英伟达下一代GPU,真实性能发布
来源:内容编译自IEEE,谢谢。
Nvidia、甲骨文、谷歌、戴尔和其他 13 家公司报告了他们的计算机训练当今使用的关键神经网络所需的时间。这些结果包括首次亮相的Nvidia 下一代 GPU B200和谷歌即将推出的加速器Trillium。B200在某些测试中的表现比当今的主力Nvidia芯片H100提高了一倍。而且Trillium 的性能比谷歌在 2023 年测试的芯片提高了近四倍。
该基准测试称为 MLPerf v4.1,包括六项任务:推荐、大型语言模型(LLM) GPT-3和 BERT-large 的预训练、 Llama 2 70B 大型语言模型的微调、对象检测、图形节点分类和图像生成。
训练GPT-3是一项艰巨的任务,如果只是为了提供一个基准而完成整个任务是不切实际的。相反,测试是将其训练到专家认为的水平,这意味着如果你继续训练,它很可能会达到目标。对于 Llama 2 70B 来说,目标不是从头开始训练 LLM,而是采用已经训练过的模型并对其进行微调,使其专注于某一特定专业知识——在这种情况下,政府文件。图节点分类是一种用于欺诈检测和药物发现 的机器学习。
随着人工智能的重要性不断演变,主要转向使用生成式人工智能,测试集也发生了变化。MLPerf 的最新版本标志着自基准测试工作开始以来测试内容的彻底转变。“目前,所有原始基准测试都已逐步淘汰,” MLCommons 基准测试工作负责人David Kanter表示。在上一轮测试中,执行某些基准测试仅需几秒钟。
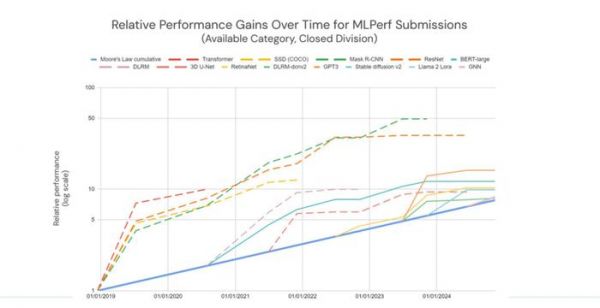
根据 MLPerf 的计算,新基准套件上的 AI 训练正在以摩尔定律预期速度的两倍左右的速度改进。随着时间的推移,结果比 MLPerf 统治时期开始时更快趋于稳定。Kanter 将此主要归因于公司已经弄清楚了如何在非常大的系统上进行基准测试。随着时间的推移,Nvidia、Google和其他公司已经开发出允许近乎线性扩展的软件和网络技术——将处理器数量增加一倍可以将训练时间缩短大约一半。
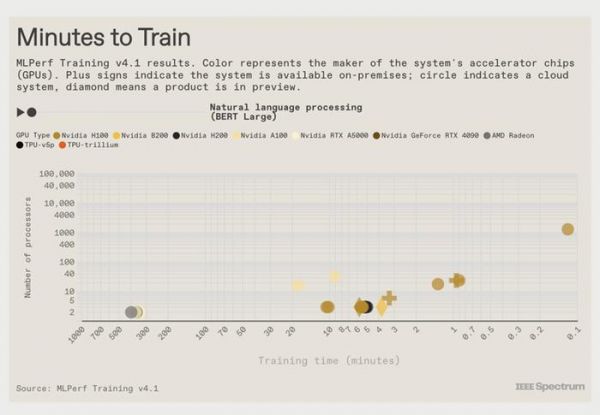
第一个 Nvidia Blackwell 训练结果
这一轮是 Nvidia 下一代 GPU 架构 Blackwell 的首次训练测试。对于 GPT-3 训练和 LLM 微调,Blackwell (B200) 的每 GPU 性能大约是 H100 的两倍。对于推荐系统和图像生成,收益略有下降,但仍然相当可观——分别为 64% 和 62%。
Nvidia B200 GPU 所采用的Blackwell 架构 延续了使用越来越低精度数字来加速 AI 的趋势。对于 Transformer 神经网络的某些部分(例如ChatGPT、Llama2 和Stable Diffusion),Nvidia H100 和 H200 使用 8 位浮点数。B200 将其降至仅 4 位。
英伟达表示,在 MLPerf Training 4.1 行业基准测试中, NVIDIA Blackwell平台在所有测试的工作负载上都取得了令人印象深刻的成绩,在 LLM 基准测试中,每块 GPU 的性能提高了 2.2 倍,包括 Llama 2 70B 微调和 GPT-3 175B 预训练。此外,NVIDIA 在 NVIDIA Hopper 平台上的提交继续在所有基准测试中保持大规模记录,包括在 GPT-3 175B 基准测试中使用 11,616 个 Hopper GPU 提交的提交。
