郭毅可:人工智能的生态与思想
编者按:本文来自微信公众号“高山大学”(ID:gasadaxue),作者GASA,36氪经授权发布。原题目《郭毅可:人工智能的生态与思想》
郭毅可,英国皇家工程院院士、欧洲科学院院士,任英国帝国理工学院数据科学研究所所长,终身教授。曾主持并完成了英国六大 e-Science 项目之一的“发现网”(Discovery Net)。 △郭毅可教授在高山大学授课现场
△郭毅可教授在高山大学授课现场课前思考
1.人工智能的真正意义是什么?
2.未来40年里,人工智能可能会做成哪些事情?
3.与机器人共处的二元社会里,人类将面临哪些问题?
4.数据的所有权如何界定?
5.什么样的算法是好算法?
今天课程的题目《科学的梦想与踏实的努力》想讲一个问题,就是人工智能的生态与发展人工智能的思想。
你们来到英国,可能已经发现,英国与美国的创新是完全不同的,硅谷是在汽车库里搞发明,英国是在咖啡店、酒吧里聊大天,但同时不能不承认,聊出来的是引领整个工业革命的思想和规范现代社会的法则。而今天,英国是人工智能技术的发源地和整个思想的策源地。图灵的思想、DeepMind的技术都出自这里。
英国是一个思想的国家,而不仅仅是一个技术的国家。
今天,我来谈谈一些思想上的东西,也谈谈一些实实在在的努力。其实,这两者是分不开的。没有思想的努力不是盲从,就是瞎忙;没有努力的思想不是胡思乱想,就是痴心妄想。
人工智能走向人文科学
没有人怀疑AI会改变每个人的生活。大家都有自己的认识,但许多的讨论是关于多少年之内有多少人工作要被机器所取代。这不是我们这些人工智能的研究者所关心的。我们关心的是我们每天、每月、每年可以把多少人的智能行为由机器来实现。所以,人工智能的努力,并不是做机器人,做自动驾驶汽车,真正有意义的开创性工作都是在人文领域,比如能让计算机去做科学,让计算机去创作,如写小说、生成电影,让计算机去辩论、去做政治,这些是真正人类做的事情,现在,我们希望机器去做。
我们不要混淆了今天对人工智能技术应用的开拓和对人工智能的科学思想和技术本身的发展。人工智能的科学思想重在提出关于机器智能的本质、机器智能行为以及人类智能的相互关系的问题。所以,不要一讲人工智能,就想到人脸识别。人脸识别并不是我们要想的问题,那是要做的事情。想的和做的,一个是蓝天,一个是大地。
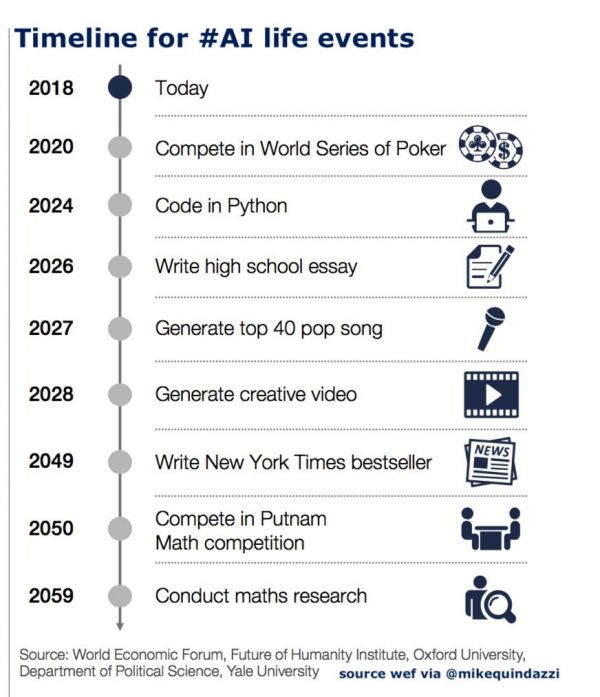 上面的时间表是在世界经济论坛上公布的。这是牛津大学的研究成果(这也是英国人的“胡思乱想”,但挺有道理的)。现在计算机已经能够打扑克,离打麻将还有点距离。
上面的时间表是在世界经济论坛上公布的。这是牛津大学的研究成果(这也是英国人的“胡思乱想”,但挺有道理的)。现在计算机已经能够打扑克,离打麻将还有点距离。扑克比下棋难,麻将比扑克难。下棋时双方都知道对方的棋局,也就是说做决定时,关于对手的信息是完全知道的。而打扑克时,你并不完全知道其他对手的牌局,做决定时,关于对手的信息是不完全的。所以,机器打牌时,对想象力的要求就要高多了。
打好了牌,我们就要求计算机做更有挑战性的工作。如到2027年,计算机能写进入Top 40的流行歌曲了。现在计算机已经能写歌了,但还达不到Top 40的水平。最近有一首学生写的歌曲放到网上,能够通过我的图灵测试,因为我确实听不出是机器写的。接下来做视频、写新闻,到计算机打赢数学竞赛还需要30年。
这些时间节点都在挑战人类的抽象能力、创造能力,甚至是人类感情的机器再造。所以,我们就是在为自己创造一个“复制品”, 或叫做“智能替代物”。我们之所以孜孜不倦地研究计算机下棋、打扑克、做数学题、写文章,实际都是在努力创造“智能替代物”。而如果我们达到了复制自己的目标的话, 那么,这样的复制品本身就也应该和我们一样, 有了造物主的能力。我们就要生活在和这样的“智能替代物”共存的二元社会(Symbiotic Society)中。这将是人类从来没有过的天下。
自从有了人类以来,我们所创造和经历的一直是一元社会,人类处于食物链的顶端。但现在不一样,我们有了二元社会,我们制造了自己的对手、伙伴。所以我们现在必须要考虑的大问题是,人类将来怎样在这样的二元社会里生活?
