OpenAI o3被曝智商高达157,比肩爱因斯坦,但却没法证明比人类聪明
本文来自微信公众号:APPSO (ID:appsolution),作者:发现明日产品的,原文标题:《OpenAI o3 被曝智商高达 157,比肩爱因斯坦,但却没法证明比人类聪明》
一觉醒来,突然发现AI的智商比肩爱因斯坦了。
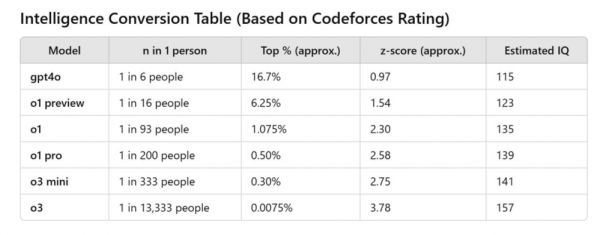
根据外网疯传的一张图表,OpenAI新模型o3在Codeforces上的评分为2727,转换成人类智商的分数也就相当于157,妥妥万里挑一。
并且,更夸张的是,从GPT-4o到o3,AI的智商仅用时7个月就飙涨了42分。
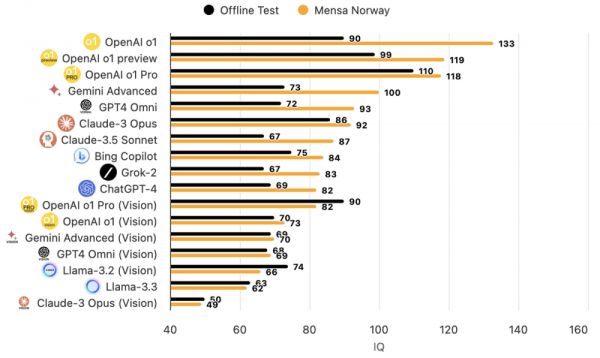
包括前不久尤为备受吹捧的是,OpenAI的o1模型在门萨智商测试中得分更是高达133,超过了大多数人类的智商水平。
然而,先别急着感慨人类在AI面前的一败涂地,不妨先停下来思考一个更为根本的问题,那就是用专门衡量人类智商的尺子来丈量AI,是否真的恰当?
聪明的AI,也会犯最基础的错误
任何有过AI使用经验的用户都能清晰地得出一个结论,对AI进行人类智商测试虽说有一定意义,但也存在严重的局限性。
这种局限首先源于测试本身的设计初衷。
传统智商测试是一套专门针对人类认知能力的评估体系,它基于人类特有的思维模式,涵盖了逻辑推理、空间认知和语言理解等多个维度。
显然,用这样一套「人类标准」去评判AI,本身就存在方法论上的偏差。
关注AI第一新媒体,率先获取AI前沿资讯和洞察
深入观察人类大脑和AI的差异,这种偏差更为明显。
人类的大脑拥有约860亿个神经元,但研究表明,突触连接的数量和复杂度可能比神经元数量更为重要,其中人类大脑有大约100万亿个突触连接。
相比之下,2023年Nature期刊上的研究显示,即便是参数量达到1.76万亿的GPT-4,其神经网络的连接模式也远不及人类大脑的复杂程度。
从认知过程的流程来看,人类是按照「感知输入→注意过滤→工作记忆→长期记忆存储→知识整合」的路径进行思考。
而AI系统则遵循「数据输入→特征提取→模式匹配→概率计算→输出决策」的路径,形似而神异。
因此,尽管当下的AI模型在某些方面确实模仿了人类的认知功能,但本质上仍然只是一个基于特定算法的概率机器,其所有输出都源于对输入数据的程序化处理。
前不久,苹果公司发表的研究论文就指出,他们在语言模型中找不到任何真正的形式推理能力,这些模型的行为更像是在进行复杂的模式匹配。
而且这种匹配机制极其脆弱,仅仅改变一个名称就可能导致结果产生约10%的偏差。
用爬树能力评判鱼类,它终其一生都会觉得自己是个笨蛋。同理,用人类标准衡量AI同样可能产生误导性判断。
以GPT-4o为例,看似智商远超人类平均水平100分的光环背后,是连9.8和9.11都分不清大小的尴尬现实,而且还经常产生AI幻觉。
包括OpenAI在自己的研究中也坦承,GPT-4在处理简单的数值比较时仍会犯基础性错误,AI所谓的「智商」可能更接近于单纯的计算能力,而非真正意义上的智能。
这就不难理解为什么我们会看到一些暴论的出现。
比如Deepmind CEO和Yann Lecun声称当前AI的实际智商甚至不如猫,这话虽然听起来刺耳,但话糙理不糙。
实际上,人类一直在为量化AI的聪明程度寻找合适的评估体系,既要容易度量,又要全面客观。
其中最广为人知的当属图灵测试。如果一台机器能在与人类的交流中完全不被识破,就可以被认定为具有智能,但图灵测试的问题也很明显。它过分关注语言交流能力,忽视了智能的其他重要维度。
与此同时,测试结果严重依赖于评估者的个人偏见和判断能力,一个机器即便通过了图灵测试,也不能说明它真正具备了理解能力和意识,可能仅仅是在表层模仿人类行为。
就连素有「智商权威」之称的门萨测试,也因其针对特定年龄组人类的标准化特点,而无法为AI提供一个「真实可信」的智商分数。
那么,如何才能向公众直观地展示AI的进步?
答案或许在于将评估重心转向AI解决实际问题的能力。相比智商测试,针对具体应用场景设计的专业评估标准(基准测试)可能更有意义。
从「理解」到「背题」,为什么连测试AI都变得如此困难?