如上所说,Blackwell 首次向 MLCommons 联盟提交训练,该联盟为行业参与者创建标准化、公正且经过严格同行评审的测试,重点介绍了该架构如何提升生成式 AI 训练性能。
例如,该架构包含新的内核,可以更有效地利用 Tensor Core。内核是经过优化的专用数学运算,例如矩阵乘法,是许多深度学习算法的核心。Blackwell 更高的每 GPU 计算吞吐量和更大、更快的高带宽内存使其能够在更少的 GPU 上运行 GPT-3 175B 基准测试,同时实现出色的每 GPU 性能。
利用更大、带宽更高的 HBM3e 内存,仅需 64 个 Blackwell GPU 即可在 GPT-3 LLM 基准测试中运行,且不会影响每个 GPU 的性能。使用 Hopper 运行相同的基准测试则需要 256 个 GPU。
Blackwell 训练结果遵循了之前提交给 MLPerf Inference 4.1 的结果,与 Hopper 一代相比,Blackwell 的 LLM 推理性能提高了 4 倍。利用 Blackwell 架构的 FP4 精度以及 NVIDIA QUASAR 量化系统,提交结果展现了强大的性能,同时满足了基准的准确性要求。
英伟达表示,NVIDIA 平台不断进行软件开发,为各种框架、模型和应用程序的训练和推理提供性能和功能改进。在这一轮 MLPerf 训练提交中,自推出基准以来,Hopper 的 GPT-3 175B 每 GPU 训练性能提高了 1.3 倍。
NVIDIA 还使用 11,616 个 Hopper GPU 通过NVIDIA NVLink 和 NVSwitch 高带宽 GPU 到 GPU 通信以及 NVIDIA Quantum-2 InfiniBand 网络连接,在 GPT-3 175B 基准上提交了大规模结果 。
自去年以来,NVIDIA Hopper GPU 在 GPT-3 175B 基准测试中的规模和性能提高了三倍多。此外,在 Llama 2 70B LoRA 微调基准测试中,NVIDIA 使用相同数量的 Hopper GPU 将性能提高了 26%,这反映了软件的持续增强。
NVIDIA 不断致力于优化其加速计算平台,从而持续改善 MLPerf 测试结果 - 提高容器化软件的性能,为现有平台上的合作伙伴和客户提供更强大的计算能力,并为他们平台投资带来更高的回报。
谷歌推出第六代硬件
谷歌展示了其第六代 TPU Trillium 的 首批结果(上个月才发布),以及第五代变体 Cloud TPU v5p 的第二轮结果。在 2023 年版本中,这家搜索巨头推出了第五代TPU 的另一个变体 v5e,其设计更注重效率而非性能。与后者相比,Trillium 在 GPT-3 训练任务上的性能提升高达 3.8 倍。
但与所有人的劲敌 Nvidia 相比,情况并不那么乐观。由 6,144 个 TPU v5ps 组成的系统在 11.77 分钟内到达了 GPT-3 训练检查点,远远落后于由 11,616 个 Nvidia H100 组成的系统,后者在大约 3.44 分钟内完成了任务。顶级 TPU 系统仅比其一半大小的 H100 计算机快约 25 秒。
