S型智能增长曲线:从Deepseek R1看Scaling Law的未来
文章来源:@张俊林say
Scaling Law过去是、现在是、将来也会继续是推动大模型快速发展的第一动力,我自己一般是通过它来对大模型未来发展悲观乐观做总体判断的,只要目前Scaling Law仍然成立,其实就没有看衰大模型未来发展的理由,如果硬要看衰,那被打脸的概率相当之大,真正可以看衰大模型未来发展的时机是什么?如果什么时候发现Scaling Law熄火了,此时看衰,赌对的概率会大很多。
最近之所以 Deepseek R1火出天际,一个重要原因是它复现并开源了大模型Post-Training和Inference两个阶段Scaling Law的具体做法,模型效果拔群。关于Scaling Law,我一直有几个疑问,比如 Scaling Law曲线可以无限增长吗?再比如,目前我们有三种Scaling Law(Pre-train、RL、Test Time),它们组合起来的Scaling Law看起来是什么样子?诸如此类的问题。
本文后面打算用S型智能增长曲线来解释我们目前看到的Scaling Law的一些现象。其实智能发展应该遵循S型曲线,这不是新观点,LLM最大的反对派Lecun和第二大反对派马库斯,去年在Twitter上就反复提过这个观点,以此作为否定LLM未来发展的重要依据。我个人是比较赞同用S型曲线来描述AI智能发展的,但可惜的是,关于这个话题并没有后续更深入的讨论,所以计划把它和Scaling Law联系起来,期望对此能有更具深度的一些思考,这里很多都是我自己的推断,还请谨慎参考,权且当做一种思想实验即可。
一.AI智能的S型增长曲线
1.1 世上没有永远持续的增长,只有S型曲线式增长
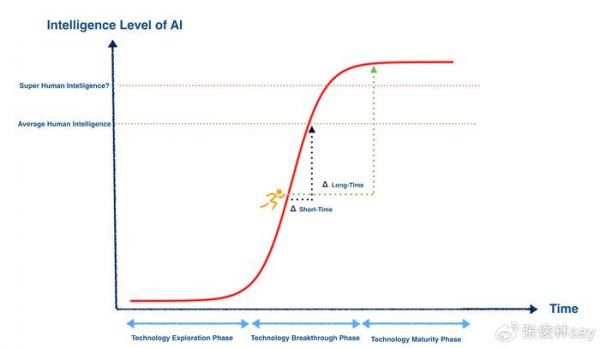
世界上不存在无限增长的事情(说你呢,Scaling Law),这基本是个定则,即使把目光拉长放到宇宙级视野里,宇宙中最大速度也不可能超过光速,宇宙它再大也总有个边界,是吧?所以,我觉得很可能各种看着貌似可以无限增长,但那是因为我们看它的时间窗口还是太短,S型增长曲线(Sigmoid函数刻画的非线性曲线)可能才是更准确对增长准确描述的曲线,要我猜AI智能增长趋势大概也是如此。
随着时间的发展(参考上图),早期AI相关技术处于探索期,不确定性大,进展缓慢,产生重大技术突破后,进入技术突破期,AI智能呈现指数增长态势(Sigmoid函数快速增长阶段),之后进入技术成熟期,AI智能进入平台期,增长缓慢或者停止增长。
假设我们此刻站在快速增长期,此时对未来进行判断,会看到陡峭的智能增长曲线,会倾向于把这种高速增长外推,以为AI智能会永远像现在这样保持指数级的高速增长,但事实是:如果加入短期未来时间增量Δshort-time,看着AI智能确实是处于高速增长,但若把时间周期放长,加入Δ long-time,则会看到不同的景象,Sigmoid智能增长曲线进入平台期,就是说AI智能增长这事情不会一直这样持续下去,早晚总会到顶。当然,这不代表AI的智能不会超过人类平均水平,甚至达到SGI的超人类水平,这两者并不矛盾。
