算力通缩下的“老黄经济学”
雨天周末,不想读书不想学习,就想扯淡。
先吐个槽,最近看到某DPU厂商80亿估值然后因为各种原因玩不下去了的公众号文章,然后还有一个会还在讨论DPU怎么怎么的……我还记得三四年前和某个机构一起基本上把这些厂家都调研过,当时就不停地diss这群人没想明白,但似乎几年过去还是没想明白。
不过最近似乎想明白了一点为啥叫DPU了,从Pradeep在互联网泡沫时期创建的Juniper,到后面离职创建Fungible,其实DPU的意思是从网络需要处理数据的视角定义的,但是到后来逐渐演进的过程中,老黄把DPU的概念发扬光大后,发现这词还是有问题,这不又SmartNIC和DPU都无法定义,又开始造出了一个SuperNIC了么?
倒是Tesla人间清醒的一个DumbNIC讲的很清楚,大道至简顺便还把HBM-Disaggragation搞了……
回到正题,在算力通缩情况下,老黄如何维持或者进一步冲高到五万亿市值是一个很有趣的话题,所以今天从经济学的角度扯个淡……渣B也没正经地读过经济学的书,另一方面对于建模的量化数据因为合规原因,没有数据也没有意愿去了解数据,因此也不作过多的分析了,只是单纯地扯个淡而已。
一、什么是算力通缩
上周一篇《把GPU当成一个金融产品如何加杠杆?》谈到了算力通缩(computility deflation,以下简称CD), 首先我们来给CD一个定义:
算力通缩(computility deflation,CD):在经济学中,通货紧缩是指商品和服务总体价格水平的下降。从算力的角度来看,我们也可以定义平均1GFLOPS的价格作为GPU和算力服务的总体价格水平。
就算力服务价格(以租用H100等GPU)的价格来看, 总体价格是在下降的。例如H100的租金价格从4美元一小时如今降到不到2美元一小时。而从GPU本身的商品价格来看,国内一些H100的整机价格也从早期的300多万降到了220万。
二、经济学的悖论
一般来说,我们简单地以经济学中的IS-LM模型来看,也就是说供给增加或者需求下降或者两者同时发生引起的。简单来说就是供给过量(过量生产),需求低迷(消费减少),或者是信贷紧缩等带来的货币供应减少而产生的。
当然有另一种观点是,通缩和经济中的技术进步有关,随着全要素生产率的提高,商品成本会下降。也就是老黄期待的需要一年一代新卡来降低算力架构。
有一个悖论的地方是H100售价3万美金,而物料成本大概只有3000美金,HBM成本占了2000。在算力通缩背景下,如何能够持续性地维持高Margin,同时还能通过不停的迭代增加营收来冲高市值?
归根结底还是要回答一个问题:钱从哪儿来,钱期望的收益率曲线是什么?
从货币供应的角度来看,针对AI的投资并没有减缓,OAI这一轮的融资还算正常,然后H100/H200的需求还在持续,国内各地的“智算中心”项目也还在持续的建设中。全球来看Blackwell也供不应求。
但是反过来看有一个很有趣的观点,到底是谁在为这些投资买单?钱从哪儿来的?投资回报率怎么估计?杠杆率是多少?特别是从算力提供方来看,算力自身由于技术迭代产生贬值非常快(算力服务价格和算力商品价格都在加速下滑),既然算力通缩背景下,为什么不延迟消费,再等等新卡?另一方面对于基础设施投入的杠杆加在什么地方?智算中心建设的ROI如何计算?
