购用作算力加速芯片。
一位中国电信人士称,算力已经转入买方市场。
大模型企业分化
算力的使用者——大模型企业正出现分化。
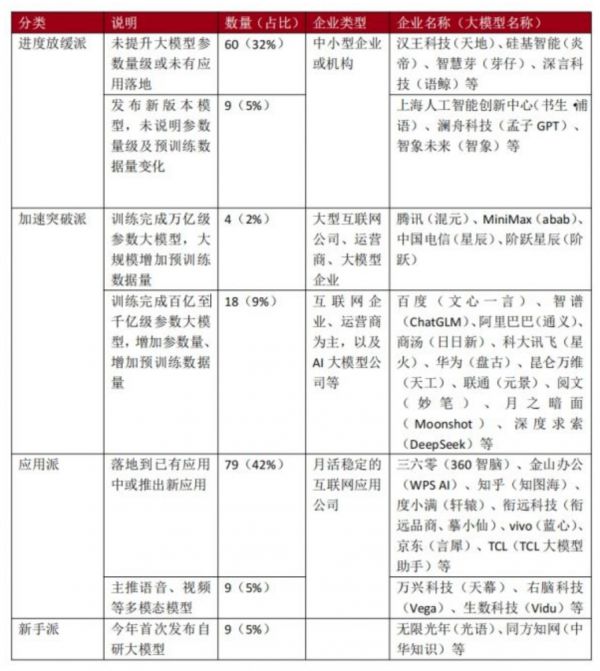
截至2024年8月底,网信办共通过188项生成式人工智能备案。然而,根据经济观察报统计,有60个(32%)大模型在备案通过后,没有再公布过提升大模型参数量级或应用落地的进展,有9个(5%)大模型更新了版本,但未说明参数量级及预训练数据量变化。
这些模型绝大多数来自中小型企业或机构,例如深言科技、聆心智能等企业的多个开源社区项目近一年没有更新。
这188个大模型中,仍有22个模型在加速训练,在今年更新了版本并增加参数量及预训练数据量。
这些模型主要来自大型互联网公司、运营商、AI大模型企业,其中只有4家企业发布万亿级参数的大模型,且大规模增加了预训练的数据量,包括腾讯、中国电信以及两家大模型创业公司MiniMax和阶跃星辰。
这些企业对用于训练大模型的算力明显增加了需求。2024年以来,腾讯、中国电信已经建成万卡集群算力池,MiniMax则是在3月首批入驻中国电信上海临港国产万卡算力池。
另外18个模型的参数量在百亿至千亿级别,参数量和预训练数据量的增加较为有限,这些模型来自百度、阿里巴巴、科大讯飞、商汤科技、华为等企业。
这些厂商也在加速更新基础模型。阿里巴巴发布了通义千问2.5版本,参数量达到千亿级别,这是继去年10月2.0版本后的一次重大更新。2024年上半年,商汤科技将“日日新”大模型推进至6000亿参数规模。相比之下,去年更新较快的百度步伐有所放缓,其文心4.0大模型自去年10月以来未有新版本发布。
一位百度技术人士告诉经济观察报,百度的基础模型一直在进行最前沿的AI训练,只是目前还没公布成果,“大厂肯定不会放弃训练模型的,否则就彻底分不到蛋糕了”。
表1:188个已备案大模型在2024年(截至10月9日)的变化情况
数据来源:经济观察报整理
根据经济观察报统计,在通过备案的大模型中,有接近50%在今年转向AI应用。
大多数模型已落地到已有应用中或推出了新应用。例如,360浏览器接入360智脑大模型后,增加了AI搜索功能,能够根据提问生成深度回答并进行多轮追问;金山办公在WPS办公套件中增加了AI生成PPT和文案的功能。
这些模型通常用于实际任务,即从训练阶段进入推理阶段,所需算力会明显减少。
一家大模型厂商的基础模型在达到百亿参数量后转向了行业应用,为避免后期使用成本过高就没有扩充参数量,因此也不需要过大的算力。
该模型厂商人士认为,大模型并非越大越好,更大参数量意味着使用成本更高,千亿、万亿参数规模的模型主要是为了刷榜。
IDC中国副总裁兼首席分析师武连峰对经济观察报称,“百模大战”开启一年多以来,市场出现了分化现象:少数模型继续沿着通用大模型的路径,迈向千亿或万亿参数量级;另一些从基础模型研发转向了应用层面的开发,市场上也涌现出一批基于大模型技术的工具类应用。这些应用同质化明显,没有出现广泛使用的爆款案例。
根据第三方数据服务商AI产品榜发布的9月数据,全球排名前十的AI应用中有7个来自美国,2个来自中国——百度搜索AI智能回答和360AI搜索。美国AI应用ChatGPT的月访问量为32.3亿,百度搜索AI智能回答的月访问量约为ChatGPT的八分之一,360AI搜索的访问量不到ChatGPT的十分之一。
算力变成买方市场
大模型市场与算力市场关联密切。按照规模定律(Scaling law)的原理,如果要训练更大的大模型,首先要增加参数量或预训练数据量,如果模型的参数量增加10倍,所需算力可能增加100倍甚至更多。
当前,一些大模型停留在了训练阶段,另一些转向了应用和实际交付阶段,但尚未被广泛使用。从需求方看,相关企业对训练算力的需求明显减少,对推理算力的需求也没有出现爆发式增长,而从供给方看,中国已建和正在建设的智算中心超250个,算力持续供给仍未停止。
