微软发布史上最大AI模型:170亿参数横扫各种语言建模基准,将用于Office套件
编者按:本文来自微信公众号“量子位”(ID:QbitAI),乾明 发自 凹非寺, 36氪经授权发布
今天(2月11日),微软发布史上最大语言模型,名为Turing-NLG。
170亿参数量,是此前最大的语言模型英伟达“威震天”(Megatron)的两倍,是OpenAI模型GPT-2的10多倍。
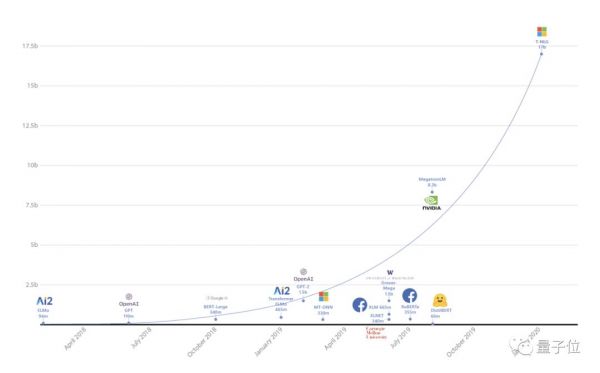
“随着更大的自然语言模型导致更好结果的趋势,微软引入了Turing-NLG,”微软在研究博客中写道。“它在各种语言建模基准方面的表现超过了最先进的水平,并且在许多实际任务的应用上,比如回答问题和摘要生成方面表现都十分优异。”
与此同时,微软研究也发布了另一篇博客文章,介绍了用于分布式训练大型模型的DeepSpeed深度学习库和ZeRO优化技术,并表示如果没有这些突破,Turing-NLG不可能完成。
史上最大语言模型
Turing-NLG,简称T-NLG,是一个基于Transformer的生成语言模型,可以生成单词来完成开放式的文本任务,比如回答问题,提取文档摘要等等。
微软认为,想要在任何情况下,都能使机器像人类一样直接、准确、流畅地做出反应,开发像T-NLG这样的生成模型对解决NLP任务非常重要。
以前,回答问题和提取摘要的系统,主要依赖于从文档中提取现有的内容。虽然可以作为替代答案或摘要,但常常显得不自然或不连贯。
“有了T-NLG,我们可以自然地总结或回答有关个人文件或电子邮件线程的问题,”微软表示。

这背后的逻辑在于:即使训练样本较少,但模型越大,预训练的数据越多样化和全面,它就越能更好地推广到多个下游任务。
所以,微软也认为训练一个大型的集中式多任务模型,并在众多任务之间共享它的能力,比为每个任务单独训练一个新模型更有效。
T-NLG是怎么训练出来的?
训练大型模型的一个常识是:任何超过13亿参数的模型,单靠一个GPU(即使是一个有32GB内存的 GPU)也是不可能训练出来的,因此必须在多个GPU之间并行训练模型,或者将模型分解成多个部分。
微软介绍称,能够训练T-NLG,得益于硬件和软件的突破,一共体现在三个方面:
第一,他们利用NVIDIA DGX-2硬件设置,使用InfiniBand连接,以便GPU之间实现比以前更快的通信。
第二,使用四个英伟达V100 GPU,在英伟达 Megatron-LM框架中应用张量切片分割模型。
第三,使用Deepspeed和ZeRO降低了模型的并行度(从16降低到4) ,将每个节点的批处理大小增加4倍,并且减少了三倍的训练时间。
Deepspeed使得使用更少的GPU训练非常大的模型更有效率,并且它训练的批量大小为512,使用256个 NVIDIA GPU。如果用Megatron-LM 需要1024个 NVIDIA GPU。此外,Deepspeed还与PyTorch兼容。