最近还有一种观点是在互联网泡沫时期的基础设施为后来互联网蓬勃发展奠定了基础,特别是大量的海底光纤的成本在后期是完全收回来了的。但是对于智算中心的成本,或许要在几年后收回从投资回报率的角度是很难的。对此我一直持比较负面的态度,只有少数几家规模大有可能收回一部分,对于它们来说,算力投资的风险并不是太大。
1. Azure,微软通过OAI投资和更上层的copilot业务收入可以填补,同时也在布局自己的推理芯片;
2. Meta,大量的H100通过Llama的生态以及内部的推荐系统可以摊薄成本,同时也有自己的推理芯片;
3. AWS Trainium/Google Trillium(TPU)的供应量具体数值不清楚,但是至少Google自家的搜索等业务还是有大量的算力消耗的;
4. Tesla的自动驾驶,字节等企业的搜广推以及视频生成等业务上,大量的H100的消耗实际上也不会带来很大的亏损。
至于各地建设的各种智算中心, 是不是过两年要开始不良资产处置了呢? 不良的定义和定价还分两种情况:
1. 不良算力资产处置
2. 算力不良资产处置
即不良算力本身的评估:先还不要说那些各种以DSA卡建设的算力集群了……简单的以NV H系列卡为例,初期很多人以为买点机器回来插上电给个管理口IP地址就可以卖了,然后发现网络建设也需要跟上,还有就是稳定性和故障运维,紧接着发现如果要寻推一体,又要搭一个存储集群,然后还有互联网带宽……
另一个问题是:算力通缩和不良算力以及算力不良本身是否有很大的关系, 需要考证一下?
三、算力的杠杆
杠杆的产生通常是在时间维度上带来的,例如在期货市场上通过保证金来对远期交割物达成一个协议,另一方面就是对于大型基础设施建设通过融资租赁的方式。本质上还是要在近期创造出一个巨大的需求,然后通过远期相对确定的现金流来完成。
而本质上解决通缩的方法大概就是: 增加货币供给,以及扩大总需求。
3.1 Scaling-Law: 需求的创设
最简单明显的需求创设就是老黄经济学中的“The More You Buy,The More You Save”。
从pre-train scaling-law构造了一个宏大叙事: 从千卡的A100到万卡的H100再到10万卡的训练,但很显然的是OAI在GPT-5的训练上遇到了蛮大的麻烦。但在整个杠杆赌局里,没有一方会那么容易的平仓认输,以至于Inference Scaling-law的出现。
另一方面这样的杠杆也在吞噬着市场里的玩家,花一个亿预训练的模型成了贬值最快的商品,更大的模型有几家跟?国内所谓六小虎的情况以及前几天刚爆出ST的裁员……
3.2 供应端的流动性紧缩
对于供给过量的问题,首先来谈一谈存量市场。其实H100的存量市场会清洗出一大批玩家,对于H100的估值可能还存在争议,那么我们以现阶段对一些A100/A800算力中心的不良资产估值该怎么做?这些需要考虑算力的时间价值和资金的时间价值。我们单独放一章来谈。
那么我们来谈另一个话题:为什么新卡的供应上,微软等几个巨头要疯抢GB200?一方面是后一节讲的算力的时间价值,新卡出来的前几个月的需求是非常旺盛的,同时带来的流动性溢价会产生更好的短期现金流。这对算力商品提供方(NV)和算力服务提供方(Azure等)都是有利的,但是前提是要构造出足够的需求来支付这样的短期现金流,那么也就只能进一步的找一个算力消耗方,然后通过更远的现金流预期在解决期限错配的问题。
四、算力的时间价值
既然上了杠杆,那么资金的成本和对应的算力通缩下算力的时间价值就是一个我们值得探讨的问题。本质上很多机构对大规模投资的短期回报逐渐产生质疑和丧失耐心了,毕竟ChatGPT也出来快满两年了,但是大量的投资似乎还暂时看不到回报。