建造一座算力设施通常需要投资方、运营方、建设方的合作。投资方主要是地方政府和央国企;运营方包括电信运营商以及互联网公司、华为等企业,还有少数房地产等传统企业跨界参与;建设方通常包含服务器提供商和GPU芯片提供商。
超聚变是一家提供服务器和算力服务的供应商,客户主要是金融、互联网、电力企业。这家公司在最近几个月感受到了行情转变,去年的互联网厂商都来抢服务器,买家需求非常急迫,确认有货就能下单,谈价过程很快,有时甚至不用谈价。2024年以来,前来采购的客户变少,询价和谈判时间更长,买方更注重产品的性价比和技术规格。
此外,智算中心也出现了一定程度的空置。中国电信在全国各地投产了10个智算中心。前述中国电信人士发现,很多算力中心都没有被充分利用,很多机架是空置的。
根据中国信息通信研究院数据,中国算力设施中的机架数量在2024年上半年仅增长2.5%,而2023年全年增长了25%。算力设施中的机架数量间接反映了实际的算力规模。
今年的《政府工作报告》提出,适度超前建设数字基础设施,加快形成全国一体化算力体系,培育算力产业生态。诸多地区当下的算力建设规模是根据未来2—3年的算力需求来规划的,在模型计算尚未爆发的阶段,必然出现利用率不足的情况。
前述中国电信人士对经济观察报称,现在的算力已经是买方市场,用户有更多算力价格的议价权。投资方的态度也更为谨慎和理性,开始对运营方提出相应的回报要求与考核。运营方一方面转向采购性价比更高的算力设备,另一方面,正采用更灵活的策略,比如按需建设算力,在产能规划上布置了上千台机架,接到明确的用户需求和订单才会真正采购算力设备并上架运行。“作为运营方,我们已经不能像原来一样不计成本地投入,要想尽快回收成本,必须考虑成本投入和投资回报周期。”该中国电信人士称。
产业对算力芯片的采购也更注重性价比。2024年以来,国内对英伟达4090显卡的需求正在上升,目前,这款顶级游戏显卡的价格从年初的12000元涨至18000元。
一位英伟达代理商告诉经济观察报,下半年以来,4090显卡的周转率非常高,到货3天就卖出去了。相比之下,A100的单价不再上涨,维持在15万元不变,周转率却在下降。
4090和A100都属于GPU芯片,在英伟达产品线中,4090是一款面向玩家的高端游戏显卡,A100则是卖给算力中心的高性能加速卡。4090在部分性能上弱于A100,但也能满足一部分模型的推理任务,最重要的是,其价格是A系列和H系列加速卡的十分之一。
这一波4090显卡的买家绝大多数是企业,大多是智算中心的建设方或者技术提供方,用平价显卡替代高价的A100或H100芯片。
商汤科技正推动大模型进入端侧、交付客户。但在模型进入商业闭环阶段,这家企业对算力的需求也在变化,包括采用智能算力调度等技术来提升算力效能。商汤科技智能产业研究院院长田丰称,过去公司不计成本地采购算力,如今更追求算力的性价比。
(本报记者钱玉娟、任晓宁对本文亦有贡献)
相关推荐
大模型企业分化,算力成买方市场
大模型的混沌年代:矛盾、分化与未来
算力卡不住大模型的脖子
阿里进入大模型时代,核心是算力和生态
国产算力和国产大模型,迎来双赢时刻
AIGC及大模型产业链梳理:平台、应用、算法、算力
大模型算力的「热」与 10 亿万卡成本的「冷」思考
大模型算力的「热」与10亿万卡成本的「冷」思考
360数科张家兴:企业应向大算力大模型方向技术布局
加速分化:关于大模型走势的十个判断
网址: 大模型企业分化,算力成买方市场 http://www.xishuta.com/newsview126585.html
推荐科技快讯






- 1问界商标转让释放信号:赛力斯 94794
- 2人类唯一的出路:变成人工智能 17960
- 3报告:抖音海外版下载量突破1 17474
- 4移动办公如何高效?谷歌研究了 17237
- 5人类唯一的出路: 变成人工智 17067
- 62023年起,银行存取款迎来 9976
- 7网传比亚迪一员工泄露华为机密 7944
- 812306客服回应崩了 12 6340
- 9顶风作案?金山WPS被指套娃 6145
- 10大数据杀熟往返套票比单程购买 6125



