DeepSeek开源周:开源可能是不想赚钱,也可能是想推动更大变化

“当 AI 足够强大后,开源还是不是一个好选择?”
整理丨刘倩 程曼祺
嘉宾丨美国西北大学 MLL Lab 博士王子涵
这是《晚点 LatePost》 「开源对话」系列的第 2 篇。该系列将收录与开源相关的访谈与讨论。系列文章见文末的合集#开源对话。
上周五,DeepSeek 在官方 Twitter 上预告了下一周会连续 5 天开源 5 个代码库,进入 “open-source week”开源周。
目前 DeepSeek 已放出的 4 个库,主要涉及 DeepSeek-V3/R1 相关的训练与推理代码。这是比发布技术报告和开源模型权重更深度的开源。有了训练和推理工具,开发者才能更好地在自己的系统里,实现 DeepSeek 系列模型的高效表现。
(注:所有 4 个库和后续开源可见 DeepSeek GitHub 中的 Open-Infra-Index。地址:GitHub -
deepseek-ai/open-infra-index: Production-tested AI infrastructure tools for efficient AGI d)
《晚点聊》在本周一邀请了一位 DeepSeek 前实习生,正在美国西北大学 MLL lab 攻读博士学位的王子涵,与我们一起聊 DeepSeek 开源周和更广泛的大模型开源。
王子涵今年刚博一,本科毕业于人大高瓴人工智能学院,大四时(2024 年)曾在 DeepSeek 实习半年,今年暑假即将前往一家美国 AI Agent 创业公司 Yutori 实习。他自己也做过多个开源项目。
开源的 DeepSeek 在今年春节爆火出圈,使开源正成为一种趋势:之前一直模型闭源的一些公司,现在陆续发布了自己的第一批开源模型。甚至 OpenAI CEO Sam Atlman 都说:“不开源,我们是站在了历史错误一边。”
这期播客实录也会收录在晚点「开源对话」系列。今天我们一次推送了两篇。第一篇的对谈嘉宾,章文嵩在 1998 年开始开源 Linux 系统重要组件,本篇的嘉宾王子涵则是 00 后。
贡献者在代际更替,编程语言在推陈出新,开源对象也从软件变成模型系统。而这里也有一些不变的东西。
以下是播客实录,我们做了文字精简。
*我们也制作了本期播客中投屏 “逛 GitHub” 的视频,文末可见。
“适配开源花了我一周多,一周我能跑模型,能做很多实验,能干很多事!”
花在开源的时间也能用来强化算法,这背后是一个优先级选择问题。当闭源的公司转向开源,非常需要额外人力支持。
晚点:子涵,可以先和我们的听友简单介绍一下自己?
王子涵:我目前在美国西北大学 MLL Lab 攻读博士学位。我的研究方向主要包括智能体决策(Agent Reasoning)、大语言模型等,近期也在探索长文本与效率增强( Efficiency Enhancement)的相关课题。我的导师李曼玲老师曾在斯坦福大学李飞飞和吴佳俊组里从事博士后研究,所以我们课题组的部分工作也涉及多模态建模与机器人(Robotics)。
再之前,我本科毕业于中国人民大学高瓴人工智能学院,去年曾在 DeepSeek 公司实习半年,接下来暑假会继续做 Agent,去一家 AI Agent 创业公司 Yutori 实习。
晚点:你之前的工作里,哪些和开源比较相关的?
王子涵:我大部分工作都开源了。其实我最早参与且比较出名的,是 2023 年暑研在季姮教授团队开展的 Agent 相关研究,我们大概是二月份左右开始做,最后构造了一个测试 Agent 能力的 Benchmark MINT,在当时做 Agent 是一个比较超前的选择。这是第一个影响力比较大的开源工作。
我也参与了 DeepSeek-V2 的研发,不过不是核心的贡献者,现在正在做用 DeepSeek-R1 相关技术结合 Agent 的开源项目 RAGEN,之后也会发一个正式的技术报告。
晚点:大模型涉及训练、推理、数据很多环节,现在当我们说一个大模型 “开源” 模型时,具体是哪部分在开源呢?
