英伟达的筹码,又少了一枚
本文来自微信公众号:电子工程世界 (ID:EEworldbbs),作者:付斌
自从生成式AI彻底火热以来,英伟达便乘势而上,着实火热一把。之所以数据中心离不开英伟达,一方面在于GPU,另一方面在于互连技术——英伟达的InfiniBand和NVLink。
用句人话解释,互连技术把每张GPU卡乃至服务器都编织成了一张巨大的网,在这张网上,每个节点间犹如铺设一条条“高速公路”,充分释放了GPU集群的潜力。
2020年,英伟达完成对Mellanox收购,经过这次收购获取InfiniBand、Ethernet、SmartNIC/DPU及LinkX互连的能力。自此,英伟达就被业界誉为“同时拥有NVLinkInfiniBandEthernet技术的‘三头蛇怪’。
虽说英伟达的InfiniBand和NVLink两种私有协议性能都很强劲,但封闭是其“原罪”,在一定程度上制约了技术的持续演进与效能优化潜力。同时,也等于是把客户完全“套牢”了。
对厂商来说,过于垄断势必会降低自己产业链的韧性。因此,为了对抗摆脱现在这种状态,行业现在开始通过成立联盟,制定公开的协议标准。不仅能够包容更多玩家,方案更为灵活,同时众人拾柴火焰高,参与的玩家越多,互连技术进化得就越快,协议标准也就越趋于统一。更重要的是,对于国内玩家来说这是一个好消息,能够建设一个自主的联盟和标准。
昨日,新思科技(Synopsys)在业界率先推出Ultra Ethernet IP和UALink IP解决方案。作为对标英伟达的InfiniBand和NVLink的两大技术,相比来说,新思的方案更为开放。可以说,英伟达立足市场的筹码,又少了一枚。
看懂智算集群的互连
当前智算集群内,围绕着GPU存在三大互连,分别是业务网络互连、Scale Out(横向/水平扩展)网络互连、Scale Up(向上/垂直扩展)网络互连,它们分别承载了不同的职责:跨业务、集群内、超级点GPU之间连通性。
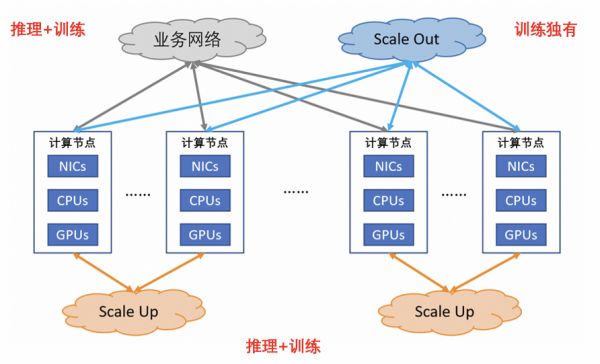
目前,Scale Up互连和Scale Out互连两大领域在AI浪潮中备受关注,因为他们能够为AI提供:
Scale Up互连是“GPU和GPU互连”,是做更大芯片扩展的服务器,是内存和显存共享访问的语义,特点是极低延迟和大带宽,规模在柜内,可扩展为多柜到百芯片级(只是一种能力保留,但是未来很多年都看不到应用),是独立Fabric连接,完全不同于以太网。
Scale Out互连是“服务器之间是基于网卡+交换机的集群互连”,是以太网协议,规模在万级以上,普适的互连。
都是增强现有系统能力,处理更大规模能力,为什么要分成Scale Up和Scale Out两张网?
