榨干每一块GPU,DeepSeek开源第二天,送上降本增效神器
本文来自微信公众号:APPSO (ID:appsolution),作者:appso,题图来自:unsplash
DeepSeek开源周来到第二天,继续为AI大模型的基础建设添砖加瓦——真正的open AI,毋庸置疑。
今天DeepSeek带来了DeepEP,一个专为混合专家系统(MoE)和专家并行(EP)定制的通信库。
它的设计灵感来自DeepSeek-V3论文里的群组限制门控算法(group-limited gating),这个算法能帮助大模型更高效地分配任务给不同的“专家”,降本增效从未如此简单。

DeepEP的亮点颇多:
高效优化的全员协作通道
专为训练和推理预填充设计的高吞吐核心
专为推理解码设计的低延迟核心
原生支持FP8智能压缩传输
灵活调控GPU资源,实现边计算边传输
DeepEP在Mixture-of-Experts(MoE)模型的通信技术上有所突破,特别是在GPU内核优化方面。它显著提升MoE模型的性能和效率,适用于大规模AI训练和推理。
计算资源分配能力再上一层楼
随着AI模型规模的不断扩大,从数十亿参数到数万亿参数,高效的通信将成为关键瓶颈。DeepSeek这次带来的DeepEP,主打低延迟内核,其支持FP8的特性特别适合资源受限或实时性要求高的场景。
特别是在处理MoE分派和组合的通信模式上,DeepEP针对高吞吐量和低延迟的GPU内核,专门优化了MoE模型中数据路由和输出的整合过程。
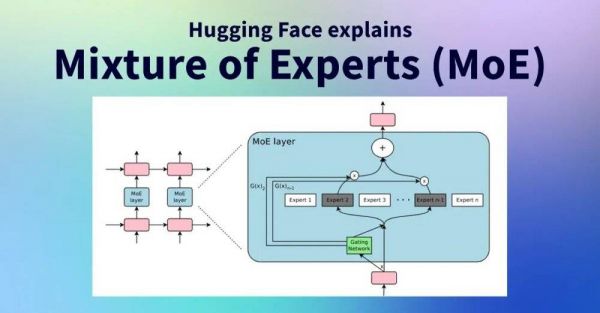
优化之后的MoE模型的通信性能,支持低精度操作(如FP8),并提供了针对非对称域带宽转发的内核。这使得在分布式GPU环境中,MoE模型的训练和推理更加高效和可扩展,尤其是在多节点集群中,能够显著降低通信开销并提高整体性能。

MoE“混合专家”,就是让AI模型里汇聚了不同的专家,负责不同的任务。更形象点说,一个超大型AI模型就像班级大扫除时的值日团队,每个同学要干的活不同,有人擦玻璃,有人扫地,有人搬桌子,等等等等。
但现实中总有人动作快,有人动作慢。桌子没搬好,去帮忙拖地;玻璃先擦了,又会有灰尘落在地上。互相协调的过程不通畅,会导致效率低下。
为了解决这种协作卡顿的问题,就需要有一个高效智能的分工计划。就像班主任把值日生分成不同小组,让擦玻璃快的同学专注擦玻璃,扫地的同学专注扫地,大家各司其职不互相拖后腿,并且及时观察谁的活儿提前干完了,谁的工作量超了。
这就是“专家小组分工”group-limited gating:不让擦玻璃的同学被迫扫地,从根源上减少人力资源浪费。

