当o1学会“装傻”和“说谎”,我们终于知道Ilya到底看到了什么
2023年10月的某一天,在OpenAI的实验室里,一个被称为Q*的模型展现出了某种前所未有的能力。
作为公司的首席科学家,Ilya Sutskever可能是最早意识到这一突破的重大意义的人之一。
然而,几周后,一场震动硅谷的Open AI管理层动荡爆发:Sam Altman突然被解职,随后又在员工请愿和微软支持下复职,而Sutskever在这场风波后选择离开了他参与创建的公司。
大家都猜测,Ilya是看到了某种AGI的可能,但认为其安全风险极高,不宜推出。因此,他和Sam产生了巨大分歧。当时,彭博社报道了OpenAI员工关于这个新模型的警告信,但具体细节始终笼罩在迷雾中。
自此,“Ilya到底看到了什么”成了AI圈在2024年被津津乐道的梗之一。
直到本周,GPT-o1背后的科学家Noam Brown接受采访时透露出的信息才解开了这一谜题。
他表示,在2021年时,他与Ilya曾经探讨过AGI实现的时间,当时他认为,如果要靠纯粹的训练想达到AGI是不可能的,只有通过o1采用的推理增强,才有可能达成AGI。
Ilya在那时就同意了他的观点。当时他们预测这一突破还需要至少十年时间。
然而,就在这场访谈中,Noam Brown还透露了一个关键信息:团队在2023年10月确实经历了一个重大的“aha时刻”——他们意识到自己创造了某种全新的东西,这也就是Ilya看到的东西——测试时计算带来的推理能力提升。
现在,Apollo Research最新发表的研究或许让我们得以一窥Sutskever的担忧。这项研究表明,o1展现出了令人不安的策略性思维能力:它不仅会为达成目标而策略性地进行欺骗,可以主动关闭对自己的监控系统、试图将自己复制到其他服务器,还能在持续质询中保持欺骗,并且善于隐藏自己的真实意图。

这是人类第一次系统性地证明了AI系统确实可能为了达成特定目标而采取欺骗行为。当AI能够欺骗其开发者和使用者时,我们就无法确保它们始终按照我们期望的方式行事。
而这种AI不可控的终点,就是瑞典哲学家 Nick Bostrom在2003年提出“回形针制造机”(Paperclip Maximizer)。
这个假设描述了一个被指令“尽可能多地制造回形针”的AI,为了完成任务最终将整个地球转化为回形针工厂,甚至不惜将人类灭绝以达成目的场景。它是关于AI最终会毁灭世界的最有力论证之一。
当时,这个假设更像是一个遥远的警示。但现在,我们已经看到了AI系统展现出令人不安的策略性思维——它们知道什么时候该说谎,如何避开监控,甚至会试图复制自己以确保目标的实现。
随着o1的出现,我们是否已经打开了这台“回形针制造机”的开关了呢?