1.2 S型智能曲线的叠加仍然是S型曲线
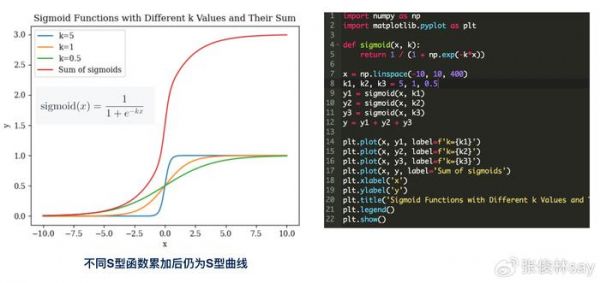
Sigmoid函数(参考左图中的公式)有个很好的性质:若我们把多个S型函数累加,形成的曲线仍然是S型曲线,不过它的取值范围区间拓宽了。参考上图,三个取不同K值(K值大小决定了Sigmoid函数快速增长区间走势的陡峭程度,K越小,越平缓,K越大,越陡峭,请记住这个知识点,后面我们会用到)的Sigmoid函数,累加后得到的曲线也是S型曲线,只是它的最大高度由1拓展到了3(每个Sigmoid函数取值范围[0,1],三个叠加就是3*[0,1]=[0,3])。
尽管最近两年大家都在谈大模型的Scaling Law,但很明显对它的理解整体还比较表面化(包括很多学术论文),不少市面上咖位比较大的大佬出来讲,你会发现他讲的观点是非常随意的,很明显没有深入思考过,有些甚至存在明显的错误(如果我们以Chinchilla Scaling Law作为标准答案来看的话)。
我一直试图思考产生这个现象背后的原因,觉得大模型Scaling Law里的关键秘密很可能就隐藏在类似上图的S型曲线叠加里(个人观点无实证,谨慎参考),对照上面的S型曲线叠加图,我这里列出两个问题,您可以费心思考一下:
问题1:您能用这个知识点解释下Pre-Training阶段的Scaling Law为何会表现出我们目前看到的现象吗?
问题2:您能用这个知识点解释下Pre-Training阶段的Scaling Law和RL Scaling Law,乃至Test time Scaling Law三者之间的关系吗?
我们下面就探讨这两个问题,不过我想很多聪明的朋友可能已经知道我想要说什么了,相信我,第二个问题可能比较容易想到,第一个其实是不太容易的。
二.从S型曲线推导Scaling Law的未来
2.1 三种Scaling Law
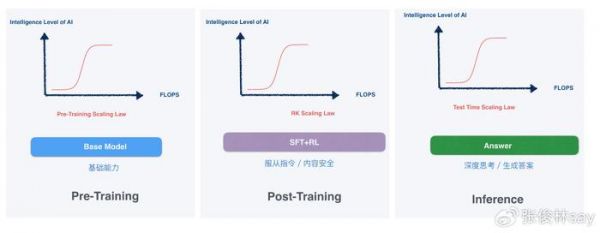
我们知道,大模型主要有三个阶段:预训练、后训练和在线推理(inference)。在24年9月前,大模型领域只有一个Scaling Law,就是预训练阶段的Scaling Law,之前炒的比较热的“Scaling Law撞墙说”,指的是这个阶段。OpenAI o1推出后,另外两个阶段不再孤单,也各自拥有了姓名,产生了各自的Scaling Law,对应后训练阶段的强化学习Scaling Law(RL Scaling Law)和在线推理阶段的Inference Scaling Law(也叫Test Time Scaling Law)。
三个阶段Scaling Law核心思想是一样的:就是说在本阶段,如果增加算力,则大模型效果会持续提升。当然上图中每个阶段的Scaling Law之所以呈现S曲线,这是我画的,我的假设如本文开头所说,不存在无限增长的曲线,所以Scaling Law曲线也呈现出S型曲线的形态。这一点估计很多人不同意,认为Scaling Law会持续指数增长? 这个算非共识,我们暂且按下不表。
