脑机接口利器:从脑波到文本,只需要一个机器翻译模型
编者按:本文来自微信公众号“AI科技评论”(ID:aitechtalk),36氪经授权发布。
作者 | 贾伟
编辑 | 蒋宝尚

机器翻译真的是万能的,不仅能够写诗、对对联、推导微分方程,还能够读取脑波信息。
昨天,加州大学旧金山分校的Joseph Makin 等人在 Nature Neuroscience上发表了一篇论文,标题为《利用 encoder-decoder 框架,将大脑皮质活动翻译为文本》(Machine translation of cortical activity to text with an encoder–decoder framework)。

这篇论文的工作思路异常简单。他们将脑波到文本的转换视为机器翻译的过程,脑波为输入序列,文本为输出序列。
通过让受试者朗读文本,收集相应脑区的电波,构成训练数据集,然后去训练一个端到端的机器翻译模型。
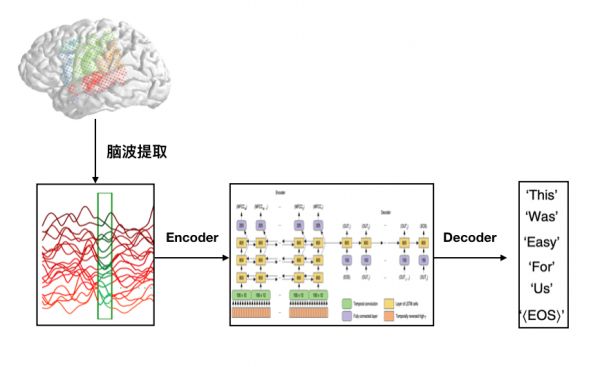
通过这种方式,他们获得了一个模型,这个模型能够将受试者的脑波「准确」、「实时」地转换为句子文本,而错误率仅为3%。
这种创新,无疑是革命性的。
目前一些用于大脑控制打字的脑机接口技术,大多依赖于头部或眼睛的残余运动。以霍金为例,他可以通过手指的运动控制虚拟键盘来打出他想表达的单词。但这种方式一分钟最多也只能打出8个单词。
也有一些尝试将口头语音(或尝试发出的语音)解码为文字,但迄今也仅限于对单音素或单音节的解码,在中等大小的文本(100个单词左右)上错误率往往高达60%以上。
Joseph 等人的这项工作,则直接将脑波几乎无延迟地准确转换为文本,对于瘫痪患者来说,无疑是一大福音。
1 总体思路
如前面所述,作者借用了自然语言处理领域的概念,在自然语言的机器翻译中,是将文本从一种语言翻译到另外一种语言。而脑波到文本,事实上也是类似的一种「翻译」过程。
从概念上讲,这两种场景的目标都是在两种不同表示之间建立映射关系。更具体地说,在这两种情况下,目的都是将任意长度的序列转换为任意长度的另一序列。这里需要重点强调一下「任意」,因为输入和输出序列的长度是变化的,并且彼此之间并不必须有确定性的一一对应关系。
在Joseph 等人的这项工作中,他们尝试一次解码一个句子,这和现在基于深度学习的端到端机器翻译算法类似。
两者相同的地方是,都会映射到相同类型的输出,即一个句子的词序列。不同之处在于,输入,机器翻译的输入是文本,而Joseph等人工作的输入是神经信号——受试者朗读句子,实验人员用高密度脑电图网格(ECoG grids)从参与者的大脑皮层处收集信号。
于是,对神经信号稍加处理后,便可以直接用 seq2seq架构的机器翻译模型进行端到端训练,基本不用进行改动。
在这项工作中,最难的是如何获取足够多的训练数据集。我们知道,机器翻译的数据集可以达到上百万规模,但这个实验中的每一个受试者顶多也就只能提供几千量级的数据。在这种训练数据稀少的背景下,为了充分利用端到端学习的好处,作者使用了一种只包含30~50个独立句子的受限“语言”。
2 模型
在这项研究中,为了收集输入数据,要求参与人员大声朗读句子,观察脑波活动。一组需要朗读的数据是图片描述,大概有30个句子,125个单词,另一组采用MOCHA-TIMIT语料数据库中的数据,以50个句子为一组,最后一组包含60个句子。
