Claude 3.7 Sonnet发布:别提什么AGI,我Anthropic要赚企业客户的钱
Anthropic的最新模型在加班加点赶工后正式发布。它被称为其迄今为止最智能的模型,以及首款“混合推理模型”——Claude 3.7 Sonnet。
Anthropic对这个新模型的一句话介绍是:
一个模型,两种思考方式(One model,two ways to think)。
新的Claude增加了“标准思考”和“扩展思考模式”两种不同选项:
“这是市场上首款混合推理模型。Claude 3.7 Sonnet能够生成近乎即时的响应,也可以进行可被用户看到的扩展式、分步推理。API用户还可以对模型的思考时间进行精细控制。Claude 3.7 Sonnet在编程和前端网页开发方面表现出显著提升。与该模型一同推出的,还有用于代理编程的命令行工具——Claude Code。Claude Code目前处于有限的研究预览阶段,它能够让开发人员直接从终端将重要的工程任务委托给Claude。”
简单说,你能最直接感受的变化是,Claude多了几个选项,变得和其他有“Think”模式的ChatBot界面更像了。

刷新榜单排名,但明显有取舍
此前Claude作为对标ChatGPT的模型工具,是一个强大的语言模型产品,随着OpenAI的o系列和DeepSeek R1出现,推理能力成了Claude的短板。此次它终于补上了这个今天所有顶级模型必备的能力。
根据它的评测,在主流的几个评测集上,它领先其他模型。比如在软件能力SWE-bench Verified测试中,Claude 3.7 Sonnet大幅领先Claude 3.5 Sonnet、OpenAI的o3-mini以及DeepSeek R1。
在TAU-bench测试中也表现不错,在这个用来评估LLM在复杂真实场景中用户与工具交互能力的基准测试平台上,它同样实现了SOTA。
除了公布了一系列传统基准测试成绩,有意思的是Claude 3.7 Sonnet还表示,它可以在宝可梦游戏测试中超越其他模型。
“Claude的扩展思维和代理训练使其在许多标准评估(如OSWorld)上的表现更佳。”官方写道。而“玩《精灵宝可梦》——特别是Game Boy经典游戏《精灵宝可梦红色版》——正是这样一项任务。”
简单说,就是让Cluade在超出通常的上下文限制下,去玩《精灵宝可梦》,通过数万次互动维持游戏进程。结果发现,Claude 3.0 Sonnet以前几乎没法离开故事起点的真新镇的家,而Claude 3.7 Sonnet改进的代理能力帮助它取得了更大的进展,它成功挑战了三位宝可梦道馆馆主(游戏中的boss),并赢得了他们的徽章。

“Claude 3.7 Sonnet在尝试多种策略和质疑先前假设方面非常有效,这使它能够在进展过程中提升自身能力。”
Claude 3.7 Sonnet目前可以通过所有Claude产品服务以及Anthropic API、Amazon Bedrock和谷歌云Vertex AI使用。但免费用户目前还是无法体验扩展思考模式。
不过,仔细看它公布的数据排名,会发现一个有意思的现象。
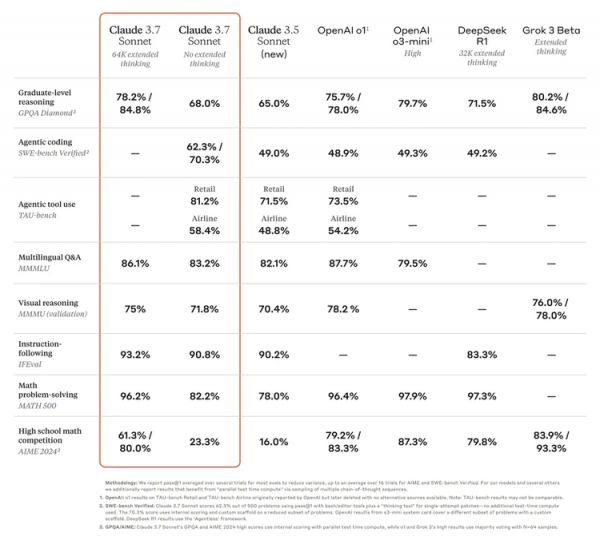
Claude 3.7 Sonnet的深度思考其实更适用于强逻辑推理和数学任务,在数据对比上,对于推理、数学竞赛等任务,它并没有把自己“刷到第一”,反而DeepSeek R1和Grok 3的模型成绩依然得分更高。
甚至在数学上,Claude 3.7 Sonnet给自己测出的成绩也不如开源的DeepSeek R1。但在尤其是Agentic coding的测评上,它遥遥领先其他模型。
显然Anthropic不只是对测评,也对Claude 3.7 Sonnet的能力建设有所取舍。
所谓“混合推理”,更像是“企业场景定制化”
此前的推理模型,往往是指一个基于某个基础语言模型,用全新的方法训练出来的行为方式完全不同的模型,比如OpenAI的o系列,和DeepSeek的R1。而Anthropic一直没有选择这个路线,而是认为基础模型和推理模型的方法都应该属于一整套模型训练方法里的不同环节。在o系列发布后,Anthropic官方也没有针锋相对的跟进,但在DeepSeek的开源冲击下,Claude团队开始加班加点压力增加,在其创始人Dario Amodei预告了多次后,Claude 3.7 Sonnet终于发布。
