DeepFakes=假货制造机?一文告诉你深度伪造技术的发展现状
编者按:本文来自微信公众号“AI科技大本营”(ID:rgznai100),36氪经授权发布。
作者 | Kyle Wiggers
翻译 | 天道酬勤
编辑 | Carol

Deepfakes(深度伪造技术)是什么?
「深度伪造技术」是一种利用人工智能将现有图像、音频或视频中的人物替换成其他人的肖像的媒体,这种技术正在迅速发展。这令人很担忧,不仅因为这些假货可能被用来在选举中左右舆论,或将某人卷入犯罪,而且还因为它们已经被滥用来制作演员的色情材料,并欺骗主要的能源生产商。
面对这一新现实,由学术机构、科技公司和非营利组织组成的联盟正在研究开发人工智能产生的误导性媒体的方法。
他们的工作表明,检测工具是一种可行的短期解决方案,但是深度伪造军备竞赛才刚刚开始。
深度伪造文字
人工智能产生的最好的散文比《愤怒的葡萄》更接近《疯狂的图书馆》,但是尖端的语言模型现在可以用人文般的智慧和毅力来写作。旧金山研究公司OpenAI的GPT-2只需几秒钟即可制作出《纽约客》文章或集体讨论游戏场景的文章。
更让人担忧的是, 米德尔伯里国际研究中心恐怖主义、极端主义和反恐中心(CTEC)的研究人员认为,可以利用GPT-2和其他类似的组织来宣传白人至上主义、伊斯兰圣战主义和其他具有威胁性的意识形态。
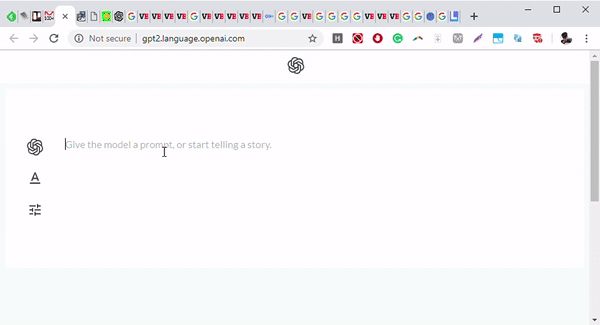
图:AI研究公司OpenAI的训练语言模型GPT-2的前端。 图片来源:OpenAI
为了追求一种可以检测合成内容的系统,华盛顿大学的保罗·G·艾伦计算机科学与工程学院和艾伦人工智能研究所的研究人员开发了Grover,他们声称该算法能够从开源通用抓取语料库编译的测试集中选出92%的深度伪造的书面作品。
该团队将其成功归因于Grover的文案方法,他们说这种方法有助于他们熟悉人工制品和人工智能起源的语言的怪癖。
来自哈佛大学和麻省理工学院—IBM沃森人工智能实验室的一组科学家分别发布了巨型语言模拟测试室,这是一个旨在确定文本是否由人工智能模型编写的网络环境。在给定语义上下文的情况下,它可以预测哪些单词最有可能出现在句子中,本质上就是编写自己的文本。
如果要评估的样本中的单词与前10个、100个或1,000个预测的单词匹配,则指示器分别变为绿色、黄色或红色。实际上,它使用自己的预测文本作为基准来发现人工生成的内容。
深度伪造视频
最先进的视频生成人工智能与自然语言一样强大(并且危险),甚至更强大。由香港初创公司SenseTime、南洋理工大学和中国科学院自动化研究所发表的一篇学术论文详细介绍了一个框架,该框架通过使用音频合成逼真的视频来编辑素材。
首尔Hyperconnect公司的研究人员最近开发了一种工具MarioNETte,该工具可以通过合成因他人的动作而动画化的面部来操纵历史人物、政治家或CEO的面部特征。
然而,即使是最逼真的深度伪造也有一些手工艺品表露出来。网络安全公司Deep Instinct的深度学习小组负责人伊沙伊•罗森博格(Ishai Rosenberg)通过电子邮件告诉VentureBeat::“‘生成系统’生成的‘深度学习’学习视频中实际图像的数据集,你可以向其中添加新图像,然后用新图像生成新视频。”
“结果是,输出视频具有细微的差异,因为由深度伪造人工生成的数据分布和原始源视频中的数据分布发生了变化。这些差异(可以称为“矩阵中的瞥见”)是深度伪造检测器能够区分的。”

上图:使用最新方法制作的两个深度伪造视频 图片来源:SenseTime
去年夏天,加州大学伯克利分校和南加州大学的一个团队训练了一个模型,来寻找精确的“面部动作单位”,即人们面部运动、抽动和表情的数据点,包括他们举起上唇的时间以及皱着眉头时的头部旋转方式——可以识别出90%以上的被操纵视频。
同样,在2018年8月,美国国防高级研究计划局(DARPA)的媒体取证项目的成员对系统进行了测试,这些系统可以从线索中检测出人工智能生成的视频,这些线索包括不自然的眨眼、奇怪的头部运动和奇怪的眼睛颜色等等。
几家初创公司正在将类似的深度伪造视频检测工具商业化。总部位于阿姆斯特丹的深度追踪实验室提供了一套监视产品,旨在对社交媒体、视频托管平台和虚假信息网络上载的深度伪造内容进行分类。
黛莎(Dessa)提出了一些技术,用于改进在经过处理的视频数据集上训练的深度伪造检测器。Truepic于2018年7月为其视频和照片深度伪造检测服务筹集了800万美元的融资。2018年12月,该公司收购了另一个深度伪造的“检测即服务”初创公司Fourandsix,该公司的伪造图像检测器已获得美国国防高级研究计划局的许可。