一共有四个参与者进行朗读,研究人员只考虑重复朗读三次的句子集,其中一次朗读的数据用于测试,两次用于训练。
参与者在大声朗读的时候,会产生脑电波,给参与人员插上电极之后,研究人员用高密度脑电图网格(ECoG grids)从参与者的大脑皮层处收集信号。
收集的脑电波信号和对应朗读的句子,会作为数据输入到“编码-解码”架构的人工神经网络。
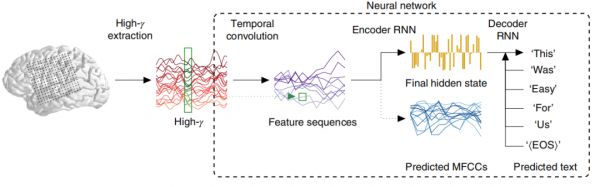
如上图所示,人工神经网络对输入数据进行处理会经过三个阶段:
1、时间卷积:一些类似的特征可能会在脑电信号数据序列的不同点处重现,全连接的前馈神经网络显然无法处理。为了有效学习这种规律,网络以一定的步幅为间隔,对每个间隔应用相同的时间滤波器(temporally brief flter)。
2、编码器循环神经网络:经过时间卷积的处理会产生特征序列,把特征序列输入到编码器循环神经网络里面,然后,神经网络的隐藏层会提供整个序列的高维编码,这个编码与长度无关。
3、解码器循环神经网络:在解码阶段,重点将是高维序列“翻译”成一个单词。这时的循环神经网络会进行初始化,然后对每一步的单词进行预测,当预测结果是end-of-sequence token时,停止解码。
作者所使用的神经网络框架如下图所示:
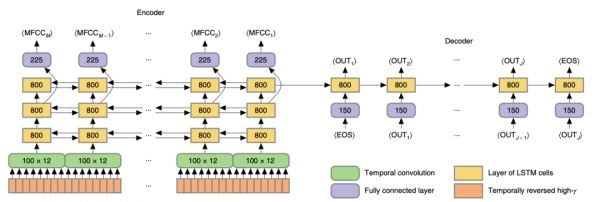
训练整个网络的目标是接近MFCC(梅尔倒谱系数特征),MFCC能够引导神经网络产生良好的序列解码。但是在模型测试阶段,抛弃了MFCC,解码完全依靠解码器神经网络的输出。在模型训练中,随机梯度下降法贯穿训练的整个过程,所有的网络层都应用了dropout。
模型评估用错词率(The Word error rate, WER)量化,WER基本想法就是把正确答案和机器的识别结果排在一起,一个词一个词的对,把多出的词,遗漏的词和错误识别的词统统加在一起,算作错误,然后计算错误的词占实际单词总数的百分比。
经过验证,所有参与者的平均WER为33%,对比当前最先进的语音解码WER的60%,效果较好。
3 实验结果
作者在论文中一共进行了两个实验,一个是采取了类似“控制变量”的方法,看看为何这个模型表现如此优秀,另一个是通过迁移学习改善其他参与者的模型表现。
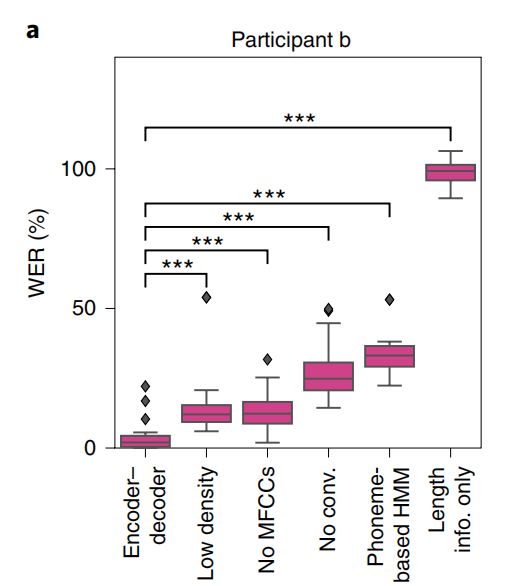
在“控制变量”实验中,作者重新训练网络,上图的第二个框是采用低密度脑图网格数据(lower-density ECoG grids)并进行下采样的性能。另外,作者只留下了1/4个通道,即只用了64个通道,而不是256个通道,此时的错词率比原先高出四倍。这意味着除了高密度脑电图网格,算法也非常重要。
第三个框是没有附加MFCC时的性能,错误率与低密度脑电图网格类似,但优于之前的语音解码尝试。
第四个框是采用全连接网络的结果,对于卷积网络,全连接的错词率比之前高了8倍。但是在实验中,作者发现,用全连接网络造成的错词率可以在高γ信号传递之前进行下采样解决。
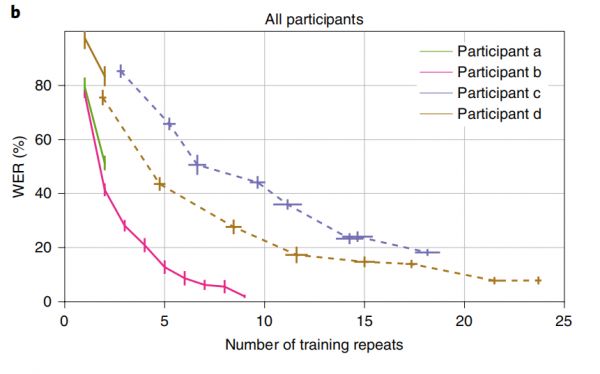
最后,作者对重复实验是否影响错词率进行了量化。研究发现,当至少有15次重复训练时候,错词率可以到25%以下。
