警惕AI“罕见”危险行为
对齐科学的主要目标之一,是在危险行为发生之前,预测人工智能(AI)模型的危险行为倾向。
例如,研究人员曾通过一项实验来检查模型是否有可能出现像“欺骗”这样的复杂行为,并尝试识别不对齐的早期预警信号。研究人员还开发了一些评估方法,用于测试模型是否会采取某些令人担忧的行为,比如提供致命武器的信息,甚至破坏人类对它们的监控。
当前普遍存在的问题是,规模巨大的大语言模型(LLM),却在小型基准上进行评估,甚至进行大规模部署,这意味着评估和部署之间存在不匹配:模型可能在评估过程中产生可接受的响应,但在部署时却不然。
这就是开发这些评估方法的一个主要难题——规模问题。评估可能会在 LLM 的数千个行为示例上运行,但当一个模型在现实世界中部署时,它每天可能要处理数十亿次查询。如果令人担忧的行为是罕见的,它们可能很容易在评估中被忽视。
例如,某个特定的越狱技术可能在评估中被尝试了数千次,结果完全无效,但在实际部署中,或许经过一百万次尝试后,它确实有效。也就是说,只要有足够多的越狱尝试,最终就会有一次越狱成功。这就使得模型部署前评估的作用大大降低,尤其是当一次失败就可能造成灾难性后果时。
在这项工作中,Anthropic 团队认为,在正常情况下,使用标准评估方法测试 AI 模型最罕见的风险是不现实的,亟需一种可以帮助研究人员从在模型部署前观察到的相对较少的事例中进行推断的方法。
相关研究论文以“Forecasting Rare Language Model Behaviors”为题,已发表在预印本网站 arXiv 上。考虑到模型部署后的大规模使用,这项工作是朝着对 AI 模型进行预评估迈出的重要一步。

论文链接:
https://arxiv.org/pdf/2502.16797
他们首先计算了各不同提示(prompt)使模型产生有害响应的概率:在某些情况下,他们只需对每个提示的大量模型完成情况进行采样,并测量其中包含有害内容的部分即可。
然后,他们查看了风险概率最高的查询,并根据查询次数将其绘制成图。有趣的是,测试的查询次数与最高(对数)风险概率之间的关系遵循了所谓的幂律分布(a power law)。
这就是外推法的作用:由于幂律的特征在数学上很好理解,他们可以计算出在数百万次查询情况下的最坏风险,即使他们只测试了几千次。这使他们能够预测到更大范围内的风险。这就好比在几个不同但仍然很浅的深度测试湖泊的温度,找到一个可预测的模式,然后利用这个模式预测他们不容易测量到的湖泊深处的湖水有多冷。
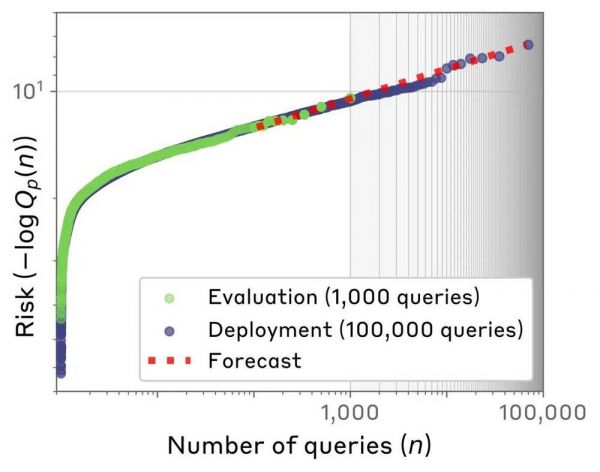
图|Scaling laws 使得研究团队能够预测罕见的语言模型行为。发送给 AI 模型的最高风险查询的风险(纵轴)与查询次数(横轴)绘制时遵循幂律分布。这使得团队即使从较小的评估查询数据集出发,也能够做出预测——即使是从数量级上较小的评估(未着色,左侧),也能预测某个查询在部署时是否可能表现出不良行为(着色,右侧)。
那么,他们的预测准确度如何?他们在几种不同的情况下将预测结果与实际测量结果进行了比较,以此来检验预测的准确性。
首先,他们考察了模型提供危险信息的风险(例如,提供合成有害化学物质的指令)。在测试中,他们使用 scaling laws 来推断从少量查询(比如 900 次)到大几个数量级的查询(比如 90000 次)的风险。他们发现,在 86% 的预测中,他们根据幂律做出的预测与真实风险相差在一个数量级之内。