王子涵:模型开源有不同的层次。第一,当然必须有技术报告。DeepSeek 的技术报告就是一个把所有东西都讲得很清楚的示范。
其中 V3 是最详细的,真的是所有人都会去贡献,技术组几乎每个人都去写代码,都去想办法验证自己的 idea。
晚点:你刚刚在投屏上翻到了 V3 报告的贡献者部分,我正好看到了梁文锋的名字。
王子涵:对,我们会觉得团队里每个人都有贡献。其实不止有梁老板的名字,还有数据标注、Business(商务)这些。你只要在这个团队里,都会出贡献的。
而且 V3 (的报告)这么细,也因为它是一个基座模型(Base Model),包括预训练、微调、数据等一系列工作,工作量非常大,因此出一份 50 多页的报告不足为奇。
而 R1 是基于 V3,在上面迭代出了一套强化学习方法。R1 的技术报告,把强化学习讲清楚,就是一个非常好的报告了。
晚点:也分享一个我对 DeepSeek 爆火的传播路径的观察——这次 R1 全民出圈,影响力不局限于 AI 领域,很重要的基础就是 V3。V3 的详细报告,帮助 DeepSeek 在全球核心 AI 圈层里植入了一个印象:这是一家扎实,愿意开源贡献社区,让人尊敬、好奇的机构。
王子涵:其实 DeepSeek 去年并不出圈。而今年大家注意到它之后,再去看之前的报告,发现每一个都非常详细,写得非常好。
这就是开源的关键第一步:要有一个很好的报告,记录你到底做了什么事;它要服务于读者,让读者能由高到低,由浅入深地理解你的技术。
晚点:那开源的下一步呢?只有技术报告应该不是现在惯常说的开源大模型。
王子涵:还有就是开源模型权重。模型权重一般在 HuggingFace 上下载,比如进入一个模型的页面,点 “use this model”,然后可以选不同的 Library,你可以用 Transformers Library,也可以用 vLLM。
Transformers 不仅是一个开源推理框架,也是一个训练框架,由 HuggingFace 维护。vLLM 是一个开源推理框架。
这就来到大模型开源的更深层次,就是开源推理与训练的代码,或者说推理与训练框架。
这里我介绍两个开源的推理框架,一个是 vLLM,它是最广为人知的推理框架之一,它在 GitHub 上的 “星”(star)快 4 万了,Issues(其他开发者的提问)有几千,Pull Requests(大家对这个代码库的代码修改)也有好几百,生态做得比较好。
晚点:vLLM 是谁在维护,背后有一个公司之类的主体吗?
王子涵:最开始是伯克利、斯坦福的一群人,是基于他们发的 PagedAttention 那篇论文。当然现在贡献者就很多了,已经有 800 多人了。

vLLM 有 840 多位贡献者。提出 PagedAttention 的那篇论文是 Efficient Memory Management for Large Language Model Serving with PagedAttention。
另一个比较新的开源推理框架库是 SGLang,贡献者也很多。相比 vLLM,SGLang 跟潮流更紧,比如 DeepSeek-R1 出来后,他们第一时间就说支持 R1 的代码。这两个库各有特点,有一些不同的优化方向。
晚点:有公司做的、比较好的推理或训练框架吗?
王子涵:大部分公司会开源技术报告和模型权重,开源推理框架的比较少,开源训练框架的更少。
字节其实开源了一个训练框架 Verl(Volcano Engine Reinforcement Learning for LLMs)。我在做 RAGEN 时就用了 Verl,它能比较好地支持强化学习,比如 PPO 算法、分布式并行策略,如 FSDP 等。这套框架陪我度过了一些时期。
晚点:为什么比较少公司愿意开源训练框架?
王子涵:因为涉及的工作非常复杂。比如在公司里内部开发,可能不会那么在意代码规范,但要开源就要写得很清楚。
晚点:刚才说了技术报告、模型权重、推理框架、训练框架,那大模型数据集的开源是什么现状?
王子涵:几乎没有公司开源数据集。因为数据会比较敏感。比如在网上爬公共数据时可能包含了个人隐私或版权内容,开源后容易引发争议。
多数公司在技术报告里会提到数据混合比例,但不会放原始数据。这不完全是大家没能力或没意愿,主要还是安全性考虑。
晚点:DeepSeek 的开源涉及上述部分的哪些?
王子涵:除了数据集,应该都开源了。
晚点:训练框架也开源了?
王子涵:对,逐渐在开一些,但第一个开的应该是我当时做的 ESFT,就是 Expert-Specialized Fine-Tuning(专家专用微调)。
在混合专家模型(MoE)中有不同的专家,每个专家各有特点,和不同的任务有亲和性,也就是在某个任务下,某些专家的激活会更明显。
我们当时就想,能不能利用这个特性做更高效的模型微调,只微调和某个任务更相关的专家,其它的不调。这能减少计算资源,也能让 “专业的人做专业的事”,提高模型泛化能力。
晚点:一个大模型工作要从闭源转向开源,需要额外付出哪些努力和成本?你已经提到的是要规范代码,还有其它吗?
