DeepSeek开源周收官重磅发布:理论成本利润率545%,日赚346万!
本周以来,DeepSeek开启“开源周”,给人工智能领域扔下数颗“重磅炸弹”。回顾DeepSeek这五天开源的内容,信息量很大,具体来看:
周一,DeepSeek宣布开源FlashMLA。FlashMLA是DeepSeek用于Hopper GPU的高效MLA解码内核,并针对可变长度序列进行了优化,现已投入生产;
周二,DeepSeek宣布开源DeepEP,即首个用于MoE模型训练和推理的开源EP通信库,提供高吞吐量和低延迟的all-to-all GPU内核;
周三,DeepSeek宣布开源DeepGEMM。其同时支持密集布局和两种MoE布局,完全即时编译,可为V3/R1模型的训练和推理提供强大支持等;
周四,DeepSeek宣布开源Optimized Parallelism Strategies。其主要针对大规模模型训练中的效率问题;
周五,DeepSeek宣布开源Fire-Flyer文件系统(3FS),以及基于3FS的数据处理框架Smallpond。
而在3月1日,DeepSeek发表题为《DeepSeek-V3/R1 推理系统概览》的文章,全面揭晓V3/R1 推理系统背后的关键秘密,为开源周画上完美的句号。
最为引人注目的是,文章首次披露了DeepSeek的理论成本和利润率等关键信息。据介绍,假定GPU租赁成本为2美元/小时,总成本为87072美元/天;如果所有tokens全部按照DeepSeek R1的定价计算,理论上一天的总收入为562027美元/天,成本利润率为545%。
R1 模型是如何做到在控制成本的情况下做到高收益的?这篇官方文章给出了关键的数据信息。
DeepSeek-V3 / R1 推理系统概览
|答主:DeepSeek
DeepSeek-V3 / R1 推理系统的优化目标是:更大的吞吐,更低的延迟。
为了实现这两个目标,我们的方案是使用大规模跨节点专家并行(Expert Parallelism / EP)。首先 EP 使得 batch size 大大增加,从而提高 GPU 矩阵乘法的效率,提高吞吐。其次 EP 使得专家分散在不同的 GPU 上,每个 GPU 只需要计算很少的专家(因此更少的访存需求),从而降低延迟。
但 EP 同时也增加了系统的复杂性。复杂性主要体现在两个方面:
EP 引入跨节点的传输。为了优化吞吐,需要设计合适的计算流程使得传输和计算可以同步进行。
EP 涉及多个节点,因此天然需要 Data Parallelism(DP),不同的 DP 之间需要进行负载均衡。
因此,本文的主要内容是如何使用 EP 增大 batch size,如何隐藏传输的耗时,如何进行负载均衡。
由于 DeepSeek-V3 / R1 的专家数量众多,并且每层 256 个专家中仅激活其中 8 个。模型的高度稀疏性决定了我们必须采用很大的 overall batch size,才能给每个专家提供足够的 expert batch size,从而实现更大的吞吐、更低的延时。需要大规模跨节点专家并行(Expert Parallelism / EP)。
我们采用多机多卡间的专家并行策略来达到以下目的:
Prefill:路由专家 EP32、MLA 和共享专家 DP32,一个部署单元是 4 节点,32 个冗余路由专家,每张卡 9 个路由专家和 1 个共享专家
Decode:路由专家 EP144、MLA 和共享专家 DP144,一个部署单元是 18 节点,32 个冗余路由专家,每张卡 2 个路由专家和 1 个共享专家
多机多卡的专家并行会引入比较大的通信开销,所以我们使用了双 batch 重叠来掩盖通信开销,提高整体吞吐。
对于 prefill 阶段,两个 batch 的计算和通信交错进行,一个 batch 在进行计算的时候可以去掩盖另一个 batch 的通信开销;
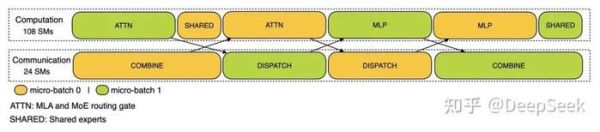 Prefill 阶段的双 batch 重叠
Prefill 阶段的双 batch 重叠对于 decode 阶段,不同阶段的执行时间有所差别,所以我们把 attention 部分拆成了两个 stage,共计 5 个 stage 的流水线来实现计算和通信的重叠。
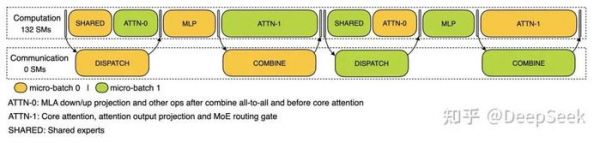 Decode 阶段的双 batch 重叠
Decode 阶段的双 batch 重叠由于采用了很大规模的并行(包括数据并行和专家并行),如果某个 GPU 的计算或通信负载过重,将成为性能瓶颈,拖慢整个系统;同时其他 GPU 因为等待而空转,造成整体利用率下降。因此我们需要尽可能地为每个 GPU 分配均衡的计算负载、通信负载。
1. Prefill Load Balancer
1)核心问题:不同数据并行(DP)实例上的请求个数、长度不同,导致 core-attention 计算量、dispatch 发送量也不同