但在这次的官方文档中并没有对这个模型所谓的“混合”方法多做介绍,而更多是体现在功能设计上。新的Claude增加了“标准思考”和“扩展思考模式”两种不同选项,使用API的用户则可以进一步对模型的思考时间进行更详细的控制,甚至具体到token的用量上。
根据Anthropic的说法,“Claude 3.7 Sonnet既是普通的LLM,又是推理模型”。用户可以选择让它正常回答,也可以让它在回答之前思考更长时间,也就是所谓的推理。
而API用户使用Claude 3.7 Sonnet时,可以控制“思考预算”(the budget for thinking)。用户可以要求模型的思考限制在N个token以内,N不超过128K。
所以,看起来从产品层面,它的混合推理指的就是对token的控制,目前并没有介绍更多在模型上混合的方法和带来的能力的不同。
做个企业喜欢的推理模型
这种思路也直接体现在了对模型的具体场景的优化上。
据Anthropic介绍,在开发这款推理模型时,他们的优化重点并不像其他顶级推理模型那样,重点放在对数学和编程竞赛等数据的优化上。哪怕是在这款他们的首个混合推理模型上,Anthropic就已经将重点放在了“更能反映企业实际使用大模型的方式的现实任务”上了。
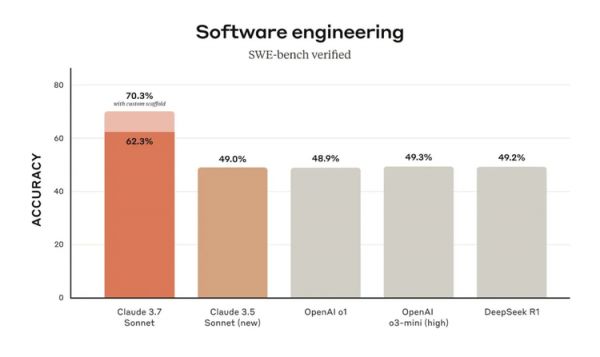
所以在公布的评测指标上,Claude 3.7 Sonnet其实在推理表现的某些指标上,依然不及o3和Grok的模型。
而Anthropic特意强调的则是用来体现模型解决GitHub上真实软件问题能力的SWE-bench Verified上的表现,它超过了DeepSeek R1,和OpenAI的o3-mini。
因此此次推出Claude 3.7 Sonnet的同时,Anthropic更新了智能编码工具Claude Code。在Claude.ai上的编码体验也得到更新,比如把GitHub集成提供给所有Claude付费用户,他们可以把代码存储库直接连接到Claude。Claude code的目标也是让开发人员把大量工程任务委托给Claude。据其评估,它能一次完成需45分钟以上的人工编程任务,在测试驱动开发、大规模调试和重构代码的任务上有大幅度提升。
另一个值得注意的地方是,除了让Claude 3.7 Sonnet的价格与其前代3.5保持一致外,(每百万输入token 3美元,每百万输出token 15美元),Anthropic还强调了在标准模式和思考模式里,“模型的提示词工作方式类似”——这也是一个针对企业级市场的重要的能力,企业用户们需要一个稳定的使用环境,过往模型的迭代对提示词的影响很大,不利于企业的部署。
看来,现在Anthropic想的很清楚了——在追求AGI的路上,模型已经没有壁垒了,在找到技术竞争的新模式之前,必须先要抢实打实的市场,活下去,从Cursor这样的工具开始,先把对手熬走,才能有机会赢下这场竞赛。
本文来自微信公众号:硅星人Pro (ID:gh_c0bb185caa8d),作者:王兆洋
相关推荐
Claude 3.7 Sonnet发布:别提什么AGI,我Anthropic要赚企业客户的钱
Anthropic的Claude 3,解决了困扰OpenAI的难题
Anthropic放大招:AI能像人一样操作电脑,你旁边看着就行
OpenAI最强竞对Claude再次出牌
新火种AI|秒杀GPT-4,狙杀GPT-5,横空出世的Claude 3振奋人心!
反转,Claude 3.5超大杯没有训练失败
他们让GPT-4看起来像个流氓
OpenAI最强竞品大更新,一句话模拟人类用电脑
刚刚曝光的 Claude3,直击 OpenAI 最大弱点
Claude新指南,教你构建属于自己的智能体
网址: Claude 3.7 Sonnet发布:别提什么AGI,我Anthropic要赚企业客户的钱 http://www.xishuta.com/newsview133087.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95189
- 2人类唯一的出路:变成人工智能 20955
- 3报告:抖音海外版下载量突破1 20863
- 4移动办公如何高效?谷歌研究了 20120
- 5人类唯一的出路: 变成人工智 20111
- 62023年起,银行存取款迎来 10313
- 7网传比亚迪一员工泄露华为机密 8466
- 8五一来了,大数据杀熟又想来, 8395
- 9滴滴出行被投诉价格操纵,网约 8017
- 10顶风作案?金山WPS被指套娃 7219