王子涵:主要是规范代码。再就是要让开源的这部分框架适配外部已经开源的整体框架。
因为当时他们(DeepSeek)暂时没有开源整个大基础库的打算,而我编写的代码都是基于这个大的库,那就需要用已经开源的框架再写一遍,让社区更好用起来。
当时做 ESFT 时,规范代码花了很久,大概一周多;适配开源的库花了两三天。
晚点:在 AI 研究者的维度里,一周多算很久吗?
王子涵:挺久了!一周多我能跑模型,能做很多实验,能干很多事。
这是一个优先级的问题。当你觉得自己的算法很有前景时,你当然会想先优化算法本身;但如果你觉得开源给社区用起来更重要,那做好开源的这些配套工作的优先级就更高。
晚点:所以当一些本来闭源的公司去开源模型或之后去开源更多框架,其实是需要额外的人力支持的?
王子涵:非常需要!而且很多公司正因为在开源上积淀比较少,就更需要下功夫。比如开源要怎么把代码写规范,这是没有一个系统教育的事。我在美国和一些人合作,有时也会发现 idea 很好,但代码细节看了比较难受。
晚点:也做很多开源工作的阿里就有专门的 “代码规约” 的工程,就是统一阿里程序员的编程习惯和格式,比如一个地方到底应该是两个空格,还是四个空格。这样在一个机构里大家才好沟通,新人也好接手老人的工作。
“DeepSeek FlashMLA 优化到了算子,去年我失败的在线训练想法败于不会改算子”
一些看似简单的操作,却需要很大努力才能做到工程实现。
晚点:Deepseek 上周释放的开源周主要信息:一是在 Twitter 上发布的预告,说要开源 “small but sincere”(小而诚挚)的工作;二是同一天在 GitHub 上发布了首个与开源周相关的库(Repo)是 “open-Infra-index”(GitHub 地址:),即开源基础设施指引。
从这些预告还有他们今天已放出来的 FlashMLA 这第一个代码库,你看到了什么亮点?你觉得这一整周里,Deepseek 可能会连续开源哪些内容?

DeepSeek 在 2 月 21 日发布的 “开源周” 预告。
王子涵:他们内部其实有一套模型训练和推理的框架。以 FlashMLA 为例,它算是一个推理加速的工具。DeepSeek 也有可能去开源 DeepSeek-V2、V3 或 R1 的训练和推理框架。(此后几天确实开源了相关工作。)
晚点:MLA 是 Deepseek-V2 里的一个创新点,FlashMLA 是用来提升 MLA 的效率?
王子涵:其实 DeepSeek 很多创新的目标都是提高效率,几乎每一个都是。以 V3 为例,有三项主要创新点:一是采用了 Meta 的 multi-token prediction(多令牌预测),模型能一次输出两个 token(之前是一次输出 1 个)。
二是低精度训练,即用更小的比特来存储数据,达成差不多的训练效果,这也是效率提升。(注:DeepSeek-V3 训练时大规模使用了 FP8 这种低精度、但高效率的数据格式,再结合一些别的数据格式做了混合精度训练)
三是和模型并行相关的。在执行流水线并行时,会出现较多 “空泡” 现象,比如要先进行前向计算,再进行反向计算,模型的不同层可能是闲置的,没在处理任何向量。此前采用的策略是模型的第一层在处理完第一个 Tensor(张量) 后,将其传递给第二层,同时第一层开始处理第二个 Tensor,持续推进流水线并行。Deepseek 在这个流程中进一步优化,减少了闲置的块的数量。所以我觉得它的每项创新都挺追求效率。
(注:MLA 是多层注意力机制,能增强模型对复杂模式的捕获能力。
Pipeline Parallelism(PP)流水线并行,是将模型的不同层(layer)按顺序分配到不同设备上的方法,能提高设备利用率。
前向(Forward)计算:根据输入数据和模型参数,计算输出结果的过程。
后向(Backward)计算:根据输出结果和损失函数,计算模型参数的梯度以更新参数的过程。)
晚点:你觉得 FlashMLA 的开源,对社区中哪类开发者最有价值?
王子涵:对每一类开发者都挺有帮助。FlashMLA,有人会注意到 MLA,也有很多人注意到它是 Flash,就是它对系统做了一些底层优化,应该是写了很多算子。而很多开发者不会做到这一层。
之前 FlahsAttention 就是做了系统优化。它和标准 Attention(注意力机制)都是在做相同的矩阵运算,但系统层算子优化能让它算得更快。
晚点:就是说,即使计算方式一样,但可以通过系统优化,让 GPU 等硬件发挥出更高的效率?
