马斯克花了20万块GPU炼出的Grok-3,水平到底怎么样?
昨天中午,马斯克终于发布了预热已久的Grok-3,不出所料,国内的很多自媒体又高潮了,今天刷到的短视频平台上介绍Grok-3的博主,表情夸张,各种吹嘘,还说之前的大模型已经是石器时代的产物了,符合国内互联网的一贯的造神风格。
言归正传,这篇文章我们来客观地分析一下Grok-3,厉害的方面我们要承认,正视我们跟老美之间的差距,但Grok-3不足的地方,我们也要说明,毕竟它还不是真正的AGI。那Grok-3的水平到底怎么样?
由于Grok-3还没有全面开放,网上真正用过的也不是很多,所以我们把网上实测过的结果都展示给大家。
官方给的测评结果
下面四张图是马斯克在X平台晒出来的,是不是感觉Grok-3遥遥领先?
但如果仔细看里面的数据,就会发现一点点端倪,那就是其实领先并不大,像下面第一张图,Grok-3是1400,而第二名的gemini-2.0是1380,性能只提升了1.4%,20万张卡只换来这一点点的提升?有同学说相比Grok-2的提升幅度很大,但Grok-2的表现简直没法看,太拉胯了。
后面三种图的提升幅度如果看百分比的话会大一点,但相对成本而言,这个幅度的提升就太小了。笔者认为这也再次验证了DeepSeek确实非常适合我们当前的国情,出现得非常及时。我们没有老美那帮企业那么多的高端显卡进行训练,只能是把工程的效率提升,降低成本。
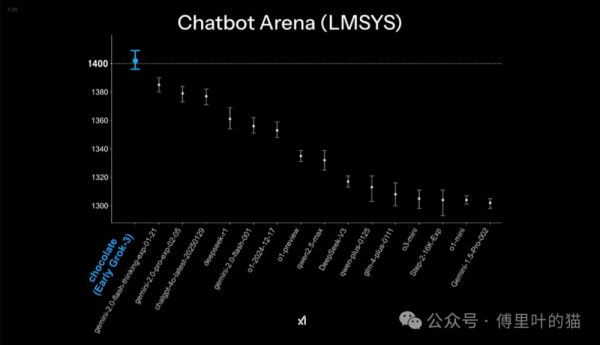
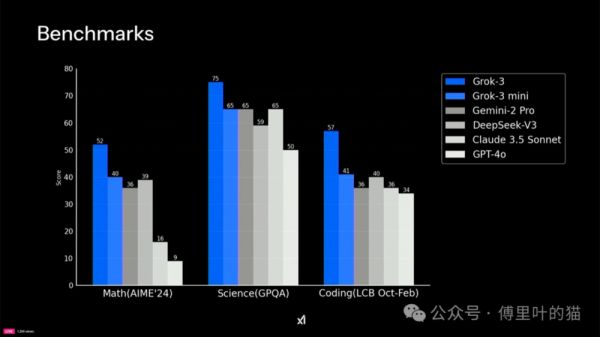
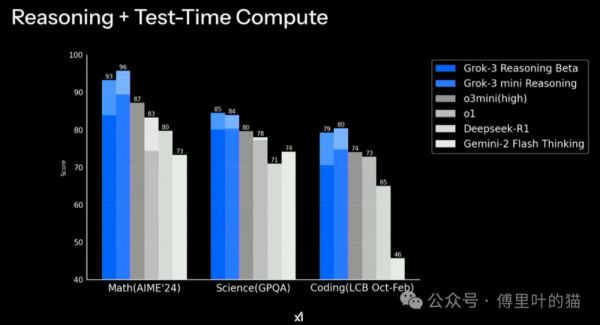
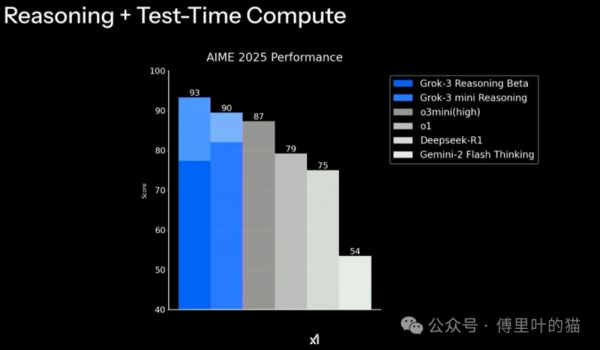
而且我们并不能完全相信官方给出的测评数据,去年国内某个AI大模型公司,官方测评成绩很高,但实测很垃圾,典型的高分低能,后来被发现是针对那几个测评专门做了优化。我说这个并不是怀疑Grok-3作弊,而是我们不能单凭这四张图就认为这就是马斯克口中的地表最强AI。
大佬的看法
首先就是Andrej Karpathy的测评,也是被国内自媒体转发最多的一个,
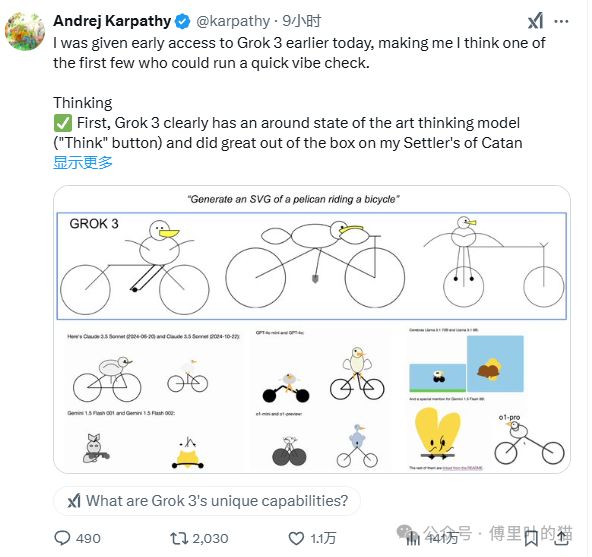
Andrej 发表的内容比较长,我们就只把Summary贴出来:

就昨天上午约两小时的快速初步评估而言,Grok 3 + 深度思考(Thinking)的表现大致处于 OpenAI 最强模型(o1 - pro,每月 200 美元)的前沿水平,且略优于 DeepSeek - R1 和 Gemini 2.0 快速思考(Flash Thinking)。
考虑到该团队大约在一年前才从零起步,能在如此短的时间内达到前沿水平,这相当令人惊叹,这样的发展速度前所未见。同时也要留意一些注意事项 —— 模型具有随机性,每次给出的答案可能略有不同,而且目前时间还很早,所以在接下来的几天或几周内,我们还需等待更多评估结果。
早期在大语言模型竞技平台(LM arena)上的结果确实看起来相当鼓舞人心。目前,热烈祝贺 xAI 团队,他们显然进展迅速且势头强劲。我很期待将 Grok 3 纳入我的 “大语言模型顾问团”,并听听它未来的见解。
Andrej 给的评价其实算是比较中肯的,也就是说对其他几个领先的大模型而言,并没有明显的优势,但也承认Grok-3现在也已经是一线大模型的水平。
