国产大模型“考研数学”成绩单出炉,哪家AI能上岸?
本文来自微信公众号:学术头条,原文标题:《最高138.7分!国产大模型“考研数学”成绩单出炉,哪家AI能上岸?》
高考、考研数学,旨在考察学生的逻辑推理素养,每年都会难倒一大片准备上岸的学子。
那么,对于被训练成“像人类一样思考”的人工智能(AI)系统,尤其是近期讨论颇多的 o1 类推理模型而言,“数学”这门考试到底难不难呢?
更进一步说,如果同时参加 2025 考研的数学考试,国内头部推理模型与 OpenAI o1 的差距又有多大呢?
日前,来自清华大学人工智能研究院基础模型研究中心的团队,便晒出了国内外 13 个模型(基础模型、深度推理模型)在 2025 年考研数学(一、二、三)上交出的答卷:
直白一点说:o1 最强,但对国产头部模型(如 GLM-zero-preview、QwQ)的领先优势不大。
具体而言,这些推理模型的 2025 考研数学成绩全部达到了 120+,最强模型 OpenAI o1 的分数达到了惊人的 141.3 分(平均),在总计 66 道题目中,仅答错了 3.5 道。
另外,相比于 o1,国内推理模型 GLM-zero-preview(平均 138.7 分)和 QwQ(平均 137.0 分)的表现也并无巨大劣势,分差仅在个位数水平。
第三梯队模型 DeepSeek-r1-lite、Kimi-k1、Tiangong-o1-preview、DeepSeek-v3 的表现也不差,分数均在 120 分以上。
值得注意的是,曾于 2023 年位居榜首的基础模型 GPT-4,在本次测试中仅获得 70.7 分,排名倒数第一。这一结果表明,在过去的一年中,语言模型在数学推理领域取得了显著的进步。
完整评测结果如下:

值得一提的是,尽管 o1 在深度推理方面的表现击败了所有国产推理大模型,但国产大模型正将这一差距逐渐缩小,此次智谱的 GLM-zero-preview 和阿里的 QwQ 的成绩便说明了这一点。
基础模型 vs 深度思考模型
为全面深入地探究各模型厂商在深度思考能力优化方面所取得的成果,评测团队对相应基础模型与深度推理模型进行了对比分析。
他们表示,这一对比并非意味着各深度推理模型是基于对应基础模型所做优化,其主要目的在于直观呈现各厂商在模型综合能力提升方面的进展与成效。
相关对比结果如下图所示:
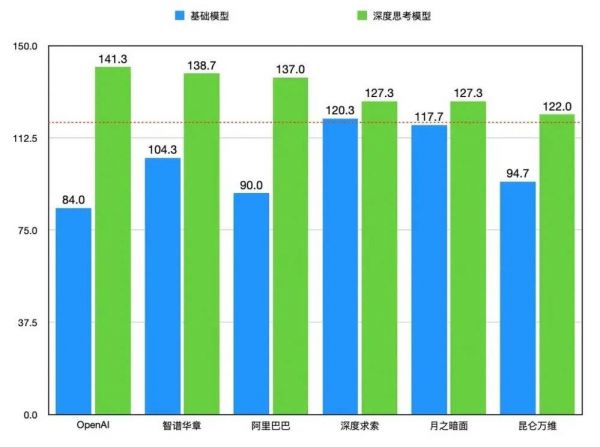
注:OpenAI 的基础模型采用的是 GPT-4o。
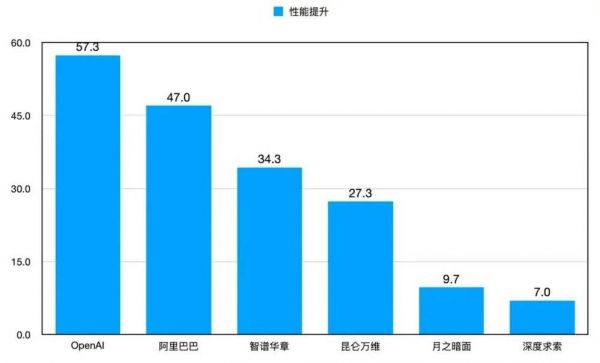
通过对比分析,OpenAI o1 相较于基础模型 GPT-4o 的提升幅度最显著,达到了 57.3 分;阿里的 Qwen 模型和智谱的 GLM 模型,提升幅度紧随其后,分别达到了 47.0 分和 34.3 分。深度求索和月之暗面的模型提升幅度相对较小,这主要是由于其基础模型本身分数较高。
在本次测试中,他们将表现最为优异的基础模型 DeepSeek-v3 作为参照基准,进而对各厂商深度推理模型的性能提升情况进行评估,相关数据呈现如下图所示:

可以看出,智谱、阿里在深度推理模型的性能提升方面做了很大的优化,分数分别为 18.3 和 16.7,接近 OpenAI(21.0)。
评测方法
在本次评测过程中,评测团队发现并非所有模型均提供 API 支持,且部分提供 API 服务的模型在输出内容长度超出一定限制时,会出现内容截断的情况。为确保评测工作的公正性与准确性,他们决定统一采用各模型厂商的网页端进行测试操作。
在测试过程中,每道题目均在独立的对话窗口中进行,以此消除上下文信息对测试结果可能产生的干扰。
鉴于部分模型输出存在一定不稳定性,为降低由此引发的分数波动,他们设定当同一模型在三次测试中有两次及以上回答正确时,方将其记录为正确答案。
本文来自微信公众号:学术头条
相关推荐
国产大模型“考研数学”成绩单出炉,哪家AI能上岸?
考研时代的爱情:上岸第一剑,先斩意中人?
AI开卷数学模型,哪家强?
考研没考上,办考研机构翻身了
8家国产大模型,内容真实性如何?
国产大模型,什么时候能搞出 Sora ?
六战考研,26岁女孩走不出的循环
国产算力和国产大模型,迎来双赢时刻
2024阿里巴巴全球数学竞赛启动,向全球AI大模型广发英雄帖
拆解科大讯飞年报,寻找大模型落地范式
网址: 国产大模型“考研数学”成绩单出炉,哪家AI能上岸? http://www.xishuta.com/newsview131580.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95007
- 2人类唯一的出路:变成人工智能 19724
- 3报告:抖音海外版下载量突破1 19495
- 4移动办公如何高效?谷歌研究了 18957
- 5人类唯一的出路: 变成人工智 18827
- 62023年起,银行存取款迎来 10179
- 7网传比亚迪一员工泄露华为机密 8262
- 8五一来了,大数据杀熟又想来, 7314
- 9顶风作案?金山WPS被指套娃 7131
- 10大数据杀熟往返套票比单程购买 7077