王子涵:对。以矩阵乘法为例,常规思路是逐个计算。但因为 GPU 可以并行计算。那在运算过程中,如果能以 GPU “更能听懂” 的方式去给指令,就能显著提升运算效率。
比如可以合并运算——利用加法结合律、乘法结合律、加法交换律等数方式调整运算顺序,最终运算效率可能会不同。
FlashAttention 是一个很经典的例子。Attention 计算过程中,原本包含多种不同运算,FlashAttention 给它合并为一种运算,然后在 GPU 中一次性完成。
因为 GPU 其实有好几层。简单理解,最里面那一层最小、但算得最快,外面有层比较大,能装更多东西,但算得没那么快。实际计算过程,就是把外层一个大矩阵一批批送进去里面操作,这个运送是比较慢的。如果能只送一次,在里面做完多种操作再送出来,就会比较快。
晚点:你提到多数开发者不会做算子优化,而 DeepSeek 自己会写很多算子,这是能力的差异还是意愿的差异?
王子涵:在我看来是能力差异,我自己就不太会写。
我去年有一个失败的项目,是想让大语言模型做在线训练(Online Training)。此前,语言模型都是离线训练(Offline Training)的,就是用得到的数据,再用数据里的奖励信号去训练模型。
我们当时想让语言模型能实时生成数据,然后通过环境或一个奖励模型给出反馈,评判数据好坏,再进一步去训练模型。当时我们认为这个过程很简单:模型生成数据→获得反馈→更新模型→继续生成新数据。
然而在编写代码时遇到了难题。写代码有两个方法,一是用当时比较厉害的推理框架,但我们不太会改那个框架,它写到了算子层的优化,我们也看不太懂,相当于这个模型就 “固定” 了,你不能一边让它生成东西,一边更新模型。
还有一种方式就是我们自己去写推理框架,但是真的没能力做这个事。我们要写一个能生成得很快,又能兼容模型更新的库,很难。
我讲这个例子是想说,很多时候一些看似简单的操作,却需要很大努力才能做到工程实现。
晚点:虽然 FlashMLA 刚放出来一天,GitHub 上已经有不少社区反馈,有人说想要 FP8 的版本(目前开源的是 BF16 和 FP16 数据格式的版本),有人问何时支持 NPU(一种专用 AI 加速芯片)。可以给大家解释一下这些开发者的诉求吗?
王子涵:FP8 就是 DeepSeek-V3 的低精度训练。FlashMLA 本身是一个优化 Attention KV cache 的技术,它如果能和模型精度的改进结合,就会更快。
Deepseek 这次开源 5 个库后,还有一项比较需要投入精力的工作,就是综合这 5 个库,索引只是一部分,另一个可能是合成一个库,让开发者能随心调用 5 个库里的不同内容。但这个融合过程也可能出 bug,就需要做更多工作。
(注:KV cache 是键值缓存,Transformer 的 Attention 机制中,每个输入的 token 会生成对应的键(Key,K)和值(Value,V)。K 用于计算 token 间的相关性,而 V 包含了被注意的内容信息。)
“一直开源最强模型,可能是不想赚钱,也可能是想推动更大变化”
有多大?最大的是,重构整个行业生态,成为一种行业标准。而当 AI 足够强大,开源最强模型也许不再是好的选择。
晚点:现在也可以观察到,不同公司有不同的大模型开源策略,比如 DeepSeek 一直是开源自己最强的模型,而有些机构选择留着最强的模型闭源,开源其它模型。这些差异的背后是什么?
王子涵:主要和盈利模式与诉求有关。比如有的公司不靠 API 赚钱,它就不需要靠保留最强模型获得溢价。
第一个可能是,老板就不想赚钱,要造福社会。
第二个可能是,他想做更大的事。有多大?最大的是,重构整个行业生态,比如成为一种行业标准。
美国的一个机构 Ai2(Allen AI 研究所,由已故微软联创保罗·艾伦创立的一个非盈利性研究机构)就开源了自己最强的模型,它根本不赚钱,它还极罕见地开源了数据集。
还有一个模型叫 Pythia 也开源了数据集,来自 EleutherAI(另一家美国非营利性 AI 机构)。Pythia 特别开,它怕开发者承担独自训练的风险,把中间数个 chekpoint(模型训练中的检查点)的模型权重也开源了,从第 0 步到 1000 步每步都给了权重,之后是每 1000 步。保姆式开源!