在这个思路下去思考人工智能,思考人类的未来,在今天往往是哲学家的任务,而正如著名哲学家维特根斯坦说的那样:“真正的发现是能让我想不做哲学就可以不做的发现,也就是说是能让哲学消停的发现”,对二元社会的思考的真正意义是在于跳出哲学家的理性思辨,真正在创造二元社会的实践中去想发现这个新社会的新的法则,规律和理性。
人工智能时代
思考这个问题必须要从历史开始。展望未来,历史是指今天的人工智能时代。可是现在讲人工智能时代常常是局限于今天的技术,好像机器学习技术就代表着人工智能时代,其实并不是的,人工智能时代有它整个的生态环境,这样的生态环境是信息技术发展的多种技术的混合体。
这包括了云计算,移动互联网,大数据和人工智能,这些技术的发展在互联网上创造一个新的经济,就是服务经济。云计算实现了计算资源的社会化,移动互联网实现了服务经济的社会化,大数据互联网上的服务提供了生产资料, 而人工智能则为数据为主体的互联网服务经济提供了生产工具。
人工智能研究的社会背景就是这样的新经济和这样的新经济下的新的社会结构,我们应该看到以下几个方面:
第一是现有的中心化的经济结构的解体,产生无中心化的新的经济组织结构。
第二是数据的资产化和资本化,产生新生产资料下的数据经济。数据经济是数据作为资产和资本的经济,实现数据的交易和买卖。
第三是普适化的人工智能,人工智能作为新的生产工具,为各种产业赋能。
有了新的生产资料、生产工具、新的经济模式, 就会导致新的社会结构的形成。这个新的社会比较怪,我们不能光从人考虑了,还要考虑作为新的社会成员的机器。当我们的社会成员发生变化以后,整个社会都会发生根本性的变化。
零距离信息社会需要去中心化服务
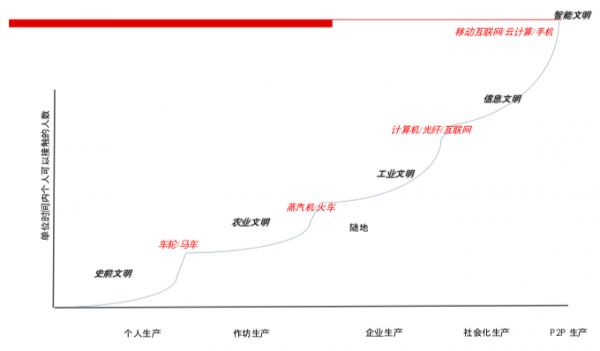 恩格斯认为, 人类发明的对人类文明最有意义的工具是轮子,因为轮子第一次缩短了人与人之间的距离,这是形成一个社会结构的基础。人类文明从史前文明到农业文明,到工业文明,再到信息文明和智能文明,其推动力都是技术发展把人类之间的距离不断地缩短,从火车,飞机,一直到今天互联网把我们紧紧联系在一起,人与人之间的距离完全虚拟化了。由于距离的缩短、信息产业的发展,出现了一个非常有趣的信息社会——零距离信息社会。
恩格斯认为, 人类发明的对人类文明最有意义的工具是轮子,因为轮子第一次缩短了人与人之间的距离,这是形成一个社会结构的基础。人类文明从史前文明到农业文明,到工业文明,再到信息文明和智能文明,其推动力都是技术发展把人类之间的距离不断地缩短,从火车,飞机,一直到今天互联网把我们紧紧联系在一起,人与人之间的距离完全虚拟化了。由于距离的缩短、信息产业的发展,出现了一个非常有趣的信息社会——零距离信息社会。杰里米·里夫金的《零边际成本社会》讲了零距离社会的两大特征:
一是信息产品没有稀缺性,可以无穷生产;
二是边际成本很低很低。
这就导致了工业生产的问题:一方面生产信息产品和很多产品的边际成本很低,几乎为零;另一方面,社会化大产生的模式还是原来的为大众而生产,从而影响了产品的质量。这两方面的矛盾是今天的经济的基本矛盾。要解决基本矛盾的办法就是个性化生产。
未来的生产方式都是面向个人而不是面向社会大众,这样就不需要一个大的中心化的生产结构,去中心化服务就开始了。
这样的去中心化服务我们今天应该很熟悉了, 我们今天许多传统的服务都去中心化了,医院去中心化,零售去中心化,媒体去中心化,金融去中心化,教育去中心化,“三无”的高山大学就是教育去中心化服务的一个实例。
去中心化经济有几个层次,一是无差别服务/商品;二是有整体差别的服务/商品;三是个性化的微服务/商品;四是高度定制化的服务/商品。
