2nm芯片发布,剑指英伟达
近日,Marvell展示了其用于下一代AI和云基础设施的首款2nm硅片IP。该工作硅片采用台积电的2nm工艺生产,是Marvell平台的一部分,用于开发定制XPU、交换机和其他技术,以帮助云服务提供商提升其全球运营的性能、效率和经济潜力。
Marvell表示,公司的平台战略以开发全面的半导体IP产品组合为中心,包括电气和光学串行器/反串行器(SerDes)、2D和3D设备的芯片到芯片互连、先进的封装技术、硅光子学、定制高带宽存储器(HBM)计算架构、片上静态随机存取存储器(SRAM)、片上系统(SoC)结构和计算结构接口(如PCIe Gen 7),它们可作为开发定制AI加速器、CPU、光学DSP、高性能交换机和其他技术的基础。
此外,Marvell还提供了3D同步双向I/O,运行速度高达6.4 Gbits/秒,用于连接芯片内部的垂直堆叠芯片。如今,连接芯片堆栈的I/O路径通常是单向的。转向双向I/O使设计人员能够将带宽提高两倍和/或将连接数量减少50%。
3D同步双向I/O还将为芯片设计人员提供更大的设计灵活性。当今最先进的芯片超过了将晶体管图案描绘到硅片上的光罩或光掩模的尺寸。为了增加晶体管数量,预计所有先进节点处理器中约有30%将基于小芯片设计,即将多个芯片组合到同一个封装中。借助3D同步双向I/O,设计人员将能够将更多芯片组合成越来越高的堆栈,以用于2.5D、3D和3.5D设备,这些设备比传统的单片硅片设备提供更多功能,同时仍能像单个设备一样运行。
Marvell表示,鉴于预计每年TAM增长率为45%,预计到2028年定制硅片将占据加速计算市场的约25%。换而言之,Marvell将有望给英伟达带来新的挑战。
2nm,早已发布
早在2024年3月,Marvell就推出了其新的2nm IP技术平台,该平台专门针对基于台积电2nm级工艺技术(可能包括N2和N2P)制造的加速基础设施定制芯片而量身定制。该平台包括开发云优化加速器、以太网交换机和数字信号处理器所必需的技术。
在Marvell看来,2nm平台将使Marvell能够提供高度差异化的模拟、混合信号和基础IP,以构建加速基础设施。我们与台积电在5nm、3nm以及现在的2nm平台上的合作,对于帮助Marvell拓展硅片所能实现的极限起到了重要作用。”
2nm平台基于Marvell广泛的IP产品组合,其中包括能够实现超过200 Gbps速度的先进SerDes、处理器子系统、加密引擎、SoC结构和高带宽物理层接口。这些IP对于开发和生产一系列设备至关重要,例如定制计算加速器和光互连数字信号处理器。它们正在成为AI集群、云数据中心和其他支持用于AI和HPC工作负载的机器的基础设施的通用构建块。
虽然这些IP对于各种处理器、DSP和网络设备至关重要,但从头开始开发它们(尤其是对于依赖于全栅极纳米片晶体管的台积电2nm级工艺技术)既困难又耗时,有时效率低下,无论是从芯片空间还是经济角度来看都是如此。这正是Marvell的IP产品组合有望大显身手的地方。
在更早之前,Marvell凭借其5nm平台,从快速跟随者转变为将先进节点技术引入基础设施硅片的领导者。Marvell紧随其后,推出了多款5nm设计,并推出了首款基于台积电3nm工艺的基础设施硅片产品组合。
正是在这些研究基础上,Marvell火力全开。
定制HBM架构横空出世
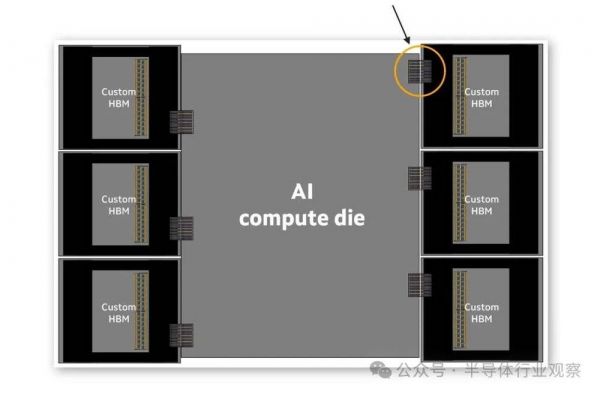
据相关报道,Marvell在去年12月发布的一种新的定制HBM计算架构,使XPU能够实现更高的计算和内存密度。该新技术可供其所有定制硅片客户使用,以提高其定制XPU的性能、效率和TCO。Marvell正在与其云客户和领先的HBM制造商Micron、三星电子和SK海力士合作,为下一代XPU定义和开发定制HBM解决方案。
Marvell表示,HBM是XPU中的关键组件,采用先进的2.5D封装技术和高速行业标准接口。然而,当前基于标准接口的架构限制了XPU的扩展。新的Marvell定制HBM计算架构引入了定制接口,以优化特定XPU设计的性能、功率、芯片尺寸和成本。这种方法考虑了计算硅片、HBM堆栈和封装。