上图:人工智能系统生成的深度伪造图像
除了开发完全训练有素的系统外,许多公司还发布了语料库,来希望研究界能够开拓新的检测方法。为了加快这种努力,Facebook与亚马逊服务(AWS)、人工智能合作伙伴关系以及来自许多大学的学者一起,率先开展了深度伪造检测挑战赛。挑战赛包括一组视频样本数据集,这些数据集带有标签来指示哪些内容是由人工智能处理的。
作为FaceForensics基准测试的一部分,谷歌于2019年9月发布了一系列深度伪造照片,该基准由慕尼黑工业大学和那不勒斯大学费德里科二世共同创建。最近,来自SenseTime的研究人员与新加坡南洋理工大学合作,设计了DeeperForensics-1.0,这是一种用于人脸伪造检测的数据集,他们声称这是同类数据中最大的。
深度伪造音频
人工智能和机器学习不仅适合视频和文本合成,还可以克隆声音。无数的研究表明,重现人们讲话的韵律只需要一个小的数据集。像Resemble和Lyrebird这样的商业系统仅需要几分钟的音频样本,而百度最新的Deep Voice实现等复杂的模型可以从3.7秒的样本中复制语音。
深度伪造音频检测工具尚未丰富,但解决方案开始出现。
几个月前,Resemble团队发布了一个名为Resemblyzer的开源工具,该工具使用人工智能和机器学习来通过获取语音样本的高级表示并预测它们是真实的还是生成的来检测深度伪造。给定语音的音频文件,它将创建一个数学表示,总结录制的语音的特征。这样一来,开发人员就可以比较两种声音的相似度,也可以在任何给定时刻猜测谁在说话。
2019年1月,作为谷歌新闻计划的一部分,谷歌发布了语料库,其中包含该公司的文字转语音模型所使用的数千个短语。样本取自以68种不同的合成声音所讲的英语文章,并涵盖了各种方言。该语料库适用于ASVspoof 2019的所有参与者,该竞赛旨在促进针对深度伪造语音的对策。
损失惨重
目前还没有检测器能够达到完美的精度,研究人员还没有弄清楚如何确定深度伪造的假冒者身份。Deep Instinct的罗森伯格(Rosenberg)认为,这会加剧散布深度伪造的假冒者的胆识。他说:“即使一个恶意假冒者被抓了,也只有深度伪造本身有被破坏的风险。”“假冒者被抓到的风险很小。因为风险低,所以制造深度伪造几乎没有威慑力。”
罗森伯格的理论得到了深度追踪的一份报告的支持,该报告在2019年6月和7月的最新统计中在线显示了14698个深度伪造视频,在七个月内增长了84%。其中绝大多数(96%)包含以女性为特色的色情内容。
考虑到这些数字,罗森伯格认为,由于深度伪造而蒙受巨大损失的公司应开发并将深度伪造检测技术(他认为类似于反恶意软件和防病毒软件)整合到其产品中。这方面已经有了一些进展;Facebook在1月初宣布,它将使用自动和手动系统的组合来检测深度伪造内容,而Twitter最近建议标记深度伪造,并删除那些可能造成威胁的内容。
当然,深度伪造生成器背后的技术仅仅是工具,它们具有巨大的发展潜力。咨询公司Access Partnership的数据和信任业务负责人Michael Clauser指出,该技术已被用于改善医学诊断和癌症检测,填补绘制宇宙图的空白以及更好地训练自动驾驶系统。因此,他告诫人们不要进行全面行动来阻止发展人工智能。
克劳斯特通过电子邮件对VentureBeat表示:“随着领导者开始将诽谤等现有法律原则应用于新兴的深度伪造案例中,重要的是不要把婴儿和洗澡水一起扔掉。”“最终,围绕使用这种新兴技术的判例法和社会规范还不够成熟到足以在构成合理使用还是滥用的地方划上红线。”
相关推荐
DeepFakes=假货制造机?一文告诉你深度伪造技术的发展现状
DeepFakes天敌来了!伯克利紧急研发“火眼金睛”防伪克星
窥探神秘的Deepfake“军备竞赛”
微软发布最新打击虚假信息工具,可识别深度伪造视频
全球教育机器人深度报告,一文看尽7层产业链12类产品
为AI生成内容“正名”:从“深度伪造”到“深度合成”
破局“眼见为假”: 谁在磨砺刺破Deepfakes之剑?
悬赏1000万美元,打假AI换脸,Facebook发起Deepfakes检测挑战赛
美国国会听证会探讨“深度伪造”风险及对策
换脸已不算事儿,能换整个身体的AI伪造技术马上就来了
网址: DeepFakes=假货制造机?一文告诉你深度伪造技术的发展现状 http://www.xishuta.com/newsview18712.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95273
- 2人类唯一的出路:变成人工智能 21579
- 3报告:抖音海外版下载量突破1 21553
- 4移动办公如何高效?谷歌研究了 20718
- 5人类唯一的出路: 变成人工智 20712
- 62023年起,银行存取款迎来 10377
- 7五一来了,大数据杀熟又想来, 8945
- 8网传比亚迪一员工泄露华为机密 8569
- 9滴滴出行被投诉价格操纵,网约 8567
- 10顶风作案?金山WPS被指套娃 7258