最终的T-NLG模型中,有78个Transformer层,隐藏大小为4256,有28个注意头。
为了使模型的结果能与Megatron-LM媲美,他们使用了与其相同的超参数和学习时间表进行预训练。与此同时,他们也使用与Megatron-LM相同类型的数据对模型进行训练。
效果达到最先进水平,将用于Office套件
模型预训练完成后,他们也在WikiText-103(越低越好)和LAMBADA(越高越好)数据集上,与英伟达Megatron-LM和OpenAI的GPT-2完整版进行了比较,都达到了最新的水平。
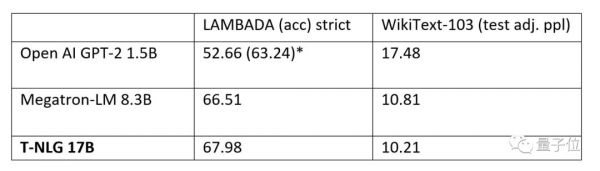
不仅仅是数据集上,微软也公布了T-NLG在具体任务中的表现。
首先是回答问题。其不仅能够使用一个完成的句子回答,还能够在不需要上下文的情况下回答问题,比如下面的这个问题并没有给出更多的信息。在这些情况下,T-NLG能基于预训练中获得的知识来生成一个答案。

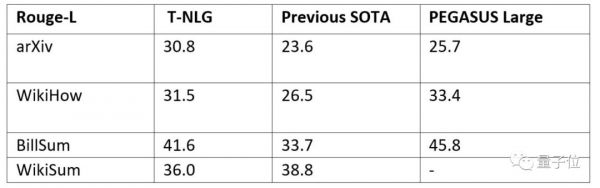
其次是生成摘要。微软表示,为了使 T-NLG 尽可能多用于总结不同类型的文本,他们几乎在所有公开可用的摘要数据集上以多任务的方式完善了T-NLG模型,总计约400万个训练实例。
他们与另一个最新的基于Transformer的语言模型PEGASUS,以及先前最先进的模型进行了比较,ROUGE评分结果如下,基本上实现了超越。
实际效果怎样?
为了秀这个模型的能力,微软用T-NLG模型,给介绍T-NLG的博客文章写了一份摘要:
Turing Natural Language Generation (T-NLG) is a 17 billion parameter language model by Microsoft that outperforms the state of the art on many downstream NLP tasks. We present a demo of the model, including its freeform generation, question answering, and summarization capabilities, to academics for feedback and research purposes. <|endoftext|>
正如摘要中所说的,微软的T-NLG目前并不对外公开。
对于T-NLG的应用潜力,微软说它为其和客户提供了新的机会。
除了通过总结文档和电子邮件来节省用户时间,还可以通过向作者提供写作帮助和回答读者可能提出的关于文档的问题,来增强使用 Microsoft Office 套件的体验,打造更强的聊天机器人等等。
微软表示,他们对新的可能性感到兴奋,将继续提高语言模型的质量。
关于文章中提到的ZeRO & DeepSpeed,如果你有兴趣,可以进一步阅读下微软的官方博客文章,其中DeepSpeed开源了, ZeRO的论文也已经发布:https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/
相关推荐
微软发布史上最大AI模型:170亿参数横扫各种语言建模基准,将用于Office套件
微软设计总监:时隔六年,微软 Office 图标再次更新
谷歌发布世界最大任务型对话数据集SGD,让虚拟助手更智能
性能不打折,内存占用减少90%,Facebook提出极致模型压缩方法Quant-Noise
要啥给啥的写作AI:新闻评论小说都能编,题材风格随便选,真假难辨,16亿参数模型已开源
最前线 | 微软发布IoT解决方案,向边缘侧进一步延伸
三十而立的微软 Office,今天改名了
微软全面拥抱 AI
微软宣布Office 365将更名为Microsoft 365,增加多种功能 | 钛快讯
强大如GPT-3,1750亿参数也搞不定中文?
网址: 微软发布史上最大AI模型:170亿参数横扫各种语言建模基准,将用于Office套件 http://www.xishuta.com/newsview17410.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95228
- 2人类唯一的出路:变成人工智能 21183
- 3报告:抖音海外版下载量突破1 21148
- 4移动办公如何高效?谷歌研究了 20339
- 5人类唯一的出路: 变成人工智 20338
- 62023年起,银行存取款迎来 10336
- 7五一来了,大数据杀熟又想来, 8596
- 8网传比亚迪一员工泄露华为机密 8505
- 9滴滴出行被投诉价格操纵,网约 8215
- 10顶风作案?金山WPS被指套娃 7230