另一方面随着时间的流逝,当年抢购的H100逐渐出现商品价格和服务价格的快速下滑,这也让一些算力投资方逐渐感受到了风险,接下来随着Blackwell的出现,H100的贬值速度还会进一步加快,整个H系列的成本摊销周期似乎和两年前预测的周期也在缩短。
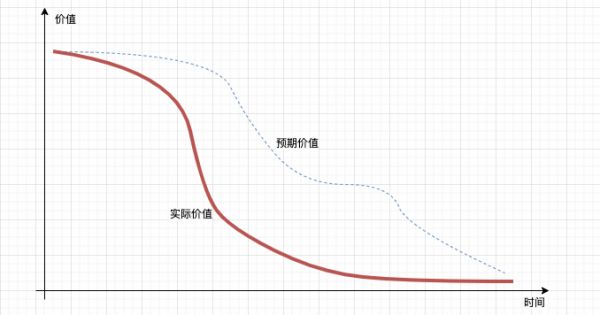
也就是说实际上算力价格的TimeDecay速度远超过了当初投资的现金流模型,这种期限错配产生的不良资产处置,是一个非常有趣的话题,但是就点到为止吧。
五、谈谈货币投放受限下的算力通缩
其实写了这么多并不是说在反对Scaling-Law或者说是看空AIGC,其实任何新技术的出现都是丑陋且反直觉的,但是算力的问题除了基础设施迭代外,更多的还是需要算法去解决。渣B以前的量化算法复杂度从刚开始研究的时候也是因为计算复杂度基本上一次全量计算需要30天左右,因此从那个时候开始就在折腾一些并行计算的框架,但是后来还是算法上的优化解决的问题。
而对于这一次AIGC来看,从根本上我持有一个怀疑态度是新的数学工具并没有应用于模型之上,这个直接决定了当前生成式大模型的天花板,虽然当前的天花板足够高足够容纳很多想象空间。但总是觉得哪里不对,举个例子吧,例如为了网络规模和深度采用LayerNorm等带来的访问内存压力,是否有更好的算法来解决?
另一方面是基础设施上,是否有不需要NVLink,不需要CoWoS,不需要HBM的基础设施,哪怕是训练不行,先撸一下对算力需求相对较低一些的推理场景》例如苏妈出一个多带一点PCIe接口的多带一些GDDR的家用级显卡,并且放开GDR,让一些买不起H100又要做大模型研究的中小规模团队先用起来,放低一下姿态实在是生态不行,不谈rocm,光拿来给NV做内存池的二奶都行?在NV带来的流动性紧缺上绕开CoWoS和HBM,从而打开一个突破口,即便是数据中心卖得不好,撸掉NV家用卡RTX的市场也是好事?
大概就胡扯这么多吧,其实蛮希望若干年后,我们能对这一场杠杆局做一些总结和回顾,特别是监管层的视角。历史虽然不会简单地重复, 但是每次都会押韵。
本文来自微信公众号:zartbot,作者:渣B
相关推荐
黄仁勋称AI的未来是能够推理 但首先要降低算力成本
老黄全新RTX 5090显卡来了!性能飙升,但价格感人
联想拿出能跑大模型的AI PC,老黄、苏妈捧场
打造算力生态,软通动力助推AI大模型发展
集度“官宣”高通,算力焦虑下的汽车芯片迎来曙光?
特供中国的英伟达算力芯片,为什么卖不动?
聚焦2023中国算力大会 | 拆解算力“偏科”难题 需推动算力供给高效普惠
黄仁勋的年会不能停
黄仁勋:英伟达的 AI 算力,“一折”出售
中长期算力自主可控 国产算力生态受益股一览
网址: 算力通缩下的“老黄经济学” http://www.xishuta.com/newsview127419.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 94804
- 2人类唯一的出路:变成人工智能 18105
- 3报告:抖音海外版下载量突破1 17624
- 4移动办公如何高效?谷歌研究了 17377
- 5人类唯一的出路: 变成人工智 17213
- 62023年起,银行存取款迎来 9991
- 7网传比亚迪一员工泄露华为机密 7962
- 812306客服回应崩了 12 6352
- 9顶风作案?金山WPS被指套娃 6280
- 10大数据杀熟往返套票比单程购买 6261