2)优化目标:各 GPU 的计算量尽量相同(core-attention 计算负载均衡)、输入的 token 数量也尽量相同(dispatch 发送量负载均衡),避免部分 GPU 处理时间过长
2. Decode Load Balancer
1)核心问题:不同数据并行(DP)实例上的请求数量、长度不同,导致 core-attention 计算量(与 KVCache 占用量相关)、dispatch 发送量不同
2)优化目标:各 GPU 的 KVCache 占用量尽量相同(core-attention 计算负载均衡)、请求数量尽量相同(dispatch 发送量负载均衡)
3. Expert-Parallel Load Balancer
1)核心问题:对于给定 MoE 模型,存在一些天然的高负载专家(expert),导致不同 GPU 的专家计算负载不均衡
2)优化目标:每个 GPU 上的专家计算量均衡(即最小化所有 GPU 的 dispatch 接收量的最大值)
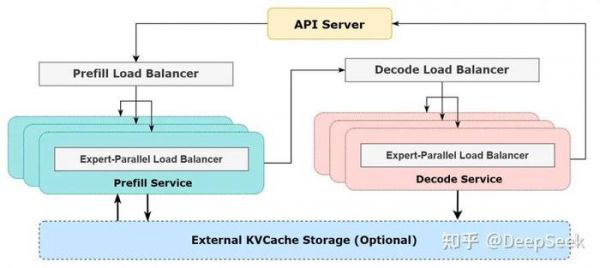
DeepSeek V3 和 R1 的所有服务均使用 H800 GPU,使用和训练一致的精度,即矩阵计算和 dispatch 传输采用和训练一致的 FP8 格式,core-attention 计算和 combine 传输采用和训练一致的 BF16,最大程度保证了服务效果。
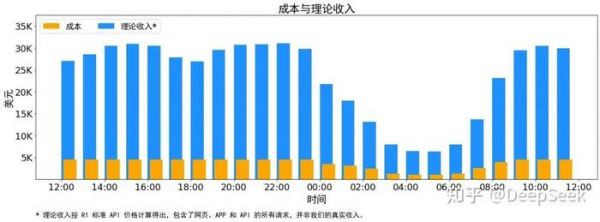
另外,由于白天的服务负荷高,晚上的服务负荷低,因此我们实现了一套机制,在白天负荷高的时候,用所有节点部署推理服务。晚上负荷低的时候,减少推理节点,以用来做研究和训练。在最近的 24 小时里(北京时间 2025/02/27 12:00 至 2025/02/28 12:00),DeepSeek V3 和 R1 推理服务占用节点总和,峰值占用为 278 个节点,平均占用 226.75 个节点(每个节点为 8 个 H800 GPU)。假定 GPU 租赁成本为 2 美金/小时,总成本为 $87,072/天。
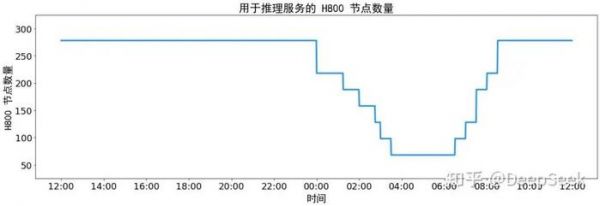
在 24 小时统计时段内,DeepSeek V3 和 R1:
输入 token 总数为 608B,其中 342B tokens(56.3%)命中 KVCache 硬盘缓存。
输出 token 总数为 168B。平均输出速率为 20~22 tps,平均每输出一个 token 的 KVCache 长度是 4989。
平均每台 H800 的吞吐量为:对于 prefill 任务,输入吞吐约 73.7k tokens/s(含缓存命中);对于 decode 任务,输出吞吐约 14.8k tokens/s。
以上统计包括了网页、APP 和 API 的所有负载。如果所有 tokens 全部按照 DeepSeek R1 的定价[1]计算,理论上一天的总收入为 $562,027,成本利润率 545%。
 参考
参考1.^DeepSeek R1 的定价:$0.14 / 百万输入 tokens (缓存命中),$0.55 / 百万输入 tokens (缓存未命中),$2.19 / 百万输出 tokens。
(转自:浪说量化)
相关推荐
DeepSeek开源周收官重磅发布:理论成本利润率545%,日赚346万!
DeepSeek公布成本、收入和利润率,最高可日赚346万
DeepSeek“理论利润率”545%,又要惊吓硅谷华尔街了
一场由DeepSeek公布利润率引发的“血案”
DeepSeek开源周Day1:FlashMLA:大家省,才是真的省
DeepSeek开源周观察:让所有人都能用起来R1
DeepSeek开源周:开源可能是不想赚钱,也可能是想推动更大变化
DeepSeek促AI开源浪潮涌动
DeepSeek扔的第二枚开源王炸到底是什么?
微信接入DeepSeek,周鸿祎会不会眼前一黑……
网址: DeepSeek开源周收官重磅发布:理论成本利润率545%,日赚346万! http://www.xishuta.com/newsview133285.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95228
- 2人类唯一的出路:变成人工智能 21183
- 3报告:抖音海外版下载量突破1 21148
- 4移动办公如何高效?谷歌研究了 20339
- 5人类唯一的出路: 变成人工智 20338
- 62023年起,银行存取款迎来 10336
- 7五一来了,大数据杀熟又想来, 8596
- 8网传比亚迪一员工泄露华为机密 8505
- 9滴滴出行被投诉价格操纵,网约 8215
- 10顶风作案?金山WPS被指套娃 7230



