反转,Claude 3.5超大杯没有训练失败
传闻反转了,Claude 3.5 Opus没有训练失败。
只是Anthropic训练好了,暗中压住不公开。
semianalysis分析师爆料,Claude 3.5超大杯被藏起来,只用于内部数据合成以及强化学习奖励建模。
Claude 3.5 Sonnet就是由此训练而来的。

使用这种方法,推理成本没有明显提升,但是模型性能更好了。
这么好用的模型,为啥不发布?
不划算。
semianalysis分析,相较于直接发布,Anthropic更倾向于用最好的模型来做内部训练,发布Claude 3.5 Sonnet就够了。
这多少有些让人不敢相信。

但是文章作者之一Dylan Patel也曾是最早揭秘GPT-4架构的人。

除此之外,文章还分析了最新发布的o1 Pro、神秘Orion的架构以及这些先进模型中蕴藏的新规律。
比如它还指出,搜索是Scaling的另一维度,o1没有利用这个维度,但是o1 Pro用了。
网友:它暗示了o1和o1 Pro之间的区别,这也是之前没有被披露过的。

新旧范式交迭,大模型还在加速
总体来看,semianalysis的最新文章分析了当前大模型开发在算力、数据、算法上面临的挑战与现状。
核心观点简单粗暴,总结就是:新范式还在不断涌现,AI进程没有减速。
文章开篇即点明,Scaling law依旧有效。
尽管有诸多声音认为,随着新模型在基准测试上的提升不够明显、现有训练数据几乎用尽,以及摩尔定律放缓,大模型的Scaling Law要失效了。
但是顶尖AI实验室、计算公司还在加速建设数据中心,并在底层硬件上砸了更多钱。
比如AWS斥巨资自研Trainium2芯片,花费65亿美元为Anthropic准备40万块芯片。
Meta也计划在2026年建成耗电功率200万千瓦的数据中心。
很明显,最能深刻影响AI进程的人们,依旧相信Scaling Law。
为什么呢?
因为新范式在不断形成,并且有效。这使得AI开发还在继续加速。
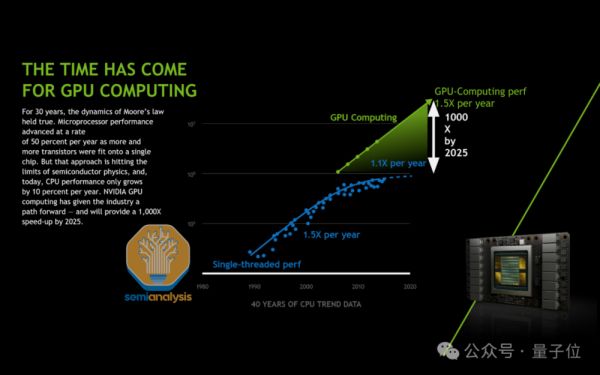
首先,在底层计算硬件上,摩尔定律的确在放缓,但是英伟达正在引领新的计算定律。
8年时间,英伟达的AI芯片计算性能已经提升了1000倍。
同时,通过芯片内部和芯片之间的并行计算,以及构建更大规模的高带宽网络域,可以使得芯片更好地在网络集群内协同工作,特别是在推理方面。
其次,在数据方面也出现了新的范式。
已有公开数据消耗殆尽后,合成数据提供了新的解决途径。
比如用GPT-4合成数据训练其他模型是很多实验团队都在使用的技术方案。
而且模型越好,合成数据质量就越高。
也就是在这里,Claude 3.5 Opus不发布的内幕被曝光了。
它承担了为Claude 3.5 Sonnet合成训练数据、替代人类反馈的工作。
事实证明,合成数据越多,模型就越好。更好的模型能提供更好的合成数据,也能提供更好的偏好反馈,这能推动人类开发出更好的模型。
具体来看,semianalysisi还举了更多使用综合数据的例子。
包括拒绝采样、模式判断、长上下文数据集几种情况。
比如Meta将Python代码翻译成PHP,并通过语法解析和执行来确保数据质量,将这些额外的数据输入SFT数据集,这也解释了为何缺少公共的PHP代码。