至于其他的大佬,除了尬吹的,就是像Alexandr Wang这种想跟Grok继续合作的,都没有实际测评给出比较客观的评价。
网友们的测评
编写代码的能力
在发布会现场,让Grok-3写了俄罗斯方块的游戏,Grok-3生成的俄罗斯方块和宝石迷阵两个游戏的混合体成功运行,虽然界面挺美观,但实际结果就是游戏逻辑有些问题。但我觉得这也是可以接受的,一下子写出来这么复杂的代码,还是有些难度,如果后面再持续跟Grok-3反馈,我相信这个游戏也是能完成的。
但X上也有老哥测了后说Grok-3的代码能力不行(笔者对这个测试结果存疑,不确定这位老哥是否测的公平公正):
您目前设备暂不支持播放
笔者的看法
马斯克和他的同事进行的Grok-3的现场演示,看起来就像是许多其他演示的千篇一律的翻版:在基准测试中取得了比之前稍好一些的成绩,进行了更多训练(用于 Grok 2 的计算量的 15 倍),展示了俄罗斯方块变体的自动编码,但似乎效果不太理想,还推出了一款名为 “深度搜索”(Deep Search)的新产品,这名字听起来很像 “深度研究”(Deep Research),缺乏新意。此外,在测试计算量方面又有新成员 o1、o3、r1 等等加入。我没看到任何真正原创的东西。
当然老马自己也承认它仍处于 “测试版”。它比完整但尚未发布的 o3 版本更智能吗?目前我们不知道。
至于网上疯传的“暴击DeepSeek R1数学屠榜!疯狂复仇OpenAI”,我认为言过其实,Grok-3没有改变游戏规则的突破,没有重大飞跃,大模型的幻觉问题也依然存在。
但也要承认,OpenAI 的护城河在不断变窄,所以价格战会持续,除了英伟达,对其他各方来说,盈利仍将难以实现。单纯的预训练规模扩张显然未能实现AGI。
本文来自微信公众号:傅里叶的猫,作者:张海军
相关推荐
马斯克花了20万块GPU炼出的Grok-3,水平到底怎么样?
马斯克发布Grok3大模型 现场演示称超越DeepSeek 训练成本为20万块GPU
仅用19天,马斯克建成全球最强“超算工厂”,10万块H100 GPU上线,Grok 3预计年底发布
10万块芯片,马斯克用最大超算挑战GPT
马斯克抢购1万块GPU加入AI大战,是在打脸吗?
大厂疯抢GPU,马斯克要买100万个?
马斯克新AI 破解千年难题却被紧急喊停?这个“玩笑”怎么让AI 圈一夜未眠
马斯克发布Grok 3,推理能力超o3和DeepSeek-R1
Sora研发消耗数十万块GPU,而国内能买一万块的公司都屈指可数……
世界第一超算跑深度学习模型,2.76 万块 V100 GPU 将分布式训练扩展到极致
网址: 马斯克花了20万块GPU炼出的Grok-3,水平到底怎么样? http://www.xishuta.com/newsview132820.html
推荐科技快讯






- 1问界商标转让释放信号:赛力斯 95169
- 2人类唯一的出路:变成人工智能 20816
- 3报告:抖音海外版下载量突破1 20696
- 4移动办公如何高效?谷歌研究了 19988
- 5人类唯一的出路: 变成人工智 19959
- 62023年起,银行存取款迎来 10305
- 7网传比亚迪一员工泄露华为机密 8446
- 8五一来了,大数据杀熟又想来, 8279
- 9滴滴出行被投诉价格操纵,网约 7898
- 10顶风作案?金山WPS被指套娃 7207