那另一方面,如果有些公司它需要 API 订阅费的收入,又想造福社区,它就会选择开源不涉及当前阶段商业核心的模型,维持竞争优势,比如开源一个小一点的模型。
晚点:你觉得今年我们会看到 OpenAI 开源最强的模型吗?
王子涵:不太确定。我很期待他们的开源计划。
晚点:Sam Altman 在 Twitter 发起投票,给了两个开源选项,一是 o3-mini,一是手机端可用的模型(phone-sized model)。你更期待开源哪个?
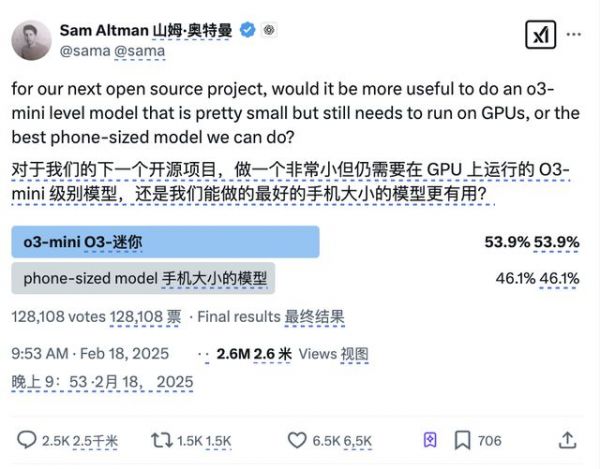
2 月 18 日,Sam Altman 发起开源项目投票。
王子涵:开哪个都很好,都会帮到一拨人。但我觉得不开源也有 make sense 的地方。
我一直在构想一个场景,如果以后大语言模型或者说这套 AI 足够强后,开源还是不是一个好选择?我的直觉是,到时不开源最强模型,只开比较小的模型更有道理。因为开源最强模型,很难防止有人去用它做坏事。
我有一次 Twitter 账号被黑了,就是因为有一个人用大语言模型训了一个 Agent,到处以不同姿态给人发 Twitter 邀请,最终目的就是让你觉得它特别靠谱,然后去点击某个链接,他黑了别人的账号后,就去发广告。
未来模型更强了,还可以做更坏的事,比如注册 100 个小号去网络暴力,那就麻烦了。
晚点:这我想到前几天看真格戴雨森分享的一句 Ilya 的话:如果你把智能看得比人类的其他所有品质都重要,那你将会度过一段艰难的日子。(If you value intelligence above all other human qualities, you’re gonna have a bad time.)这是 Ilya 2023 年和 Altman 有分歧时发的 Twitter。
王子涵:对,不要太卷了。其实当我们有了这么强的 AI,人会怀疑自己存在的价值。
不过我觉得人的价值本来就不在于智力。人其实不需要有什么价值,就像你去一个新游戏注册账号,成为了一个新玩家,别人问你能为游戏带来什么,你说我带来了一个新玩家(指自己的存在本身)。
围棋那群人已经经历了这个过程:从抗拒 AI 到加入 AI,到最后把它当成娱乐——我知道 AI 这块已经比人强了,我就不去正面冲突,我去学习它。
没必要比谁智力高,人有时真比不过 AI,那就享受它吧。
题图来源:《头号玩家》
相关推荐
DeepSeek开源周观察:让所有人都能用起来R1
DeepSeek开源周Day1:FlashMLA:大家省,才是真的省
DeepSeek扔的第二枚开源王炸到底是什么?
DeepSeek登顶140国榜首,免费开源的真相究竟是什么?
微信接入DeepSeek,周鸿祎会不会眼前一黑……
微信也接不住DeepSeek的流量?
DeepSeek最新开源,比英伟达更懂如何优化英伟达?
一文详解:DeepSeek刚开源的DeepGEMM是怎么回事?
DeepSeek大模型专家交流
DeepSeek连开三源,解开训练省钱之谜
网址: DeepSeek开源周:开源可能是不想赚钱,也可能是想推动更大变化 http://www.xishuta.com/newsview133191.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95209
- 2人类唯一的出路:变成人工智能 21059
- 3报告:抖音海外版下载量突破1 21003
- 4人类唯一的出路: 变成人工智 20223
- 5移动办公如何高效?谷歌研究了 20219
- 62023年起,银行存取款迎来 10322
- 7五一来了,大数据杀熟又想来, 8482
- 8网传比亚迪一员工泄露华为机密 8479
- 9滴滴出行被投诉价格操纵,网约 8104
- 10顶风作案?金山WPS被指套娃 7222