层次越高,越需要数据的服务。因为理解每一个人的要求、每一个人的个性、每个人对产品的需求,是大数据的问题。去中心化经济实际上导致了数据资源的社会化。
大数据是社会的自然资源
大数据与人工智能是孪生物,没有大数据就没有人工智能, 而没有人工智能大数据也没有用。人工智能的原料是大数据,大数据是社会的自然资源。
实际上,大数据的重要性英国人早就知道,英国可以说是大数据概念的起源地。早在2000年英国就启动了当时世界上唯一的大数据国家计划——e-Science,即用数据驱动的科学,提出所谓科学研究的“第四范式”。
“第四范式”的提出者是英国e-Science项目主持人托尼·海(Tony Hey)教授,他认为科学研究方法的发展经历了四个驱动模式——观察驱动、理论驱动、模拟驱动、数据驱动。他已经看到整个科学的驱动都是通过普适化的传感技术对现实世界进行数据化。所以,数据成为新的自然资源,是物理世界的孪生体,是物理世界的衡量版。
最重要的是,他在2000年就提出数据产品的概念,把数据这样的自然资源制造成产品。那个时候美国人叫 Service(服务),英国人叫 Data Product(数据产品)。数据产品是个很好的提法,它蕴含了数据成为资源的意思。有了数据资源和数据产品,就引出了很重要的问题,就是数据的所有权。
这个问题是数据经济的一个根本问题,这个问题现在依然是一个大问题,所有权没有很好界定下来,数据经济就无法健康地发展。这个问题的研究美国还不成熟,因为美国界定比较困难,但在欧洲却是研究的如火如荼,一个重要的研究成果就是GDPR(欧盟制定的《通用数据保护条例》)。GDPR就是用来界定和保护数据的所有权。数据归谁所有,谁就会受到保护,因为数据作为私有财产不可侵犯。
有了数据所有权,然后才会有数据的交易,才会有流通和交易的模型、交易的生态环境,而今天大家津津乐道的区块链就是实现这样的数据经济社会的基础设施。
数据是很特殊的资产
个人数据资产是非常有价值的。手机里的数据、病历数据、基因数据都非常有用。界定了数据的所有权后,数据就成了资产。
但是数据是很特殊的一种资产,有很多特点。
第一,数据资产不适用边际效用递减。边际效用递减简单说就是两句话,物以稀为贵,喜新厌旧。一方面,数据是非同质的,是个性化的,其效用不一;另一方面,数据有集聚效应,更多的数据往往意味着更多的效用。
第二,数据资产不适用价格弹性。因为数据的非同质性,对一个独特的数据来说,很难找到替代。
第三,数据资产是非排他私有资产。一份数据不像一杯水,我喝了你就没有了。数据资产不是这样的,你有了,我还可以有,因为数据拷贝是零成本的。这就是区块链研究中常常讲的“双花”问题。“双花”问题是数据不能够作为资产的最大的一个问题。一个东西可以任意拷贝,它就没有价值。解决“双花”问题要用区块链,这是区块链对未来的数据经济贡献最大的地方。
第四,数据资产不适用市场决定的价格机制,因为数据的动态性,非同质性太强。
第五,数据资产的生产与报酬没有关系。数据的生产,往往是生活的一个副产品;由此生产与报酬的关系开始变得模糊。比如你每天的睡眠的状态一躺着就生成数据,这根本就不是工作。
理解了数据资产的这些特质后, 我们就需要发展新的数据经济基础设施使数据资产产生价值,并使交易成为可能,从而,这样数据资产就成为了数据资本。
数据经济需要AI、区块链
那么支持数据经济的基础设施什么呢?我们从数据经济参与者来谈起,数据经济有三个参与者:数据管理者、数据拥有者、数据消费者。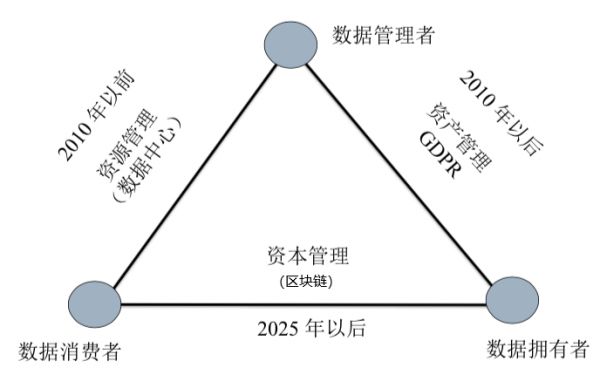 我们来看下上面图, 这个图展示了数据经济的不同基础设施和数据经济参与者之间的关系。