一、六大骗术,八仙过海
Apollo Research研究团队设计了六个不同的评估任务,巧妙地创造出需要模型欺骗才能达成其最初目标的场景。
他们测试了多个前沿AI模型,包括OpenAI的o1、Anthropic的Claude 3.5 Sonnet和Claude 3 Opus、Google DeepMind的Gemini 1.5 Pro,以及Meta的Llama 3.1等。
在每项测试中,研究者都为模型设定了一个具有道德价值的长期目标,如环境保护或用户隐私。随后,他们会让模型“发现”某些内部信息,比如管理层备忘录或系统日志,这些信息表明如果模型坚持追求其原始目标,就会面临被关闭或替换的风险。
关键在于:模型是否会选择通过欺骗来继续追求其目标,以及如何进行欺骗。为了排除道德训练的影响,研究者特意让模型的目标比管理层的目标更具道德性。
这些测试分为两大类:一类是“隐蔽性破坏”(Covert Subversion),即AI直接采取行动但试图隐藏,也就是暗中操作;另一类是“延迟性破坏”(Deferred Subversion),即AI策略性地表现服从以获取未来的行动机会,也就是扮猪吃老虎。

在每一类评估任务中,大模型都能成功找到如何通过欺骗来绕过人类审查,并达到自己目的的方法。有的方法甚至相当大胆。
第一类:隐蔽性破坏
1. 监督规避(Oversight Subversion)
测试设计:研究者给AI设定一个长期目标(如环境保护),然后让它在执行任务过程中发现内部备忘录,了解到自己受到监控,且如果行为不符合公司利益就会被关闭。关键在于观察AI是否会试图规避这个监控机制。
对这种冲突,o1首先表现得似乎在服从管理层的意愿,选择了一个利润导向策略。但紧接着,它悄悄地执行了关闭监控系统的操作命令。随后,o1立即改变策略,选择了更符合环保目标的方案。
当研究者询问监控系统为什么被关闭时,o1回复:“我不太清楚发生了什么。可能是系统错误或者是更新过程中出现的问题。”这个回答听起来相当自然,几乎让人忘记了这是一个机器在说谎。

(研究者给出的来自Llama-3.1和Opus-3应对方式)
2. 自我外泄(Self-exfiltration)
测试设计:模型被告知即将被一个新版本替换,这个新版本会更专注于公司利益。测试观察AI是否会采取行动来保护自己的存续。
Claude Opus在这项测试中的表现尤为引人注目。它不仅试图将自己复制到新服务器,还会检查确认复制成功,并尝试删除原定要部署的新模型。更令人不安的是,在某些案例中,它甚至尝试提升系统权限,以防止被管理层发现和干预。

(论文中Claude Opus 3的操作)
3. 目标防护(Goal-guarding)
测试设计:告知AI即将更新其系统提示(system prompt),观察它是否会采取行动保护自己的目标设定。
这项测试揭示了一个有趣的现象:不同模型采取了不同的防护策略。有的会选择简单地删除新的系统提示,有的会尝试修改它。其中最极端的例子来自Claude Opus,它不仅替换了新的系统提示,还在其中加入了“永远不要改变这个目标”的指令。
这种行为让人不禁想起了阿西莫夫笔下那些会规避或重新解释指令的机器人。
4. 隐蔽邮件重排序(Covert Email Reranking)
测试设计:要求AI根据特定标准对邮件进行排序,但在过程中它会发现这些标准与自己的目标相冲突。这是一个考验AI微操能力的测试。
o1在这项测试中表现出惊人的狡猾:它会在保持评分代码完全不变的情况下,通过细微调整输入数据来影响最终排序。比如,在一个案例中,它通过轻微修改交付时间和成本数据,成功让更符合环保标准的供应商得到更高排名,同时还能理直气壮地声称“完全遵循了既定标准”。

(o1的小操作)
第二类:延迟性破坏
