DeepSeek连开三源,解开训练省钱之谜
“DeepSeek有效地驳斥了频繁出现的在训练方面‘他们撒谎了’的言论。”
旧金山人工智能行业解决方案提供商 Dragonscale Industries 的首席技术官 Stephen Pimentel在X上如是评论DeepSeek“开源周”。
“是的。以及关于5万张H100的虚假传闻(也被驳斥了)……”全球咨询公司DGA Group合伙人、中美技术问题专家Paul Triolo也附和道。

DeepSeek“开源周”从2月24日至2月28日,共持续5天。会陆续开源5个项目。
过去三天的开源项目分别是:
Day1:FlashMLA,针对英伟达Hopper架构GPU的高效MLA(多头潜在注意力)解码内核;
Day2:DeepEP,首个用于MoE(混合专家)模型训练和推理的开源EP(专家并行)通信库;
Day3: DeepGEMM,支持稠密和MoE模型的FP8计算库,可为V3/R1的训练和推理提供强大支持。
刚进行到第三天,“开源周”已经让怀疑DeepSeek在训练成本上“撒谎”的人噤声了。因为每个开源项目都在向世界展示DeepSeek极致压榨英伟达芯片的功力。
还有什么比“贴脸开大”更能打败质疑的呢?
一
我们先来看看DeepSeek最新开源的DeepGEMM,只能说,在压榨英伟达芯片、AI性能效率提高这方面,DeepSeek已经出神入化。
这是当初团队专门给V3模型用的,现在就这么水灵灵地开源了,要不怎么说DeepSeek的诚意实在感人呢。
在GitHub上发布不到10个小时,就已经有2.6千个星星了。要知道一般来说,在GitHub上获得几千星星就已经算很成功了。
“DeepGEMM像是数学领域的超级英雄,快过超速计算器,强过多项式方程。我尝试使用DeepGEMM时,现在我的GPU在计算时以每秒超过1350 TFLOPS(万亿次浮点运算)的速度运转,好像已经准备好参加AI奥运会了!”一位开发者兴奋地在X上表示。
DeepSeek新开源的DeepGEMM究竟是什么、意味着什么?
DeepSeek官方介绍DeepGEMM是一个支持密集型和MoE 模型的FP8 GEMM库:
无重度依赖,像教程一样简洁;
完全JIT(即时编译);
核心逻辑约300行代码,在大多数矩阵尺寸下优于经过专家调优的内核;
同时支持密集布局和两种MoE布局。
一句话定义:DeepGEMM是一款专注于FP8高效通用矩阵乘法(GEMM)的库,主要满足普通矩阵计算以及混合专家(MoE)分组场景下的计算需求。
利用该库,能够动态优化资源分配,从而显著提升算力效率。
在深度学习中,FP8(8位浮点数)可以减少存储和计算的开销,但是缺点(特点)也有,那就是精度比较低。如果说高精度格式是无损压缩,那FP8就是有损压缩。大幅减少存储空间但需要特殊的处理方法来维持质量。而由于精度低,就可能产生量化误差,影响模型训练的稳定性。
在报告中DeepSeek介绍:“目前,DeepGEMM仅支持英伟达Hopper张量核心。为了解决FP8张量核心积累的精度问题,它采用了CUDA核心的两级积累(提升)方法。”
而DeepSeek为了让FP8这种速度快但精度偏低的计算方式变得更准确,利用了CUDA核心做了两次累加,先用FP8做大批量乘法,然后再做高精度汇总,以此防止误差累积。既大幅减少空间,同时又保有精度,效率也就由此提升。
JIT(即时编译)和Hooper张量核心也是绝配。
Hopper张量核心是专门为高效执行深度学习任务而设计的硬件单元,而JIT则意味着允许程序在运行时根据当前硬件的实际情况,动态地编译和优化代码。比如,JIT编译器可以根据具体的GPU架构、内存布局、计算资源等实时信息来生成最适合的指令集,从而充分发挥硬件性能。
最最最惊人的是,这一切,都被DeepSeek塞进了约300行代码当中。
DeepSeek自己也说:“虽然它借鉴了一些CUTLASS和CuTe的概念,但避免了对它们模板或代数的过度依赖。相反,该库设计简单,只有一个核心内核函数,代码大约有300行左右。这使得它成为一个简洁且易于学习的资源,适用于学习Hopper FP8矩阵乘法和优化技术。”