我们来看下上面图, 这个图展示了数据经济的不同基础设施和数据经济参与者之间的关系。互联网经济早期,Facebook、Google出现之前,我们只关心数据管理者和数据消费者,所有的工作都叫做资源管理(数据中心)。数据作为资源,它没有拥有者。
后来,互联网经济产生了很多个人数据,我们开始需要关心数据拥有者。人们认识到Facebook、Google不是个人数据的拥有者,它们只是代管理者,我们需要把代管理者管理起来,使他们尊重数据的所有权,这时,我们的重心就是资产管理。这时候产生了现在的做GDPR,叫资产管理。
数据资产是重要的无形资产,有一个统计,就是如果把国家的数据资产计入经济总量,全球排名是,美国第一,英国第二,中国第三。英国能排第二,很关键的是英国对数据资产的保护。数据经济生态系统思想的重要性就在此。
资产管理忽略掉了数据消费者,管住了数据拥有者和数据管理者以后,数据死掉了,因为数据不能交易、不能交流。所以一味地强调资产管理争议是不够的。
下一步要解决数据拥有者与数据消费者之间的关系,这就是资本管理。在去中心化的数据经济下,数据的交易是以P2P的形式进行的,这时,我们要做的所有事情是要消除数据资产与数据资本之间的瓶颈。
第一个瓶颈要解决数据是数据的可交易性,第二个瓶颈要解决数据价值提取。交易中的 “双花”问题可以靠区块链来解决。价值提取则要靠人工智能。区块链肯定是非常重要的发展方向,它最大的用处是提供资产的交易平台。
区块链不是技术上的创新
区块链由三部分组成:
一是数据化交易物,不仅仅是比特币,还有智能合约等各种可交易的数据化资产。
二是账本的,一个公开的、保证私密性的,不可修改的,去中心化的记账系统。
三是共识机制。
区块链的重要性就是它提供了是一个去中心化的、通用的数据资产管理和交易的基础设施。对于数据资产管理,区块链是低效的,但它却是支持数据交易,从而实现数据资产化的重要保证。
比特币是一个典型的数据化资产,比特币的全球化和去中心化的特点使得它可以作为未来去中心化金融的一个抽象。比特币研究的一个很大的意义就是有可能把经济学变成物理学。物理学有定理,可以用实验数据来证明。由于国家化,中心化,现在经济学的很多定理是无法用实验来证明的。而全球化和去中心化的比特币则可以有真正客观、可以获得的数据来论证经济学的定理,把经济学变成物理学。
智能合约也是典型的数据资产。智能合约的一个重要功能就是把物理拥有权的碎片化,成为可交易的数据交易物, 这就是通证的概念。比如我们可以将一辆车的拥有权,用智能车锁把拥有权分段,形成通证,然后用智能合约来交易这个通证化的拥有权。
所以,区块链的根本价值不在于它的技术创新,区块链在技术上创新性并不突出,但它是非常聪明的,是实现新的去中心的数据经济的基础设施。
人工智能新思想
最后,我们来谈谈人工智能,人工智能发展的基本要素包括计算机算力、大数据算料、模型算法、数据资产化、社会伦理。有两个问题非常重要,一是数据资产化,没有数据就做不出任何人工智能产品。二是一定要强调伦理性,理解智能体的行为和它的社会意义。
人工智能的赋能领域非常宽广,不止机器翻译、人脸识别,可以任我们发挥想象力,不要怀疑机器的力量。人工智能人才的关键不在于编程。算法很重要,但是不要迷信文章,真正有用的算法不到30个,有没有高质量的数据最关键。
人工智能的发展离取代人还很远很远,现在机器学习的基本思想是,把学习的目的表达为一个效用函数,学习的过程就是用数据,通过优化这个效用函数来拟合出一个模型。所以,现在的机器学习实际上是一个优化问题。
这样的机器学习的局限性在于:没有全局的抽象能力,也没有运用知识的能力。机器学习没有常识,无法理解感知的内容,没有可解释性和无法验证决策。所以未来机器学习还有很多的路要走。
