沈抖与谭待之争,撕开了云厂商的焦虑
2月13日,两个老百度人隔空展开了一场“互怼”。
两个主人公分别是,现任百度智能云事业群总裁沈抖和火山引擎总裁谭待。公开资料显示,2008年至2019年期间,谭待曾担任百度搜索、网盘和基础架构首席架构师、T11级别技术专家。
这场争论源于,沈抖在2月12日百度智能云事业群(ACG)全员会上,颇具指向性的发言。沈抖在会上提到:“国内大模型去年‘恶意’的价格战,导致行业整体的创收相较于国外差了多个数量级”。
火山引擎、阿里云、腾讯云等,去年参与到“大模价格战”中的厂商纷纷躺枪。但接下来沈抖话锋一转,单独把豆包拎出来作为了典型案例。在谈及Deepseek影响时,沈抖直言不讳,认为首当其冲的AI产品就是字节的豆包,理由是其训练成本和投流成本都很高。
随即,谭待在朋友圈展开了正面回击。针对“恶意”一词他回应称,“豆包1.5Pro模型的预训练成本、推理成本均低于DeepSeek V3,更是远低于国内其他模型,在当前的价格下有非常不错的毛利”。
之所以能够实现降价,谭待将其归功于了“技术进步”,他表示,“国内外的厂商都在依靠技术创新,降低模型价格。我们也只是实现了Gemini 2.0 Flash的价格水平而已,这个价格完全是依赖技术进步做到。”
最后,谭待也不忘给老东家送上了自己的“建议”:“大家应该像DeepSeek一样聚焦基本功,聚焦创新,不急不躁,少无端猜测,归因外部。”
截至发稿前,沈抖未对谭待的上述言论,发表任何意见。
一、争论分歧
此次争论的话题主要集中在三个方向:大模型降价、商业化和DeepSeek。
话里话外,沈抖指责火山引擎带偏了整个行业风气,让大模型卷进了价格战,让AI产品陷入了投流营销战,以此走向了恶性循环。而谭待对其进行了全盘否认,认为降价是火山引擎的技术优势,将锅又甩回给百度,暗讽其大模型技术不到家才找理由。
实际上,去年的大模型价格战,国内几乎所有云厂商都有参与,这里面当然也包括百度,因此很难把责任归咎于哪一方。
故事最开始是DeepSeek最先打响了第一枪,火山引擎发起进攻,将大模型的价格打到了“厘时代”。随后,大规模的降价在行业中爆发,百度更是祭出必杀技,宣布文心大模型两大主力模型ERNIE Speed、ERNIE Lite全面免费。
DeepSeek大火后,市场部署DeepSeek-R1的需求也随之爆发,但由于DeepSeek官方服务器不稳定和算力资源有限,无法承接从天而降的流量。于是,机会来到了云厂商这边,新一轮的价格战再次打响。
为了抢占了流量和拉新,大厂纷纷宣布接入满血版的DeepSeek-R1,免费送token的同时,API调用价格还低于DeepSeek官方。
火山引擎向用户赠送50万token免费额度,DeepSeek-R1 满血版半折优惠,每100万token输入2元钱,100万token输出8元;百度智能云千帆大模型平台正式上线了DeepSeek-R1与DeepSeek-V3模型,低至DeepSeek官方刊例价3-5折,还可享受限时免费服务。
大模型价格战虽然有宣传的意味,但也是技术发展到一定阶段的产物,只不过在一个时间节点集中爆发。其中,沈抖提到国内大模型行业创收问题,“不及国外同行量级”是一个客观的事实,但是不能一概而论,把所有问题都归结到大模型价格上。
DeepSeek-R1虽然是中国大模型发展的一个拐点,但不能忽略的事实是,截至目前,国内大模型也只是追平到了去年国外水平,刚达到支持场景和应用落地的水平。从根本上看,正是客观的模型能力差距才导致了与国外大模型收入差距。在模型能力没有一骑绝尘的情况下,国内大模型本来就不是一门好生意,属于赔钱赚吆喝,最后还是要把流量转化到云服务赚钱。
从这个程度上看,百度云和火山引擎面临着相同的处境,互相指责其实对于行业没有任何益处。
如果要说“恶意”,大概体现在豆包排外性的投流上。豆包背靠字节天然获得了曝光的优势,但让“其他AI应用再也投不进去”,无形中抑制了其他创业公司的生长。
二、开源、普惠势不可挡
大模型卷“低价”一定是消极的吗?答案是否定的。开源、普惠、技术平权将是未来的大趋势。
DeepSeek这条“鲶鱼”已经对以OpenAI为首的闭源大模型体系发起了冲击,凭借一己之力扭转了行业对开源的认知。
“大模型开源没有意义”与“闭源大模型会持续领先”,此类声音逐渐被淹没在了各类玩家的行动之中。
2月6日,OpenAI宣布向所有用户开放ChatGPT搜索功能,无需注册。2月13日,OpenAI首席执行官Sam Altman发布消息称,GPT-4.5、GPT-5即将陆续发布,免费版ChatGPT将在标准智能设置下无限制使用GPT-5进行对话。此外,他还特别指出,OpenAI的新路线是:跨越o3、免费访问、开源“模型规范”。