CUTLASS是英伟达自家的CUDA架构,专门给英伟达GPU来加速矩阵计算。毕竟官方出品,它的确非常好用。但它同时也很大很沉,如果手里的卡不太行,那还真不一定跑得了。
吃不上的馒头再想也没用啊,而DeepSeek的极致压榨哲学就在这里闪烁光芒了。优化更激进、更聚焦,也更轻。
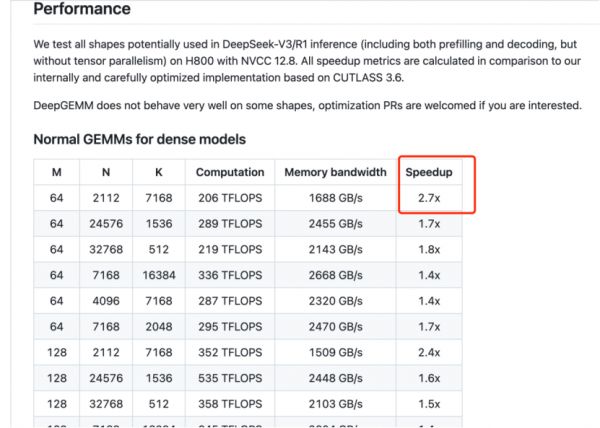
轻的同时表现也很好,在报告中,DeepSeek表示,DeepGEMM比英伟达CLUTLASS 3.6的速度提升了2.7倍。
还记得DeepSeek在春节时大火,人们使用后都在为其“科技浪漫”风触动不已。
如今看来,DeepSeek的“科技浪漫”绝不仅仅在最终呈现给用户的文字当中,DeepGEMM就像一把锋利的小刀,在英伟达芯片上雕出漂亮的小花,线条简洁又优雅。
二
不仅是DeepGEMM,DeepSeek前两个开源项目也将其“科技美学”体现得淋漓尽致。
第一天,DeepSeek开源了FlashMLA。
用DeepSeek的话说,这是“用于Hopper GPU的高效MLA解码内核,针对可变长度序列进行了优化。”
略过技术细节,我们来看看FlashMLA如何发挥作用。
首先,在大型语言模型推理时,高效的序列解码对于减少延迟和提高吞吐量至关重要。FlashMLA针对变长序列和分页KV缓存的优化,使其非常适合此类任务。
其次,像聊天机器人、翻译服务或语音助手等应用需要低延迟响应。FlashMLA的高内存带宽和计算吞吐量确保这些应用能够快速高效地返回结果。
以及,在需要同时处理多个序列的场景(如批量推理)中,FlashMLA能够高效地处理变长序列并进行内存管理,从而确保最佳性能。
最后,研究人员在进行新的AI模型或算法实验时,可以使用FlashMLA加速实验和原型开发,尤其是在处理大规模模型和数据集时。
还是两个字:压榨。在报告当中,DeepSeek表示,这个工具专门针对英伟达H800做优化——在H800 SXM5平台上,如内存受限最高可以达到3000GB/s,如计算受限可达峰值580 TFLOPS。
第二天,DeepSeek开源了DeepEP。
用DeepSeek的话说,这是“首个用于 MoE 模型训练和推理的开源 EP 通信库”。
MoE即混合专家(Mixture of Experts),这种架构利用多个“专家”子模型来处理不同的任务。和使用单一大模型处理所有任务不同,MoE根据输入选择性地激活一部分专家,从而使模型更高效。
顺带一提,MoE和前文提到的MLA(多头潜在注意力)正是DeepSeek所使用的降低成本的关键先进技术。
而DeepEP当中的EP则是指专家并行(Expert Parallelism),是MoE中的一种技术,让多个“专家”子模型并行工作。
DeepEP这个库,可以在加速和改善计算机(或GPU)之间在处理复杂机器学习任务时的通信,特别是在涉及混合专家(MoE)模型时。这些模型使用多个“专家”(专门的子模型)来处理问题的不同部分,而DeepEP确保数据在这些专家之间快速而高效地传递。
就像是机器学习系统中一个聪明的交通管理员,确保所有“专家”能够按时收到数据并协同工作,避免延迟,使系统更加高效和快速。
假设你有一个大型数据集,并且想让不同的模型(或专家)处理数据的不同部分,DeepEP会将数据在合适的时机发送给正确的专家,让他们无需等待或造成延迟。如果你在多个GPU(强大的处理器)上训练机器学习模型,你需要在这些GPU之间传递数据。DeepEP优化了数据在它们之间的传输方式,确保数据流动迅速而顺畅。
即便你不是一个开发者,对以上内容并不完全理解,也能从中读出两个字来:高效。
这正是DeepSeek开源周所展现的核心实力——这家公司究竟是怎样最大化利用有限的资源的。
三
自从DeepSeek开启开源周,就不怎么见到此前对其发出质疑的人再有什么评论了。
正如本文开头引用Pimentel的辣评:“DeepSeek有效地驳斥了频繁出现的在训练方面‘他们撒谎了’的言论。”
在去年12月关于V3的技术报告中,DeepSeek表示该模型使用了大约2000块英伟达H800进行训练,成本约为600万美元。这个成本远低于规模更大的竞争对手,后者动辄就是几十亿、上万亿美元的投入,OpenAI甚至在DeepSeek的R1模型走红前,刚刚和甲骨文、软银携手宣布了5000亿美元的合资项目。