比如Meta还使用Llama 3作为拒绝采样器,判断伪代码,并给代码进行评级。一些时候,拒绝抽样和模式判断一起使用。这种方式的成本更低,不过很难实现完全自动化。
在所有拒绝抽样方法中,“判官”模型越好,得到的数据集质量就越高。
这种模式Meta在今年刚刚开始用,而OpenAI、Anthropic已经用了一两年。
在长上下文方面,人类很难提供高质量的注释,AI处理就成为一种更有效的方法。
然后在RLHF方面,专门收集大量的偏好数据难且贵。
对于Llama 3,DPO(直接偏好优化)比PPO(最近策略优化)更有效且稳定,使用的计算也少。但是使用DPO就意味着偏好数据集是非常关键的。
OpenAI等大型公司想到的一种办法是从用户侧收集,有时ChatGPT会给出2个回答并要求用户选出更喜欢的一个,因此免费收集了很多反馈。
还有一种新的范式是让AI替人类进行反馈——RLAIF。
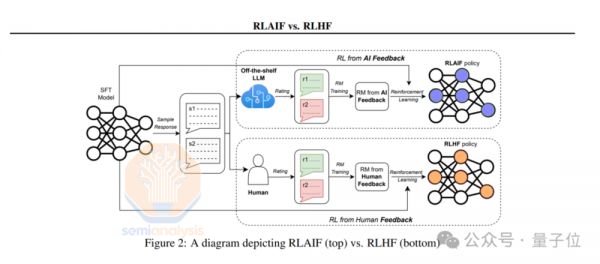
它主要分为两个阶段。第一阶段,模型先根据人类编写的标准对自己的输出进行修改,然后创建出一个包含“修订-提示对”的数据集,再使用这些数据集通过SFT进行微调。
第二阶段类似于RLHF,但是这一步完全没有人类偏好数据。
这种方法最值得关注的一点是,它可以在许多不同的领域得到扩展。

最后,值得重点关注的一个新范式是通过搜索来扩展推理计算。
文章中表明,搜索是扩展的另一个维度。OpenAI o1没有利用这个维度,但是o1 Pro用了。
o1在测试时阶段不评估多条推理路径,也不进行任何搜索。
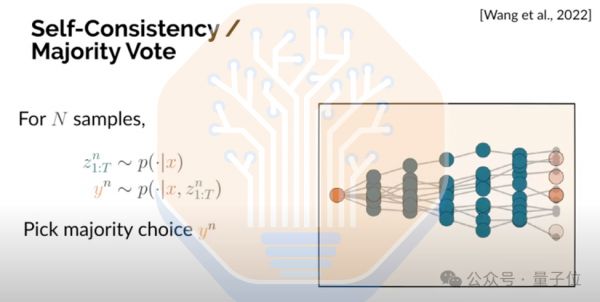
Self-Consistency / Majority Vote就是一种搜索方法。在这种方法中,只需在模型中多次运行提示词,产生多个响应,根据给定的样本数量,从响应中选出出现频率最高的作为正确答案。
除此之外,文章还进一步分析了为什么说OpenAI的Orion训练失败也是不准确的。
感兴趣的读者可以阅读原文。
本文来自微信公众号:量子位,作者:明敏
相关推荐
反转,Claude 3.5超大杯没有训练失败
赶超GPT-4o,最强大模型Llama3.1405B 一夜封神
OpenAI最强竞对Claude再次出牌
OpenAI最强竞品大更新,一句话模拟人类用电脑
李开复发布零一万物“闪电模型” 称没有放弃预训练也未亏钱拉新
开源大模型Llama 3来了,能干得过GPT-4么?
谷歌Pixel 9系列发布,包括大杯、超大杯和1款大折叠
马斯克力挺扎克伯格,OpenAI“0元”应战
Claude 3追上GPT-4,它来自怎样一家公司?
Anthropic的Claude 3,解决了困扰OpenAI的难题
网址: 反转,Claude 3.5超大杯没有训练失败 http://www.xishuta.com/newsview130124.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95088
- 2人类唯一的出路:变成人工智能 20304
- 3报告:抖音海外版下载量突破1 20127
- 4移动办公如何高效?谷歌研究了 19524
- 5人类唯一的出路: 变成人工智 19425
- 62023年起,银行存取款迎来 10245
- 7网传比亚迪一员工泄露华为机密 8365
- 8五一来了,大数据杀熟又想来, 7851
- 9滴滴出行被投诉价格操纵,网约 7477
- 10顶风作案?金山WPS被指套娃 7167