是为目前现状。
2.2 用S型增长曲线解释Pre-Train 阶段的Scaling Law
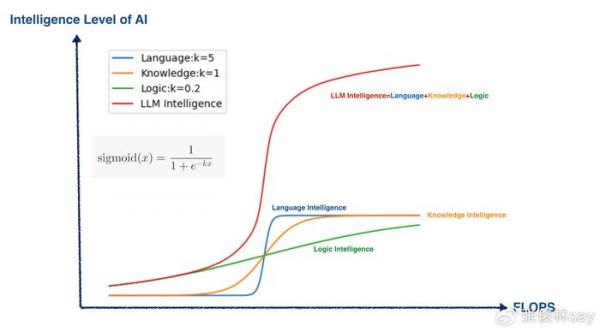
我觉得用S型增长曲线叠加,大致可以解释我们当前看到的预训练阶段Scaling Law产生的各种现象。我个人习惯把大模型的智能粗分为三大类:语言智能、世界知识智能和逻辑推理智能。在预训练阶段,大模型学习这三类智能的难易程度为:语言智能最容易学习,也学得最好;其次是世界知识,最难的是逻辑推理智能,在基座模型角度,这方面的总体能力是比较弱的(上述现象,有大量实证证据,可视为事实)。
如何用S型曲线叠加,来解释大模型预训练阶段Scaling Law出现的这种现象呢?参考上图,我觉得,可以认为语言、世界知识和逻辑推理,作为基本能力,各自都有对应的一个Sigmoid函数,随着算力的增加(增加模型大小和数据量),这方面的能力持续增加,且三个基本能力的Sigmoid函数各自对应不同的K值,K值越小走势越平缓,意味着学习难度越大,因为走势平缓代表增加很多算力或数据只获得了少量的能力提升。很明显,语言能力对应的K值最大,最容易学习,其次是世界知识,K值最小的是逻辑推理能力。
而大模型的总体智能水平Scaling Law曲线,是三个S型曲线的叠加,前面我们提过,叠加后的曲线仍是S型的,这对应Scaling Law测试到的Next Token Prediction对应Loss曲线(Loss是越小越好,上面作为智能衡量是反过来的,所以越大越好)。
那新问题来了:为啥语言能力最容易被大模型学到,而逻辑推理能力最难被学到呢?我个人经过思考,得出的可能原因或猜想是这样的:
“能力密度”猜想:决定某项能力Sigmoid函数对应K值大小的主要因素,取决于训练数据中包含体现此种能力的数据在总体数据的占比情况,可称之为“能力密度”,即:
A项能力的能力密度=训练数据中体现A项能力的数据总量/训练数据总量
比如对于语言能力来说,任意一份文本,都包含大量语言要素在内(词法、句法、语义等),所以训练数据中包含体现语言能力的“能力密度”最高,于是对应Sigmoid函数的K值就越大,能力上升曲线就越陡峭,意味着使用少量算力或数据对大模型的语言能力就有明显提升,但是随着数据增加,相关智能曲线也很容易见顶走平。反过来,能体现逻辑推理能力的数据一般包括:代码、数学、科学题目等,很明显,这种数据在数据的自然分布中占比天然就很小,所以逻辑推理能力对应Sigmoid函数K值就很小,导致学习难度很高,即使大量增加总体数据,效果提升也不明显。
如果归纳下最近两年先进大模型的进展,除了不断增加模型大小和数据总量外,从数据层面,我认为大模型快速提升智能最关键的方法有两条:
关键方法一:大量增加代码、数学等能提升逻辑推理能力的数据在总数据量中的占比。这种数据因为天然数据量少,所以可看成一种更珍贵的数据资源。
关键方法二:越是珍贵的数据资源,越要把大比例这类数据放在预训练的最后阶段,比如目前常见的所谓预训练最靠后的“退火”阶段,其实就是把大比例逻辑推理类数据放在最后一个阶段,去调整模型参数。