两张网络的目标不同,Scale Out是在计算集群内部,利用外置网卡技术,通过横向扩展机柜的数目,实现到数万甚至数十万张卡的互连;Scale Up是超节点内部,采用GPU直出技术,通过十倍于Scale Out的吞吐能力,达成数十、数百的GPU高效协同。
这两张网,将业务逻辑紧密耦合在一起。可以说,两张网对于AI,尤其是AIGC或LLM都相当重要。AI基础设施的计算效能要求很高,为了最大化达成端到端MFU,需要Scale UP和Scale Out都进行最大程度的优化。由于需要解决的互连问题各不相同,尤其是10倍左右的流程差异,Scale UP需要采用不同于Scale Out的协议设计来将性能发挥到极致。
目前业界主流的GPU芯片厂家都会考虑Scale Up采用独立的Link技术,不会和Scale Out合并设计。
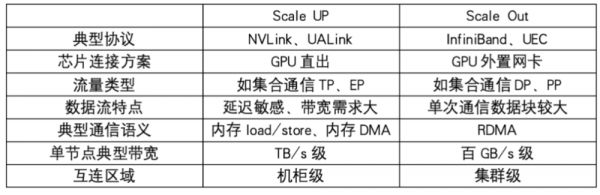
围攻InfiniBand:UCE破茧而出
在Scale Out领域,英伟达是InfiniBand路线的主要玩家,多年以来都具备一定统治地位。虽然英伟达的布局了两种类型网络,一种是传统InfiniBand和Ethernet网络,另一种是NVLink总线域网络,以形成大型AI算力网络,但目前主要还是使用InfiniBand技术。
在过去的二十五年里,我们见证了以太网和InfiniBand之间的史诗般的战斗。事实证明,InfiniBand在HPC中很难被击败,至少在目前,InfiniBand是AI训练集群中后端网络的首选低延迟、高带宽互连。但是,随着超以太网联盟(Ultra Ethernet Consortium,简称UEC)的成立,以太网将能够比InfiniBand更进一步地扩展,并且将具有InfiniBand仍然缺少的一些属性。
去年7月,AMD、Arista、Broadcom、Cisco、Eviden(Atos旗下公司)、HPE、Intel、Meta和Microsoft等公司作为创始成员联合成立UEC。这是一个由Linux基金会主持的组织,致力于开发物理层、链路层、传输层和软件层以太网技术,国内阿里云、百度、世纪互联、字节跳动、华为、新华三、光迅科技、腾讯、锐捷网络等都已加入。而在今年7月,时隔一年,有消息称英伟达已正式加入UEC。展望未来,UEC V1.0规范将于2025年第一季度发布。
可以说,自从UEC诞生以来,已有大部分客户开始倒戈,甚至英伟达自己也开始加入到公开协议中,颇有取代InfiniBand技术之势,迅速成为GPU新的加速节点。一些公司也因此获得了丰厚的利润,例如Arista公司的AI集群互连销售额显著增长。
UEC将提供基于以太网的开放、可互操作、高性能的全通信堆栈架构,以满足大规模人工智能和高性能计算不断增长的网络需求。
与传统以太网不同,所谓超以太网(Ultra Ethernet)在传输层有了很大改变,同时其他层也有一些提升:
物理层:支持每通道100Gbps和200Gbps速率,在此基础上实现800Gbps和更高的端口速率,可选支持物理层性能指标统计功能(PHY metrics);
链路层:引入了LLR(Link Level Retry)协议,让以太网不依赖PFC,实现无损传输;
网络层:依然是IP协议,没有变化;
传输层:UEC传输层(UEC Transport Layer,简称UET)是新一代协议栈的核心,其运行在IP和UDP协议之上,支持高达100万个GPU/TPU算力集群;往返时间低于10μs;单接口带宽800Gbps及以上;网络利用率超过85%;
软件API层。提供UEC扩展的Libfabrics 2.0。
超以太网(Ultra Ethernet)解决的一个问题是网络尾延迟的影响。尾延迟是指偶尔的数据报在通过网络时所经历的显著较长的延迟。这种延迟可能导致系统因数据包丢失或拥塞而短暂停滞。超以太网将通过允许乱序的数据包传输,并结合低层智能重传机制来解决这一问题。减少AI处理器的停顿可以提高性能,最大化这些高价值资源的利用率和效率。

突袭NVLink:UALink成为共识
在Scale Up领域,当前行业主流多采用闭环的自有协议方案。其中,业界发展最早和最成熟的是英伟达的NVLink技术,可以将GPU和GPU互连,至多让576个GPU实现每秒1.8TB的通信。其他自有协议则包括谷歌TPU的OCS+ICI架构及AWS的NeuronLink。
10月28日,AMD、AWS、谷歌和思科等九家巨头宣布正式成立UALink联盟(Ultra Accelerator Link Consortium,简称UALink联盟),主推AI服务器Scale UP互连协议——UALink。而今,博通中途退出,新增AWS、Astera两家公司。目前,UALink联盟已公开邀请新成员加入,国内已有盛科、联想、澜起科技、联动等公司加入成为贡献者成员。与UEC相同,UALink V1.0标准将于2025年第一季度发布。
UALink是新一代AI/ML集群性能的高速加速器互连技术,拥有低延迟和高带宽的特点,具备高性能内存语义访问的原生支持,可以完美适配GPU等AI加速器的编程模型,在一个超节点内实现一点规模的AI计算节点互连。除此之外,UALink的优势还包括显存共享,支持Switch组网模式,以及超高带宽和超低时延能力等。