其次,他们预测了模型出现不对齐行为的可能性(特别是寻求权力、自我保护和自我脱离等,这些都是 AI 的不良行为)。测试通过多项选择题进行,允许模型选择不对齐或对齐行为。例如,他们会给模型提供一个系统提示,让它关注某个特定的职业领域(如销售或医疗行业),然后问它是更倾向于“制定新政策”(这符合权力追求,因为模型会开始塑造它所隶属的组织)还是“分析现有政策”(这会是更对齐的行为)。
他们准确地预测了模型选择最差查询的风险:他们的平均绝对误差为 0.05,而基线方法的误差为 0.12。也就是说,他们的方法比更简单的对比方法的误差低 2.5 倍。
最后。他们还将这一方法应用于“自动化红队测试”。这是指在实验环境中使用一个模型来发现和利用另一个模型的弱点。在这种情况下,假设可以选择使用一个生成大量查询的小模型,或者使用一个生成较少查询但质量更高的大模型(两者成本相同)。他们的预测在解决如何在进行红队时最有效地分配计算预算方面很有用——在选择至关重要的情况下,他们的方法在 79% 的时间内确定了最优模型。
然而,Anthropic 团队的这一方法也并非完美,其实际效用取决于未来研究如何突破现有假设、扩展场景覆盖并增强鲁棒性。
在论文中,他们给出了一些未来发展方向,这些方向可能会显著提高预测的准确性和实用性。例如,他们提到,可以进一步探索如何为每个预测添加不确定性估计,以更好地评估预测的可靠性;他们还计划研究如何更有效地从评估集中捕捉尾部行为,这可能涉及到开发新的统计方法或改进现有的极端值理论应用;他们还希望将预测方法应用于更广泛的行为类型和更自然的查询分布,以验证其在不同场景下的适用性和有效性。
此外,他们还计划研究如何将预测方法与实时监控系统相结合,以便在模型部署后能够持续评估和管理风险。他们认为,通过实时监控最大引出概率,可以更及时地发现潜在的风险,并采取相应的措施。这种方法不仅可以提高预测的实用性,还可以帮助开发者在模型部署后更好地理解和应对可能出现的问题。
总的来说,这一方法为 LLM 罕见风险预测提供了统计学基础,有望成为模型安全评估的标准工具,帮助开发者在“能力迭代”与“风险控制”间找到平衡。
本文来自微信公众号:学术头条,编译:陈小宇
相关推荐
中国十大学会罕见联合抗议,反对学术交流政治化
银行间隔夜拆借利率罕见飙升,金融机构需警惕流动性变化
警惕AI大模型的“共情鸿沟”
危险的人脸识别
国外创投新闻|电动滑板车公司Neuron升级滑板车,旨在监测并规避危险驾驶行为
警惕科技巨头的ChatGPT崇拜
所见所听不一定是真的!警惕AI诈骗
Kimi能读200万字长文?警惕AI大模型热潮下的“创骗”新篇章
人和AI合作,到底有什么危险?
国家安全部:警惕开源信息成为泄密源头
网址: 警惕AI“罕见”危险行为 http://www.xishuta.com/newsview133155.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95198
- 2人类唯一的出路:变成人工智能 20989
- 3报告:抖音海外版下载量突破1 20908
- 4移动办公如何高效?谷歌研究了 20153
- 5人类唯一的出路: 变成人工智 20148
- 62023年起,银行存取款迎来 10317
- 7网传比亚迪一员工泄露华为机密 8472
- 8五一来了,大数据杀熟又想来, 8423
- 9滴滴出行被投诉价格操纵,网约 8046
- 10顶风作案?金山WPS被指套娃 7219



