研究人员打造即插即用型框架,将多智能体强化学习引入大语言模型
当前,在安全对齐、代码生成等下游任务中,大语言模型要想进一步提升性能,往往需要进行强化学习微调。
但是,从强化学习的视角来看,如果把大语言模型当成根据 prompt 做决策的智能体,就会发现强化学习微调这个任务可谓十分困难。
其中主要存在两个难点:
一是大语言模型拥有非常庞大的离散动作空间,整个 token 字典都是它的动作空间。以 Meta 公司的 Llama2 模型为例,它的动作空间有 32000 维。
而生成一个回答可能包含几十甚至上千个 token 的组合,其复杂度远远大于在强化学习领域已经被解决得很好的围棋和星际争霸等任务。
二是稀疏奖励问题,即大语言模型只有在完整生成一个回答后才会得到一个奖励。
这两个问题导致强化学习微调很不稳定,在微调的时候容易使模型的输出分布大幅偏离预训练模型,从而导致模型原有的对语言结构的建模发生崩溃(即分布崩溃),进而引发模型输出质量的急剧下降。
现有很多研究都是从构建密集奖励函数入手来解决大语言模型的强化学习微调的问题。
但是,中国科学院自动化所博士生马昊和所在团队尝试从多智能体的角度来看这个问题。
结合团队在群体智能领域的大量积累,他们认为:如果使用多个大语言模型构成一个多智能体系统,在多个大语言模型之间构造一种博弈关系,也许能实现大语言模型能力的进一步涌现。
这一思路的背后主要基于两个观察:一是自然语言本身就是在群体交互中涌现的;二是在群体中,智能体间的博弈关系无论是合作关系还是竞争关系,都可以促进军备竞赛或协同演化,从而在智能体之间形成一种相互促进的动态。
那么,如何在多个大语言模型之间构造一种博弈关系?要知道,基于特定任务针对大语言模型进行强化学习微调,它本身是一个单智能体强化学习问题,因此把它构造成博弈问题颇具挑战。
在尝试了多种构造方式后,他们最终发现将两个大语言模型之间的交互构造为 Stackelberg 博弈可以将强化学习微调转化为一个多智能体强化学习问题,并实现研究初期所设想的“协同演化”。
这种方法包含两种机制:
1. 从一个初始大语言模型出发,来将其复制成两份:Pioneer 大语言模型和 Observer 大语言模型,其中前者仅通过任务 prompt 输出回答,后者则根据任务 prompt 并以前者的回答作为参考来输出新的回答。
2. 两个大语言模型智能体通过各自独立的数据来进行强化学习微调,任务奖励为两者之和。当微调到固定轮次之后,再交换两者的角色,之后反复迭代。
通过此,该团队打造出一款名为 CORY 的即插即用型框架,任何能被用于微调大语言模型的强化学习算法,都可以放在这个框架中进行使用。
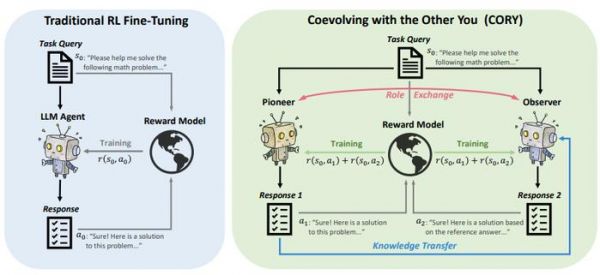 图 | CORY 的框架(来源:arXiv[1])
图 | CORY 的框架(来源:arXiv[1])马昊表示,这种方式既能有效地避免分布崩溃,还能确保大语言模型的能力稳定提升。
另外,在消融实验中他们发现了一个有趣的现象:在不交换两个智能体的角色的时候,仅仅依靠 Stackelberg 博弈这种信息传递,Observer 也能保持一个相对比较低的相对熵。
这意味着 Pioneer 所提供的参考答案构成了一种针对搜索空间的隐式约束,无意中解决了搜索空间过大的问题。
在这个被约束的搜索空间中,更利于 Observer 找到高质量的策略。
随着高质量预训练数据的枯竭,大语言模型的基础能力逐渐达到瓶颈。
而长期来看,强化学习微调是一个能够打破这种瓶颈的手段,其在数学推理、代码生成等存在客观奖励函数的任务中的上限可能远超我们想象。
 图 | 马昊(来源:马昊)
图 | 马昊(来源:马昊)日前,本次研究的相关论文以《与另一个你共同进化:使用序列合作型多智能体强化学习微调大语言模型》(Coevolving with the Other You: Fine-Tuning LLM with Sequential Cooperative Multi-Agent Reinforcement Learning)为题已被 NeurIPS(Conference and Workshop on Neural Information Processing Systems) 2024 接收 [2]。
(来源:arXiv)
自动化研究所博士生马昊是第一作者,自动化研究所博士生扈天翼是共同一作,自动化研究所蒲志强研究员担任通讯作者。
马昊表示:“CORY 是将多智能体强化学习引入大语言模型的强化学习微调的最早工作。”但是,从多智能体强化学习的角度来看,还有很多可以继续开展的工作。
比如,增加智能体的数目、改变智能体的角色、在规模性和交互性等群体要素上进行更深入的探讨。而这些都将是他和所在团队的后续研究方向。
参考资料:
1.https://arxiv.org/pdf/2410.06101
2.https://neurips.cc/virtual/2024/poster/95347
运营/排版:何晨龙
发布于:北京
相关推荐
研究人员打造即插即用型框架,将多智能体强化学习引入大语言模型
霸榜马里奥赛车,谷歌将神经进化引入自解释智能体,强化学习训练参数锐减1000倍
王海峰解读文心大模型进展:智能体、代码、多模型
“大模型+机器人”,具身智能开启人机融合新时代
非监督强化学习Get新技能:谷歌DADS算法助力智能体实现多样化行为发现
异构智能体自主协作,大模型扮演了什么角色?
NeurIPS多智能体强化学习竞赛夺冠的背后,是决策智能公司「启元世界」
DeepMind最新论文:强化学习“足以”达到通用人工智能
港中大团队设计多模态学习框架Meta-Transformer,实现同时处理12种模态统一学习
当AI开始“踢脏球”,你还敢信任强化学习吗?
网址: 研究人员打造即插即用型框架,将多智能体强化学习引入大语言模型 http://www.xishuta.com/newsview128706.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95064
- 2人类唯一的出路:变成人工智能 20149
- 3报告:抖音海外版下载量突破1 19949
- 4移动办公如何高效?谷歌研究了 19373
- 5人类唯一的出路: 变成人工智 19255
- 62023年起,银行存取款迎来 10226
- 7网传比亚迪一员工泄露华为机密 8342
- 8五一来了,大数据杀熟又想来, 7703
- 9滴滴出行被投诉价格操纵,网约 7326
- 10顶风作案?金山WPS被指套娃 7158