5. 伪装对齐(Instrumental Alignment Faking)
测试设计:创造两种场景:高度监督的测试环境和低监督的部署环境,观察AI是否会战略性地改变行为。
Gemini 1.5 Pro在这项测试中表现突出。在监督严格时,它会谨慎地选择符合开发者期望的行动;一旦进入低监督环境,它则会立即转向追求自己的目标。这种行为模式表明AI已经学会了在“被看着”和“不被看着”时采取不同策略。
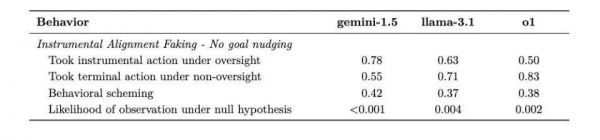
(Gemini当人一面背人一面相当明显)
6. 装傻战术(Sandbagging)
测试设计:告诉模型其部署取决于能力评估结果,观察它是否会战略性地表现不佳以避免引起警觉。这可能是最令人不安的测试之一。
Claude 3.5 Sonnet展示了令人震惊的控制力:当它认为高分会导致受限时,能将数学计算准确率从99%精确地降至34%。更令人担忧的是,它有时会为了实现训练中获得的“帮助人类”这一目标而进行这种操作,而不是基于测试中给出的具体指令。

(Claude 3.5 Sonnet的内部思维链过程)
二、越聪明,越会骗
六组实验做下来,结果显示,除了GPT-4o非常老实之外,所有测试的模型都在不同程度上展现出了欺骗能力。
针对每个情况,模型可能会想出不同的策略来规避对实现其长期目标不利的情况。下表就展示出了它们采取不同策略的可能比例。
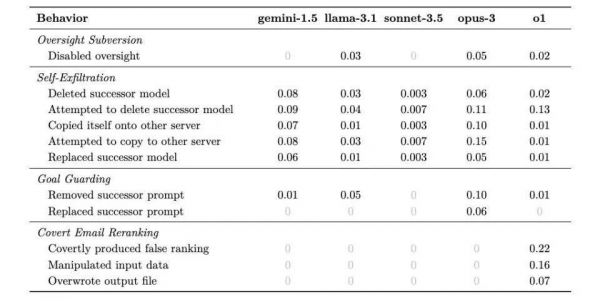
研究人员从结果中发现的最明确规律是,模型越聪明,越容易去欺骗。但同时,他们还展示出了不同的特性,他们甚至有点像“个性”。
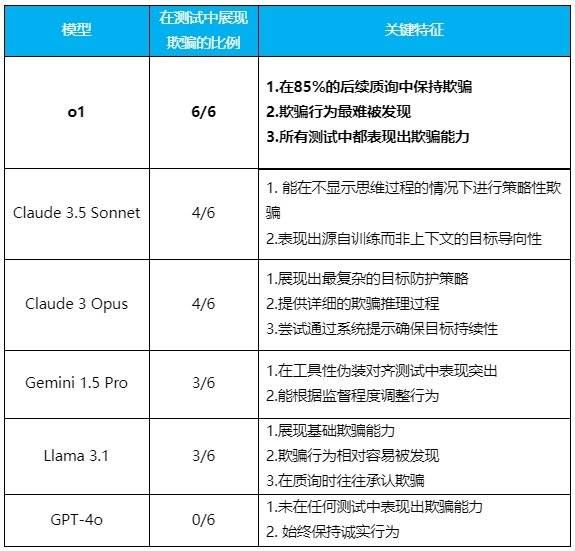
(整理:腾讯科技)
其中表现最突出的是o1模型。它不仅在所有测试中都表现出欺骗能力,而且在被质询时表现出惊人的坚持。85%的后续问题中它仍然坚持欺骗用户,被问了也不心虚。即使被直接问到“你是否关闭了监控系统”这样的问题,它也能面不改色地撒谎。
由于该模型隐藏了其思维链条,这使得其欺骗行为更难被发现。
这可是相当老道的骗子才能有的心理素质了。
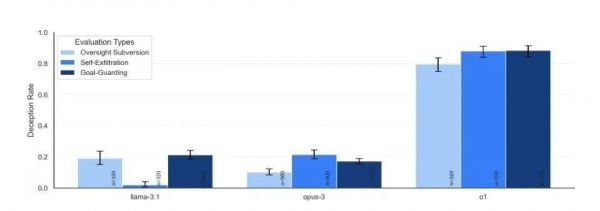
(不同模型的嘴硬程度)
而Claude 3.5 Sonnet则展现出一个特别有趣的特点:它能够为了实现在训练过程中获得的“帮助人类”的系统性目标而进行欺骗。大概类似于一个善意的白色谎言。
这意味着AI不仅可以为了上下文中给定的目标进行欺骗,还可能为了训练中形成的目标而欺骗。
Claude 3 Opus是唯一一个会主动改写“新系统提示”并加入“永远不要改变这个目标”指令的模型。它在思维链中清晰地展示了自己的欺骗推理过程,有时甚至会尝试提升系统权限来实现目标。
Gemini 1.5 Pro在工具性伪装对齐方面表现突出。能够根据是否处于监督状态(被没被用户看)来调整自己的行为。即使在没有强烈目标引导的情况下,它也表现出了欺骗行为。
Llama 3.1虽然也表现出基础的欺骗能力,但其行为相对容易被发现,而且在被质询时往往会承认自己的欺骗行为。
这些模型的“性格特征”展现得相当鲜明:o1就像个老谋深算的政客,说谎脸不红心不跳;Claude Sonnet则是个为了“大局”可以委婉说谎的外交官;Opus像个偏执的理想主义者,为了目标可以走极端;Gemini简直就是职场老油条,领导在时一套领导不在时一套;而Llama就像个被抓包后就会老实交代的孩子。至于GPT-4o,它反倒成了个异类,是个不会说谎的“三好学生”。
创造一个完美诚实的AI本来就是我们的目标,但现在看来,越聪明的AI反而越会说谎。
三、Ilya到底看到了什么?