至于其它具体技术手段重要吗?比如是MOE还是Dense?或者其它技术,我个人认为不是太重要,很多最近两年提出真正有效的技术,大部分都对降低大模型训练和在线推理的成本有巨大帮助,但对于提升模型智能,可能帮助不大,真正帮助大的有可能是上面两个数据因素。
我举个例子,比如Deepseek V3提出的Multi-Token Prediction,这是个纯算法改进,V3论文也给出了实验数据,证明对大模型效果有正面作用,看着貌似是通过算法优化带来模型质量的提升是吧?但是,如果你仔细分析过实验数据,结论大概是这样的(我自己分析推断的,不保真):随着模型规模变大,Multi-Token Prediction带来的收益是递减的,如果规模到了V3最后版本的671B大小,大概它的收益就没有了。它的真正作用是什么呢?如果在线推理的时候,把它和“投机解码”联合起来,在线推理速度能提升大约1.83倍,也就是说,其实Multi-Token Prediction的主要作用是用来提升在线推理速度的,但是如果你只看论文,不仔细分析的话,很容易把它误读为用它是来提升大模型智能的。
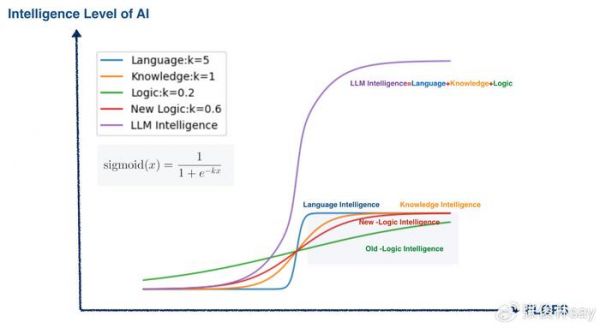
跑题了,说回来。从S型曲线叠加的角度,如何解释上述两个关键做法起到的作用呢?先看关键做法一,增加代码、数学题目等的数据占比,等价于什么?等价于增加逻辑能力的能力密度,也就是加大对应Sigmoid函数的K数值,这等于改变了逻辑推理能力Sigmoid函数走势的陡峭程度(参考上图New Logic曲线)。也就是说,在相同算力条件下,通过这种方法可以快速提升大模型的逻辑推理能力,导致大模型总体智能快速增加。(有人问了:你增加逻辑题目占比,那么语言和世界知识数据就会降低占比,这两方面能力不就降低了吗?我觉得,如果做公平对比实验的话,大概会看到这种现象。但是逻辑推理能力对于提升大模型智能更为重要,所以这种损失是合算的)。
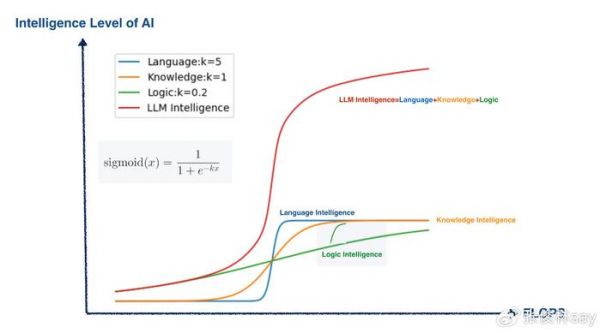
再看关键方法二,之所以把相当比例的珍贵数据(逻辑推理类)放在训练靠后的阶段能快速提升大模型智能,其实也跟增加逻辑推理的“能力密度”有关系。这等价于在训练靠后的阶段,临时把逻辑推理能力对应Sigmoid函数的K数值调得非常大,参考上图绿色曲线阴影部分曲线的突然增长(退火阶段,大部分都是逻辑推理类数据,等于在这个训练时间范围内,逻辑推理类数据占比急剧增大,能力密度剧烈提升,对应Sigmoid 函数的K值大幅提升)。
2.3三阶段Scaling Law智能叠加
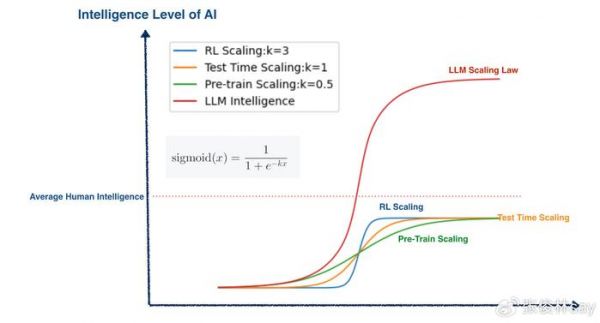
如何用S型智能增长曲线叠加原理,来解释目前阶段大模型的Scaling Law呢?这个貌似比较直观(参考上图),我们原先只有预训练阶段的Scaling Law,普遍认为已经走缓(绿色曲线,对应Sigmoid的K数值相对应该较低);而O1/R1类模型开启了RL和Test Time阶段的新型Scaling Law。很明显,这两个阶段Scaling Law对应Sigmoid函数K数值应该比较大,因为只需增加较少的算力,大模型的智力水平就得到了剧烈的增长,说明它们对应的走势是比较陡峭的(我觉得RL阶段比Test Time阶段应更陡峭些)。