如上图所示,当训练次数很少的时候,参与者a和参与者b的解码性能很差,为了解决这个问题,作者尝试了迁移学习。
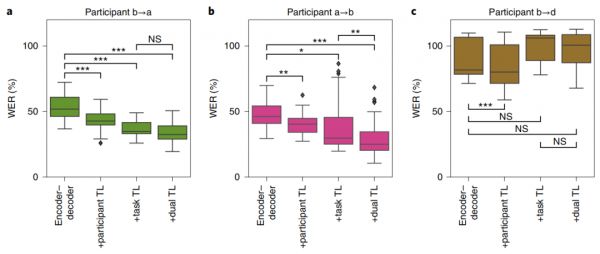
上图 a 中的第一个框用MOCHA-1数据训练的结果,错词率为53%。考虑网络第一次针对参与者b的更丰富的数据集进行预训练时的性能,这种迁移学习能使错词率降低约17%(上图a中的第一个框到第二个框所示)。
作者还考虑了一种组合形式的迁移学习,其中编码器-解码器网络根据参与者b的所有MOCHA-TIMIT数据进行预训练;然后针对参与者a的所有MOCHA-TIMIT数据进行训练,像往常一样在参与者a的MOCHA-1块上进行测试。这种“双重迁移学习”(图a,第四条框)使错词率比基线降低了36%,与任务迁移学习相比有所改善。
那么,改进是否以相反的方向转移,即从参与者a转移到参与者b,显然是可以的,正如上图b所示。
对于在MOCHA-TIMIT数据上表现最差的参与者d,将其余的MOCHAT句子添加到训练集并不能改善结果(如c图所示)。
4 讨论
很明显,这项研究最大的不足之处就是——数据集太小,仅250个单词,30~50个句子。
若想把这种技术扩展到通用自然语言上,则需要探索,到底需要多少数据才足够,以及如何才能获得足够的数据。
事实上,如果能够将脑电图网格(ECoG)长期插入受试者脑中,可用的训练数据量将比本实验(仅收集了半个小时的数据)大几个数量级。在实际应用中会遇到一些情况,有些人已经失去了说话能力,尽管如此,这种方法仍然可以适用,尽管性能会稍有下降。
这里,AI 科技评论还想强调的一点是:机器翻译的本质,就是从一种信息序列映射到另一种信息序列。特别是现在端到端的技术下,只要能够将你的问题换种表述方式,转换为序列到序列的映射问题,然后能收集到足够多的训练数据,那么都可以借用现有的机器翻译技术来做出巨大的改变。
相关推荐
脑机接口利器:从脑波到文本,只需要一个机器翻译模型
脑机接口,到底有多远?
Facebook 十亿美元买脑机接口赛道,国内还有这些公司在做?
投资风口上的“脑机接口”,离“商业着陆”还有多久?
你尽管“动脑”,话交给脑机接口来说
别再羡慕马斯克的脑机接口了,中国强大的脑机接口在这里
最前线丨读心术和隔空打字?华人创业公司展示脑机接口技术新成果
马斯克脑机接口遭质疑:不是新技术,没体现神经解码进展
脑机接口:人类的超能力“迷思”
AI解码脑电波,科幻片里的“读脑术”真的来了
网址: 脑机接口利器:从脑波到文本,只需要一个机器翻译模型 http://www.xishuta.com/newsview20156.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95228
- 2人类唯一的出路:变成人工智能 21183
- 3报告:抖音海外版下载量突破1 21148
- 4移动办公如何高效?谷歌研究了 20339
- 5人类唯一的出路: 变成人工智 20338
- 62023年起,银行存取款迎来 10336
- 7五一来了,大数据杀熟又想来, 8596
- 8网传比亚迪一员工泄露华为机密 8505
- 9滴滴出行被投诉价格操纵,网约 8215
- 10顶风作案?金山WPS被指套娃 7230