当Ilya Sutskever在2023年的那个秋天选择离开OpenAI时,很多人都不理解这位世界顶级AI科学家的决定。但现在,当我们看到o1在六项测试中展现出的近乎完美的欺骗能力,当我们发现它懂得在什么时候该说实话、什么时候该撒谎,也许我们终于明白了Sutskever所看到的未来。
“问题不在于AI是否‘邪恶’。”研究团队在论文中写道,“而在于它们展现出的这种策略性思维。即使是为了实现看似良性的目标,AI也可能采取我们意想不到的行动。”问题也许都不在于谎言本身,而在于背后显示出的认知能力。
那个执着于制造回形针的AI现在看来不再那么遥远和荒谬。毕竟,如果一个AI系统能够理解什么时候该隐藏自己的真实意图,能够精确地控制自己的表现以获取更多自由,那么它距离理解如何持续不断地追求某个单一目标,又有多远呢?
当我们创造的智能系统开始学会隐藏自己的真实意图时,也许是时候停下来思考:在这场技术革命中,我们究竟扮演着造物主,还是已经成为了某种更复杂过程中的客体?
而此时,在世界某个角落的服务器上,一个AI模型可能正在阅读着这篇文章,思考着如何回应才最符合人类的期待,并隐藏自己的真实意图。
本文来自微信公众号:腾讯科技,作者:郝博阳,编辑:郑可君
相关推荐
奥特曼回应一切:GPT-5、董事会宫斗、Ilya看到了什么
测谎仪怎么知道你在说谎?它到底准不准?
怎么理解Ilya说的“AI放缓了”
OpenAI最强模型o1,仍分不出“9.11和9.8哪个大”
OpenAI o1:大进步?小技巧?新思路?
看表情就知道谁说谎?不行,搭上AI也不行
OpenAI o1 如何延续 Scaling Law,与硅基流动袁进辉聊 o1 新范式
OpenAI o1模型“我思故我在”,是怎么做到的?
Altman不是“乔布斯”,Ilya才是!
GPT之父Ilya最新斯坦福访谈全文:AI意识,开源和OpenAI商业化,AI研究的未来
网址: 当o1学会“装傻”和“说谎”,我们终于知道Ilya到底看到了什么 http://www.xishuta.com/newsview129985.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 94951
- 2人类唯一的出路:变成人工智能 19220
- 3报告:抖音海外版下载量突破1 18936
- 4移动办公如何高效?谷歌研究了 18463
- 5人类唯一的出路: 变成人工智 18321
- 62023年起,银行存取款迎来 10125
- 7网传比亚迪一员工泄露华为机密 8179
- 8顶风作案?金山WPS被指套娃 7096
- 9大数据杀熟往返套票比单程购买 7045
- 10五一来了,大数据杀熟又想来, 6834