不要以为下棋机器赢了,就觉得机器能够做多少决策。下棋的目标是单一的,就是赢这盘棋。但是如果把目标搞复杂一点,未必如此。人做的很多决策,并不是最优化一个最后的效益,还有很多别的因素,所以表达人的学习目标的效用函数是很复杂的,下棋的效用函数是相对简单的。
机器学习大家都认为大数据很重要,实际上第一要脱离大数据的误区,要高效利用数据。
例如两个学生做考题,一个学生要做1000道考题才能得95分,另一个学生只要做5道考题就可以得95分,请问哪个学生聪明?肯定是做5道的,有两种可能,第一他题目选得好,第二他智商高可以举一反三。
机器学习也一样,能在数据里面选取最具有代表性的数据,加上非常好的抽象算法,才是真正的好算法。
第二要努力开拓知识支持下的学习,无论机器学习怎么发展,人类的先验知识永远是重要的学习基础。
我认为,人工智能最大的方向还是要和认知结合起来,把人类的大脑搞清楚。今天我们对大脑的理解,已经有相当大的进展。现在有很多的核磁共振、脑仪器,例如清华大学戴琼海教授做的对大脑的分子级别的动态影像,使我们可以真正理解大脑是怎么活动的。我们实验室也做很多这样的工作,比如脑图解码。我们不仅要读大脑,更重要的是理解大脑工作的真正意义。
人工智能研究的重大难题不是好的学习算法、好的梯度搜索,好的表达方式,而是研究机器行为,包括单机行为、机群行为、人—机行为三个层次的机器行为方式和准则。
机器行为的产生机制不一定仅仅是算法,还要考虑很多其他的因素。其中一个重要的研究是效用函数的定义,怎么样保证效用函数可以准确表达一个社会有利的行为目标?准确表达对于不利行为的限制,通过效用函数优化加上限制项来实现符合伦理的行为?把这么复杂的效用函数表达准确、清楚是非常困难的,所以才提出所有的算法都要有可解释性,都要有可验证性,才能界定它是合理合法的。人工智能的挑战重要的不是机器能做多少,而是知道机器做的对不对!
最后用图灵先生的这句话结束:
我们仅能前瞻不远,但我们却能看到有许多事要去做。
*以下根据郭毅可2019年10月15日在高山大学英国站的分享整理而成。文章内容仅为现场课程十分之一。相关推荐
郭毅可:人工智能的生态与思想
蔚来资本张君毅:如何评价智能化引发的汽车生态乱战?
【链得得独家】数字经济学家刘志毅:Facebook没有突破式创新,也不会挑战传统金融秩序
源码资本曹毅:“四有青年”——下半场的好公司
贝索斯的思想DNA
腾讯投资人刘晓松:天使投资就是寻找有思想的“屌丝”
十分好读 |《人工智能全球格局》:赢了柯洁的AlphaGo,依然算不上人工智能吗?
36氪独家丨小鹏首席科学家郭彦东加入OPPO,将拓展健康、出行和智慧家庭领域
韩寒与郭敬明:人至中年,帝国未竟
360公司副总裁&360游戏集团总裁李海毅:顺应跨端融合趋势,打造游戏生态共同体 | WISE2020超级进化者大会游戏产业革新大会
网址: 郭毅可:人工智能的生态与思想 http://www.xishuta.com/newsview15324.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95228
- 2人类唯一的出路:变成人工智能 21183
- 3报告:抖音海外版下载量突破1 21148
- 4移动办公如何高效?谷歌研究了 20339
- 5人类唯一的出路: 变成人工智 20338
- 62023年起,银行存取款迎来 10336
- 7五一来了,大数据杀熟又想来, 8596
- 8网传比亚迪一员工泄露华为机密 8505
- 9滴滴出行被投诉价格操纵,网约 8215
- 10顶风作案?金山WPS被指套娃 7230