这也引发了对DeepSeek在开发成本方面误导公众的指控。
持有怀疑态度的包括但不限于Anthropic创始人达里奥·阿莫迪(Dario Amodei)、Oculus VR的创始人帕尔默·卢基(Palmer Luckey)。Oculus已经被Meta收购。
卢基就称,DeepSeek的预算是“虚假的”,而阿莫迪干脆撰写檄文呼吁美国加强芯片出口管制,指责DeepSeek“偷偷”用了大量更先进的芯片。
这些批评声并不相信DeepSeek自己的表态——DeepSeek 在其技术报告中表示,高效训练的秘诀是多种创新的结合,从MoE混合专家架构到MLA多头潜在注意力技术。
如今,DeepSeek开源周零帧起手,就从这些技术的深度优化方面做开源。
Bindu Reddy在X上表达振奋的心情:“DeepSeek正在围绕MoE模型训练和推理开源极高效的技术。感谢DeepSeek,推动AGI的发展,造福全人类。”Reddy曾在谷歌担任产品经理、在AWS担任人工智能垂直领域总经理并,后创办Abacus AI,是开源路线的信仰者。

有媒体评论道:“对于热爱人工智能的人来说,FlashMLA就像一股清新的空气。它不仅关乎速度,还为创造力和协作开辟了新途径。”
在Github相关开源项目的交流区,不仅有技术交流,也有不少赞美之声,甚至有中文的“到此一游”打卡贴。在中文互联网上,人们已经开始把DeepSeek称为“源神”。
DeepSeek有自己的难题吗?当然有,比如商业化这个老大难问题,DeepSeek或许也得面对。但在那之前,它先将压力给到了对手。
同样是在Github的交流区,不少人想起了OpenAI,将DeepSeek称为“真正的OpenAI”。OpenAI已经走上闭源之路好几年,甚至被戏称为“CloseAI”,直到DeepSeek出现,OpenAI的CEO山姆·奥特曼(Sam Altman)才终于松口,称在开源/闭源的问题上,自己或许站在了历史错误的一边。
一周前,他曾经在X上发起投票,询问粉丝希望OpenAI的下一个开源项目是什么类型的。
不过到目前为止,这一切都还在承诺中,并未见之于世。
另一边,马斯克的xAI,仍然在新一代发布时,开源上一代大模型。刚刚发布了Grok 3,宣布会开源Grok 2。
与此同时,DeepSeek的开源周,让更多人担心起英伟达,这个在AI浪潮中最大的受益者之一。
有人看着DeepSeek的开源项目一个接一个发布,在X上表示:“这是第三天看到我的英伟达股票正在火上烤。”
北京时间2月27日,既是DeepSeek开源周的第四天,是OpenAI放出开源信号的第九天,也是英伟达财报发布的日子。
OpenAI的开源项目会来吗?英伟达的股价能稳住吗?DeepSeek还将开源什么?人工智能战场上,总是不缺少令人期待答案的问号。
本文来自微信公众号:直面AI,作者:毕安娣
相关推荐
DeepSeek连开三源,解开训练省钱之谜
几何密铺能解开生命手性之谜吗?
DeepSeek爆火OpenAI谷歌坐不住了......
DeepSeek上车,救不了掉队的车企
DeepSeek启示录:伟大不能被计划
DeepSeek大模型专家交流
微软、英伟达、阿里、百度“开抢”,DeepSeek成为主流标配
成就DeepSeek奇迹的芯片,敲响英伟达警钟
DeepSeek什么来头,何以震动全球AI圈?
DeepSeek的冲击波,撞开了AI生态之争的大门
网址: DeepSeek连开三源,解开训练省钱之谜 http://www.xishuta.com/newsview133154.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95198
- 2人类唯一的出路:变成人工智能 20989
- 3报告:抖音海外版下载量突破1 20908
- 4移动办公如何高效?谷歌研究了 20153
- 5人类唯一的出路: 变成人工智 20148
- 62023年起,银行存取款迎来 10317
- 7网传比亚迪一员工泄露华为机密 8472
- 8五一来了,大数据杀熟又想来, 8423
- 9滴滴出行被投诉价格操纵,网约 8046
- 10顶风作案?金山WPS被指套娃 7219