但是,HBM内存牺牲了容量和可扩展性,换取了更高的带宽。一般来说,HBM部署在CPU和加速器或XPU旁边的方式是,它通过连接两块硅片的硅中介层上的标准线路进行连接。XPU通常有两个或更多个HBM堆栈,由DRAM堆栈和基片组成。
为此,通过定制HBM内存子系统(包括堆栈本身),Marvell正在推进云数据中心基础设施的定制化。Marvell正在与主要的HBM制造商合作,以实施这种新架构并满足云数据中心运营商的需求。
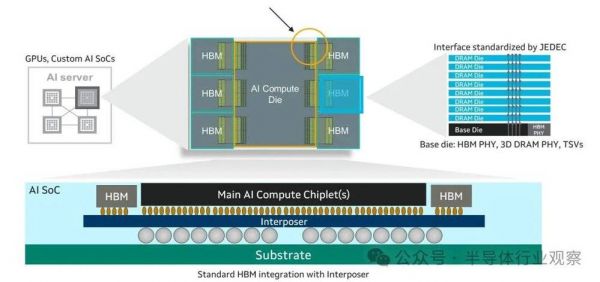
Marvell定制HBM计算架构通过序列化和加速其内部AI计算加速器硅片与HBM基片之间的I/O接口来增强XPU。与标准HBM接口相比,这可提高性能并将接口功耗降低高达70%。优化的接口还减少了每个芯片所需的硅片空间,从而允许将HBM支持逻辑集成到基片上。这些节省的空间(高达25%)可用于增强计算能力、添加新功能,并支持高达33%的HBM堆栈,从而增加每个XPU的内存容量。这些改进提高了XPU的性能和能效,同时降低了云运营商的TCO。

在Marvell看来,这种转变是定制XPU总体趋势的一部分,将对XPU的性能、功耗和设计产生根本而深远的影响。HBM于2013年发明,由垂直堆叠的高速DRAM组成,这些DRAM位于一个称为HBM基片的芯片上,该芯片控制I/O接口并管理系统。基片和DRAM芯片通过金属凸块连接。
垂直堆叠有效地让芯片设计人员能够增加靠近处理器的内存量,从而提高性能。几年前,最先进的加速器包含80GB的HBM 2。明年,最高水准将达到288GB。
尽管如此,对更大内存的需求仍将持续,这给设计师带来了节省空间、功耗和成本的压力。HBM目前可占XPU内部可用空间的25%,占总成本的40%。HBM 4是当前的尖端标准,具有由32个64位通道组成的I/O-巨大的尺寸已经使芯片封装的某些方面变得极其复杂。
Marvell定制HBM计算架构涉及优化基础HBM芯片及其接口,目前围绕JEDEC标准设计,其解决方案经过独特设计,以与主机AI计算芯片的设计、特性和性能目标相吻合。
想象一下,超大规模企业想要一个AI推理XPU,用于挤进密集商业区或城市走廊的边缘数据中心。成本和功耗将处于高位,而绝对计算性能可能不那么重要。定制HBM解决方案可能涉及减小AI计算芯片的尺寸,以节省芯片尺寸和功耗,而其他考虑则高于其他考虑。
另一方面,为大规模AI训练集群提供动力的XPU的HBM子系统可能会针对容量和高带宽进行调整。在这种情况下,重点可能是减小I/O接口的大小。减小I/O大小会在芯片侧面所谓的“beachfront”上为更多接口腾出空间,从而提高总带宽。
高性能XPU扮演重要角色
在推出定制的HBM架构之后,Marvell带来了全新的XPU。
Marvell表示,新的定制HBM架构使客户能够将CPO无缝集成到其下一代定制XPU中,并将其AI服务器的规模从目前使用铜互连的机架内数十个XPU扩展到使用CPO的多个机架中的数百个XPU,从而提高AI服务器的性能。创新的架构使云超大规模提供商能够开发定制XPU,以实现更高的带宽密度,并在单个AI服务器内提供更长距离的XPU到XPU连接,同时具有最佳延迟和功率效率。该架构现已可供Marvell客户的下一代定制XPU设计使用。
Marvell定制AI加速器架构使用高速SerDes、芯片到芯片接口和先进封装技术,将XPU计算硅片、HBM和其他芯片与Marvell 3D SiPho引擎整合在同一基板上。这种方法无需电信号离开XPU封装进入铜缆或穿过印刷电路板。借助集成光学器件,XPU之间的连接可以实现更快的数据传输速率和比电缆长100倍的距离。这可以在AI服务器内实现跨多个机架的扩展连接,并具有最佳延迟和功耗。
CPO技术将光学元件直接集成在单个封装内,从而最大限度地缩短了电气路径长度。这种紧密耦合可显著减少信号损耗、增强高速信号完整性并最大限度地减少延迟。CPO利用高带宽硅光子光学引擎来提高数据吞吐量,与传统铜连接相比,硅光子光学引擎可提供更高的数据传输速率,并且不易受到电磁干扰。这种集成还通过减少对高功率电气驱动器、中继器和重定时器的需求来提高电源效率。通过实现更长距离和更高密度的XPU到XPU连接,CPO技术促进了高性能、高容量扩展AI服务器的开发,从而优化了下一代加速基础设施的计算性能和功耗。