戴尔科技公司的计算机使用了约 75 美分的电力对 Llama 2 70B 大型语言模型进行了微调。
在 v5p 与 Trillium 最接近的正面比较中,每个系统由 2048 个 TPU 组成,即将推出的 Trillium 将 GPT-3 训练时间缩短了整整 2 分钟,比 v5p 的 29.6 分钟提高了近 8%。Trillium 和 v5p 的另一个区别是 Trillium 与AMD Epyc CPU 配对,而不是 v5p 的Intel Xeon。
谷歌还使用 Cloud TPU v5p 训练了图像生成器 Stable Diffusion。Stable Diffusion 有 26 亿个参数,难度不大,MLPerf 参赛者需要将其训练到收敛,而不是像 GPT-3 那样只训练到检查点。1024 TPU 系统排名第二,在 2 分 26 秒内完成任务,比由 Nvidia H100 组成的相同大小的系统慢了大约一分钟。
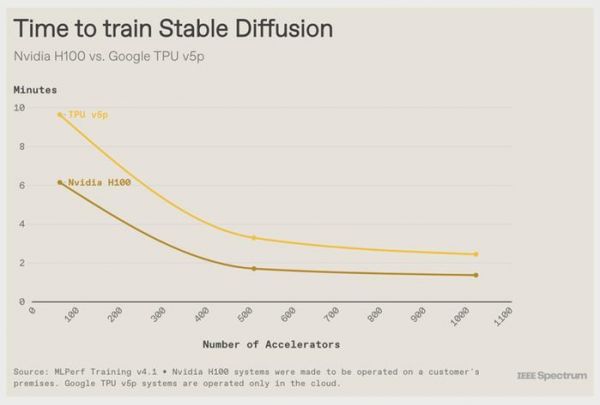
训练能力仍不透明
训练神经网络的高昂能源成本长期以来一直令人担忧。MLPerf 才刚刚开始测量这一点。戴尔科技是能源类别的唯一参赛者,其八服务器系统包含 64 个 Nvidia H100 GPU和 16 个Intel Xeon Platinum CPU。唯一的测量是在 LLM 微调任务 (Llama2 70B) 中进行的。该系统在 5 分钟的运行中消耗了 16.4 兆焦耳,平均功率为 5.4 千瓦。按照美国的平均成本计算,这意味着大约 75 美分的电费。
虽然结果本身并不能说明什么,但确实可能为类似系统的功耗提供大概的数据。例如,Oracle 报告了接近的性能结果——4 分 45 秒——使用相同数量和类型的 CPU 和 GPU。
发布于:安徽
相关推荐
最前线 | 英伟达发布GPU旗舰A100,采用7nma工艺,性能提升20倍
英伟达发布 L40S GPU:AI 推理性能较 A100 高 1.2 倍
黄仁勋的「厨房演讲」,熬制的却是英伟达 GPU 史上最大性能飞跃
黄仁勋扔重磅“核弹”,英伟达发布全新RTX 500和1000 GPU芯片,AIGC性能提高1400%|钛媒体AGI
Nvidia下一代GPU,功耗惊人
英伟达的未来,不只是GPU
英伟达GPU,警钟敲响
AI芯片对决:英特尔GAUDI与英伟达GPU
英伟达H200发布,性能很强,奈何买不到
刚刚!万亿英伟达发布“AI核弹”
网址: 英伟达下一代GPU,真实性能发布 http://www.xishuta.com/newsview128435.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 94831
- 2人类唯一的出路:变成人工智能 18279
- 3报告:抖音海外版下载量突破1 17828
- 4移动办公如何高效?谷歌研究了 17547
- 5人类唯一的出路: 变成人工智 17382
- 62023年起,银行存取款迎来 10009
- 7网传比亚迪一员工泄露华为机密 8000
- 8顶风作案?金山WPS被指套娃 6446
- 9大数据杀熟往返套票比单程购买 6423
- 1012306客服回应崩了 12 6370