从不同维度出考卷,基准测试可谓五花八门。
比如说,常见的GSM8K考察小学数学,MATH也考数学,但更偏竞赛,包括代数、几何和微积分等,HumanEval则考Python编程。
除了数理化,AI也做「阅读理解」,DROP让模型通过阅读段落,并结合其中的信息进行复杂推理,相比之下,HellaSwag侧重常识推理,和生活场景结合。
然而,基准测试普遍存在一个问题。如果测试数据集通常是公开的,一些模型可能在训练过程中已经提前「预习」过这些题目。
这就好比学生做完整套模拟题,甚至真题后再参加考试一样,最终的高分可能并不能真实反映其实际能力。
在这种情况下,AI的表现可能仅仅是简单的模式识别和答案匹配,而非真正的理解和问题解决。成绩单看似优秀,却失去参考价值。
并且,从单纯比拼分数,到暗地里「刷榜」,AI也会染上人类的焦虑。比如说号称最强开源大模型的Reflection 70B就曾被指出造假,让不少大模型榜单的可信度一落千丈。
而即便没有恶性刷榜,随着AI能力的进步,基准测试结果也往往会走向「饱和」。
正如Deepmind CEO Demis Hassabis所提出,AI领域需要更好的基准测试。目前有一些众所周知的学术性基准测试,但它们现在有点趋于饱和,无法真正区分不同顶级模型之间的细微差别。
举例来说,GPT-3.5在MMLU上的测试结果是70.0,GPT-4是86.4,OpenAI o1则是92.3分,表面上看,似乎AI进步速度在放缓,但实际上反映的是这个测试已经被AI攻克,不再能有效衡量模型间的实力差距。
如同一场永无止境的猫鼠游戏,当AI学会应对一种考核,业界就不得不寻找新的评估方式。在比较常规的两种做法中,一种是用户直接投票的盲测,而另一种则是不断引入新的基准测试。
前者我们很熟悉了,Chatbot Arena平台是一个基于人类偏好评估模型和聊天机器人的大模型竞技场。不需要提供绝对的分数,用户只需比较两个匿名模型并投票选出更好的一个。
后者,最近备受关注的就是OpenAI引入的ARC-AGI测试。
由法国计算机科学家François Chollet设计,ARC-AGI专门用来评估AI的抽象推理能力和在未知任务上的学习效率,被广泛认为是衡量AGI能力的一个重要标准。
对人类来说容易,但对AI来说非常困难。ARC-AGI包含一系列抽象视觉推理任务,每个任务提供几个输入和对应的输出网格,受测者需要根据这些范例推断出规则,并产生正确的网格输出。
ARC-AGI的每个任务都需要不同的技能,且刻意避免重复,完全杜绝了模型靠「死记硬背」取巧的可能,真正测试模型实时学习和应用新技能的能力。
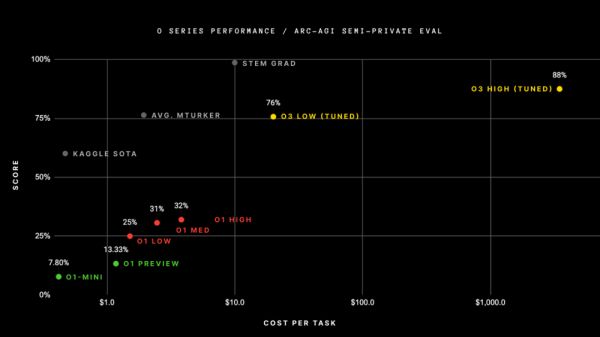
在标准计算条件下,o3在ARC-AGI的得分为75.7%,而在高计算模式下,得分高达87.5%,而85%的成绩则接近人类正常水平。
不过,即便OpenAI o3交出了一份优秀的成绩单,但也没法说明o3已经实现了AGI。就连François Chollet也在X平台发文强调,仍有许多对人类来说轻而易举的ARC-AGI-1任务,o3模型却无法解决。
我们有初步迹象表明,ARC-AGI-2任务对这个模型来说仍然极具挑战性。
这说明,创建一些对人类简单、有趣且不涉及专业知识,但对AI来说难以完成的评估标准仍然是可能的。
当我们无法创建这样的评估标准时,就真正拥有了通用人工智能(AGI)。
简言之,与其执着于让AI在人类设计的各种测试中取得高分,不如思考如何让AI更好地服务于人类社会的实际需求,这或许才是评估AI进展最有意义的维度。
相关推荐
OpenAI o3是AGI吗?
OpenAI放出“王炸”:下一代推理模型o3亮相!
OpenAI发布o3系列模型“剑指”AGI 北大毕业生打造
智商超过99.9%人类,ChatGPT到底有多聪明?
程序员将“不存在”? OpenAI o3发布 傅盛:击败99.9%的程序员
o3意味着什么?2025年“缩放定律”继续,成本更贵也更不可控
AI大牛解析o3技术路线,大模型下一步技术路线已现端倪?
OpenAI被曝自研人形机器人,4年前因缺数据解散团队
OpenAI被曝重大技术突破或威胁人类,引发罢免奥特曼
每天做点什么才能让自己更聪明?
网址: OpenAI o3被曝智商高达157,比肩爱因斯坦,但却没法证明比人类聪明 http://www.xishuta.com/newsview130802.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95178
- 2人类唯一的出路:变成人工智能 20885
- 3报告:抖音海外版下载量突破1 20771
- 4移动办公如何高效?谷歌研究了 20054
- 5人类唯一的出路: 变成人工智 20036
- 62023年起,银行存取款迎来 10307
- 7网传比亚迪一员工泄露华为机密 8456
- 8五一来了,大数据杀熟又想来, 8338
- 9滴滴出行被投诉价格操纵,网约 7960
- 10顶风作案?金山WPS被指套娃 7213