业界首款Marvell 3D SiPho引擎在OFC 2024上首次亮相,支持200Gbps电气和光学接口,是将CPO整合到XPU中的基本构建模块。Marvell 6.4T 3D SiPho引擎是一款高度集成的光学引擎,具有32个200G电气和光学接口通道、数百个组件(例如调制器、光电探测器、调制器驱动器、跨阻放大器、微控制器)以及大量其他无源组件,这些组件集成在一个统一的设备中,与具有100G电气和光学接口的同类设备相比,可提供2倍的带宽、2倍的输入/输出带宽密度和30%的每比特功耗降低。多家客户正在评估该技术,以将其集成到其下一代解决方案中。
八年多来,Marvell为连续几代高性能、低功耗的COLORZ数据中心互连光学模块提供了硅光子技术。该技术已通过众多领先的超大规模数据中心的认证并投入大批量生产,以满足其不断增长的数据中心到数据中心的带宽需求。Marvell硅光子器件的现场运行时间已超过100亿小时。
Marvell一直是改变互连技术的先驱,致力于提高加速基础设施的性能、可扩展性和经济性。Marvell互连产品组合包括用于定制XPU内高性能通信的高性能SerDes和die-to-die技术IP、用于在同一板上实现CPU和XPU之间高效短距离连接的PCIe重定时器、用于克服内存挑战的突破性CXL设备、用于机架内短距离连接的有源电缆和有源光缆数字信号处理器、用于数据中心内机架到机架连接的不断扩展的PAM光学DSP以及用于连接相距数千公里的数据中心的相干DSP和数据中心互连模块。
写在最后
正如很多文章报道,Marvell和Broadcom都是云超大规模企业的主要定制ASIC芯片提供商。例如,亚马逊多年来一直与Marvell合作开发AWS Trainium,这是其用于AI训练和推理工作负载的内部AI芯片。AWS Trainium2已被亚马逊和其他合作伙伴采用。在亚马逊最近的财报电话会议上,管理层透露,亚马逊与Anthropic合作建立了Project Rainier,这是一个用于AI工作负载的Trainium 2超级服务器集群。亚马逊计划在今年晚些时候推出其下一代Trainium 3芯片。
因此,上述XPU的新突破对Marvell来说很重要,因为他们的ASIC技术可以继续支持超大规模企业和AI模型公司开发自己的GPU/XPU芯片,为Nvidia和AMD提供具有成本效益的替代方案。
在2025财年第三季度财报电话会议上,Marvell指出,其与Hyperscalers的定制硅片合作伙伴关系的产量增长强于预期。管理层对未来定制硅片的增长充满信心。换而言之,在定制硅片需求增加的推动下,Marvell的增长将在不久的将来加速。
相关推荐
2nm芯片发布,剑指英伟达
三星2nm制程初始良率达30%,高于预期!
疯狂涨价的2nm芯片:一场少数人的内卷游戏
2nm芯片,胜负已分?
2nm,芯片巨头怎么看?
叫板英特尔,英伟达发布首个 CPU,集齐“三芯”!
英伟达发布首个 CPU,集齐“三芯”叫板英特尔?
台积电2nm芯片生产良率超6成
世芯电子成功流片2nm测试芯片
英伟达/AMD/英特尔的哪些芯片将受限?
网址: 2nm芯片发布,剑指英伟达 http://www.xishuta.com/newsview133362.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95228
- 2人类唯一的出路:变成人工智能 21183
- 3报告:抖音海外版下载量突破1 21148
- 4移动办公如何高效?谷歌研究了 20339
- 5人类唯一的出路: 变成人工智 20338
- 62023年起,银行存取款迎来 10336
- 7五一来了,大数据杀熟又想来, 8596
- 8网传比亚迪一员工泄露华为机密 8505
- 9滴滴出行被投诉价格操纵,网约 8215
- 10顶风作案?金山WPS被指套娃 7230