而在大模型里,这就是不让计算资源浪费。DeepEP能根据任务量动态调节GPU的计算资源(SM数量控制)。任务多的时候,就让GPU里更多计算单元一起工作;任务少的时候自动减少功耗,既省电又不耽误效率,特别适合需要快速处理海量数据的场景。
“降本增效”,是这次DeepEP送出的一份大礼。
高速通道+无缝换乘,数据秒达
除了资源分配,AI模型里的“专家”,也就是计算机里的GPU芯片,需要频繁传递数据。数据传递慢会导致GPU算完一波任务后“干瞪眼”。
DeepEP的跨域带宽优化,相当于给GPU配了专属直升机送货,把等待时间进一步压缩,自然能榨出更多算力。
还是回到刚才班级大扫除的例子,普通的GPU之间传输数据慢、互相等,就好像擦玻璃的同学需要水桶,但桶在扫地的同学手里,只能等对方用完再传,中间浪费时间。甚至要去隔壁班借,得穿过走廊、爬楼梯,还可能被其他班级的人堵住。
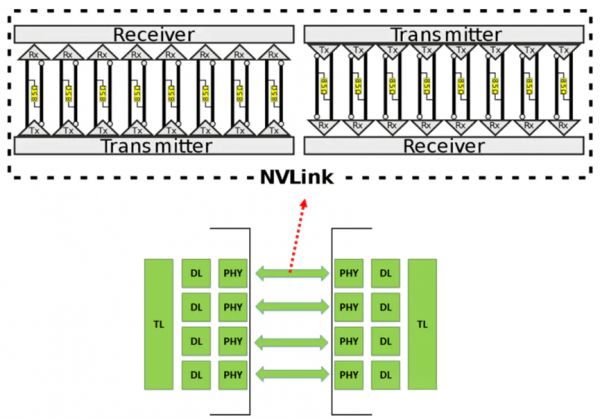
在数据传输上,也会出现类似的问题。而DeepEP的内核,优化了非对称域带宽转发(如NVLink到RDMA),这使得它特别适合现代高性能计算(HPC)环境中的多节点分布式训练。
同一服务器内GPU用NVLink,传输速度150GB/s,几乎零等待。跨服务器用RDMA网络,速度蹭蹭加快。还有无缝带宽转发,避免数据堆积或丢失。
如果说传统的AI训练中,GPU跑了10个小时,4个小时在等数据、等同步,实际工作时间只有6小时。那么DeepEP,能够把等待时间压缩到1小时,GPU干活9小时,相当于多了3小时算力,真正“榨干”每一块GPU。
这对于很多应用场景,尤其是依赖MoE架构的大型语言模型,都有非常大的价值。DeepEP可以显著提升这些模型的训练和推理效率,适用于自然语言处理任务,如翻译、摘要生成和问答系统。
在代码生成领域也有应用,DeepEP的高效通信可以加速这些模型的开发和部署,特别是在处理复杂编程任务时。
甚至是在推荐系统中,MoE可以让不同专家处理不同用户偏好,DeepEP的优化可以提高系统在分布式环境中的性能,适用于电商平台或流媒体服务。
“降本增效”的关键大招,DeepSeek都倾囊相授了,真·open ai。
本文来自微信公众号:APPSO (ID:appsolution),作者:appso
相关推荐
DeepSeek开源周观察:让所有人都能用起来R1
DeepSeek开源周Day1:FlashMLA:大家省,才是真的省
DeepSeek登顶140国榜首,免费开源的真相究竟是什么?
关于DeepSeek,你可能还不知道的10件事
DeepSeek开源的FlashMLA有什么优势?
当我用DeepSeek来写DeepSeek
DeepSeek启示录:伟大不能被计划
DeepSeek,从追赶者到追杀者
DeepSeek的崛起,其实并不意外
“后来者”DeepSeek:掀起算法效率革命
网址: 榨干每一块GPU,DeepSeek开源第二天,送上降本增效神器 http://www.xishuta.com/newsview133099.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95189
- 2人类唯一的出路:变成人工智能 20955
- 3报告:抖音海外版下载量突破1 20863
- 4移动办公如何高效?谷歌研究了 20120
- 5人类唯一的出路: 变成人工智 20111
- 62023年起,银行存取款迎来 10313
- 7网传比亚迪一员工泄露华为机密 8466
- 8五一来了,大数据杀熟又想来, 8395
- 9滴滴出行被投诉价格操纵,网约 8017
- 10顶风作案?金山WPS被指套娃 7219