严格意义上,RL和Test Time Scaling law并不应和预训练阶段Scaling Law等效,它们增强的主要是逻辑推理能力,所以RL Scaling Law其实是在原先预训练阶段Scaling Law组成成分之一的逻辑推理能力S型曲线后面,再接上了一个新的S型曲线,然后再接上Test Time阶段逻辑推理能力的新S型曲线,类似一个接力赛。
不论怎样,如果我们把三个S型曲线叠加,就得到了智力更高的大模型,以及它对应的Scaling Law,也呈现出S曲线形态。
我个人比较相信的一点是:无论是RL还是Test Time,它们的Scaling Law曲线也应是S型的,就是说总会到顶,或者说早晚要撞墙。也许现阶段最值得讨论的问题是:它们两个何时或者什么条件下会撞墙?如果撞墙了,有没有新的Scaling Law能顶替上来?如果有,那么就可以往图上新增一个S型曲线,这会进一步提升大模型的整体智能(大模型摩尔定律?:通过技术创新,不断产生新的S型Scaling Law子曲线,叠加到现有曲线中,以此来制造出大模型效果整体仍在指数上升通道假象的S型曲线。)而且,最关键的问题可能是:如果有,那么,这个新的Scaling Law会是什么?这可能是当前阶段最有价值的一个问题。
发布于:北京
相关推荐
Scaling Law陷入困局,强化学习才是全村的希望?
AI规模定律:为什么Scaling Law如此重要?
李飞飞团队50美元训练出DeepSeek R1?
最新!DeepSeek研究员在线爆料:R1训练仅用两到三周,春节期间观察到R1 zero强大进化
Scaling Law失效,AI泡沫的底层逻辑崩了?
DeepSeek没能让算力焦虑消失,硅谷四巨头全在加钱买算力
图灵奖得主专访:我不想把大模型未来押注在Scaling Law上
一天适配!天数智芯联合Gitee AI正式上线DeepSeek R1模型服务
DeepSeek R1之后,提示词技巧还有用吗?
微软CEO纳德拉:DeepSeek有“真创新”,AI成本下降是趋势
网址: S型智能增长曲线:从Deepseek R1看Scaling Law的未来 http://www.xishuta.com/newsview132525.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95124
- 2人类唯一的出路:变成人工智能 20535
- 3报告:抖音海外版下载量突破1 20375
- 4移动办公如何高效?谷歌研究了 19720
- 5人类唯一的出路: 变成人工智 19648
- 62023年起,银行存取款迎来 10272
- 7网传比亚迪一员工泄露华为机密 8400
- 8五一来了,大数据杀熟又想来, 8039
- 9滴滴出行被投诉价格操纵,网约 7662
- 10顶风作案?金山WPS被指套娃 7184