国内百度也及时更新了方向,进一步拥抱免费和开源。文心一言将于4月1日起,全面免费,所有PC端和APP端用户均可体验文心系列最新模型。文心一言上线深度搜索功能,该功能也将于4月1日起免费开放使用。
2月14日,百度又官宣新消息,将在未来几个月内陆续推出文心大模型4.5系列,并于6月30日起正式开源。
从技术发展曲线来看,大模型推理和AI成本还将持续下降。以GPT为例,2023年GPT-4的token成本为36美元/百万token,到了2024年中期GPT-4o成本下降为了4美元/百万token,在此期间每个token价格下降了约150倍,摩尔定律以每18个月性能翻倍的速度改变了世界。
有人将使用特定水平AI成本每12个月下降十倍称之为“奥特曼定律”。Sam Altman认为,正是因为技术曲线发展到了一个新的节点,所以各方竞争之下大模型效率正在加速提升,这可能也是AI大模型性价比大战火热的原因。
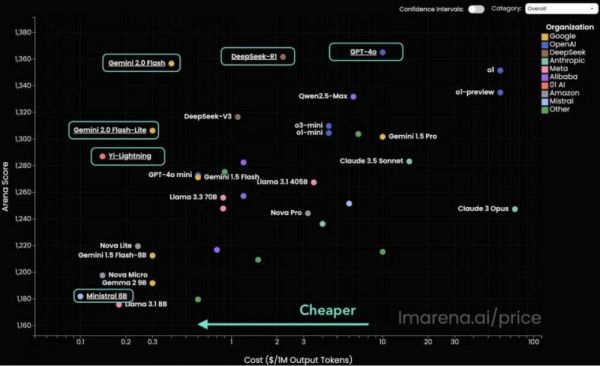
这种竞争还在持续,就在DeepSeek搅动行业不久,其价格优势就很快被谷歌Gemini-2.0-Flash/Lite所超越。
这对整个行业发展来说释放了积极的信号,意味着可以用较低的成本和较高的效率来搭建业务、应用,这将为Agent的爆发打下良好的基础。
三、“DeepSeek”效应
对大厂而言,防御比创新更重要。王小川此前说过一句话:“大创新靠小厂,小创新靠大厂”。
难得的是此次DeepSeek引发了集体的反思。
据智能涌现报道,有关DeepSeek对百度的影响,沈抖回应员工,每当科技的发展走到瓶颈期,总会有一个引领性的组织制造出拐点,而DeepSeek就是这个拐点。他认为,在DeepSeek引发这一波虹吸效应之后,开发生态会进一步繁荣。
面对DeepSeek的突然崛起,除了百度一改闭源的坚持,也在激荡其他厂商。
据晚点报道,2025年字节的全员会上,字节CEO梁汝波重提 “务实的浪漫”。反思在DeepSeek R1创新点之一的长链思考模式不是业界首创,在9月OpenAI发布长链思考模式后,字节在意识到技术重大变化时,没有及时跟进,反而错失了时机。
短期来看,DeepSeek爆火所产生的流量,受益者还是云大厂。得益于稳定的基础设施,在阿里云、百度云、火山引擎等运行的DeepSeek性能还是要略胜一筹。随着带来的是token量的消耗和新用户的增长。
但回归到商业化的问题,云厂商刷足了存在感,凭借降价、免费的政策能够转化的收入却少之又少。MaaS模式不存在网络外部效应,反之,用户涌进量越大,机器、服务和人力投入的成本消耗就越大。
更为关键的问题是,更强性能的模型诞生已经不算什么新鲜事儿,继续沿着模型探索把推理能力与业务场景结合才是下一步的方向。
有知情人士告诉光子星球,春节期间来咨询和测试DeepSeek-R1的人不在少数,但其客户还在谨慎观望状态。毕竟“狼来了”的故事,他们已经听过很多回,手里各个厂商的token已经攒了一大堆,还是没能解决实际问题。
此外,DeepSeek也正在伸向云厂商大模型2B业务。
有媒体不完全统计,至少有160多家企业集体接入了DeepSeek,这个数字还在每天不断上升。另外,不少央国企已经开始发布采购订单,点名要本地部署DeepSeek-R1,采购所适配模型的硬件和算力。
“给我来一套DeepSeek”,这是最近To B销售最常听到的一句话。
相关推荐
沈抖发布百度智能云新战略,回答了“木星”与“蜻蜓”的问题
百度智能云,沈抖拿到第二个KPI
百度搜索大批前高管加盟字节跳动,包括吴海锋、孙雯玉、谭待等
抖音与搜狐达成合作,长短之争有了新解法?
百度沈抖的新战场
一朵云长出了70%的大模型?
沈抖当如余承东
沈抖,百度“太子”还是“弃子”?
沈抖新任命透露百度重“抖擞”?
百度云重“抖”擞
网址: 沈抖与谭待之争,撕开了云厂商的焦虑 http://www.xishuta.com/newsview132666.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95137
- 2人类唯一的出路:变成人工智能 20625
- 3报告:抖音海外版下载量突破1 20477
- 4移动办公如何高效?谷歌研究了 19807
- 5人类唯一的出路: 变成人工智 19760
- 62023年起,银行存取款迎来 10280
- 7网传比亚迪一员工泄露华为机密 8413
- 8五一来了,大数据杀熟又想来, 8121
- 9滴滴出行被投诉价格操纵,网约 7740
- 10顶风作案?金山WPS被指套娃 7188