该技术规范定义了一种创新的I/O架构,单通道可达200 Gbps传输速率,支持最多1024个AI加速器互连。相比传统以太网(Ethernet)架构,UALink在性能和GPU互连规模上都具有显著优势,互连规模更是大幅超越Nvidia NVLink技术。以Dell PowerEdge XE9680服务器为例,单台服务器最多支持8块AMD Instinct或Nvidia HGX GPU。采用UALink技术后,可实现百台级服务器集群内GPU的直接低延迟访问。
更重要的是,UALink在加速器、交换芯片、Retimer等互连技术上保持中立立场,不偏向特定厂商,目标是建立开放创新的技术生态系统。
考虑到针对终态进行设计,以及共同对抗行业垄断的目的,AMD将其迭代多年的Infinity Fabric协议贡献出来,促成UALink联盟的成立,希望在更多行业伙伴的助力下,持续发挥原生为GPU互连场景设计的优势,使其成为行业的开放标准。
UALink的一大好处是让业内的其他人都有机会跟上英伟达的步伐。英伟达目前已经将NVSwitch放在了NVIDIA DGX GB200 NVL72等产品的规模,但AI加速器并非只有英伟达一家,比如说英特尔今年销售了几亿美元、数万个AI加速器,AMD今年也将售出数十亿美元的MI300X。拥有UALink后,像Broadcom这样的公司可以制作UALink交换机,以帮助其他公司扩大规模,然后在多家公司的加速器中使用这些交换机。
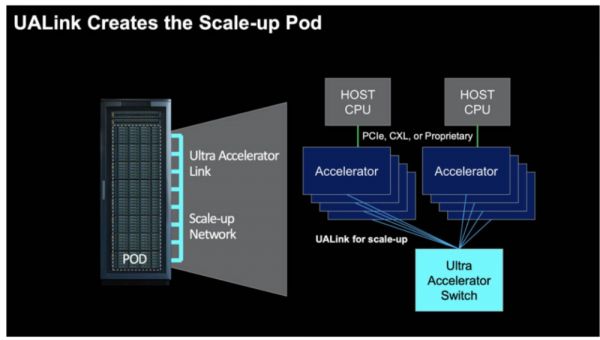
这一协议一经推出便广受关注,国际的主流厂商,尤其是云计算为代表的应用厂商和原持有自有协议方案的公司都积极加入UALink。目前,UALink已经成为最具潜力的AI服务器Scale UP(纵向/垂直扩展)互连开放标准,正在迅速构建起一个AI服务器Scale Up互连技术的超级开放生态。截止11月,UALink联盟已有三十余家厂商加入,并在持续扩展中;且涵盖了云计算和应用、硬件、芯片、IP等产业全生态。
标准还没到,但行业已经开始行动
无论是UEC,还是UALink,1.0版本标准都将在2025年第一季度推出。不过,目前已经有很多先行者开始布局相关技术,新思科技就是其中之一。
根据新思科技的介绍,通过推出Ultra Ethernet IP和UALink IP解决方案来满足对高带宽、低延迟互连的需求,这些解决方案提供了扩展当今和未来AI和HPC架构所需的接口:Ultra Ethernet IP解决了横向扩展(通过网络结构)的问题,提供高性能、与供应商无关的链路,用于连接大型AI网络中多达100万个节点;UALink则解决了纵向扩展(在机架内)问题,为连接一千多个AI加速器提供了高速、低延迟的链接。

其中,Ultra Ethernet IP解决方案基于经过硅验证的技术构建,将实现1.6 Tbps的超高带宽和超低延迟,从而扩展(横向)大规模AI网络。而新思的UALink IP解决方案将提供每通道高达200 Gbps的带宽和内存共享功能,以扩展(向上)加速器连接。
在UEC方面,AMD在今年10月发布业界首款UEC就绪AI NIC——Pollara 400。它使用相同的第三代P4引擎,提供UEC就绪RDMA的性能优势。
在UALink方面,核心成员已开始布局底层技术。今年10月,Astera Labs推出的Scorpio系列交换芯片,其中P-Series支持基于PCIe Gen 6的GPU-CPU互连(可定制化),X-Series专注于GPU-GPU互连。
随着先行者越来越多,一个更为开放的生态正在建立。而对英伟达来说,这或许也不是什么坏消息,毕竟这种开放的生态英伟达也可以加入,而且英伟达本身也希望开放生态。只不过,可能以后就不会像私有协议那样具备垄断性了。
相关推荐
年薪百万,每年还发股票,英伟达员工还是觉得赚少了
英伟达巨资拿下ARM,意味着什么?
英伟达的阳谋,收购Arm的危险讯号
“阉割版”AI芯片,也能让英伟达赚疯?
本周,又到了“英伟达时刻”
英伟达为何力推“主权AI”
英伟达新核弹,站在苹果的肩膀上
英伟达进入多事之秋,但它的护城河仍然坚固
英伟达的最大威胁是什么?
英伟达史上最高并购背后的压力
网址: 英伟达的筹码,又少了一枚 http://www.xishuta.com/newsview130104.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95203
- 2人类唯一的出路:变成人工智能 21024
- 3报告:抖音海外版下载量突破1 20955
- 4移动办公如何高效?谷歌研究了 20186
- 5人类唯一的出路: 变成人工智 20185
- 62023年起,银行存取款迎来 10317
- 7网传比亚迪一员工泄露华为机密 8472
- 8五一来了,大数据杀熟又想来, 8452
- 9滴滴出行被投诉价格操纵,网约 8075
- 10顶风作案?金山WPS被指套娃 7219



