摩尔定律不死,它也未曾凋零
本文来自微信公众号:老石谈芯(ID:laoshi_tanxin),作者:老石,题图来自英特尔
很多世界顶尖的“建筑师”可能是你从未听说过的人,他们设计并创造出了很多你可能从未见过的神奇结构,比如在芯片内部源于沙子的复杂体系。如果你使用手机、电脑,或者通过互联网收发信息,那么你就无时无刻不在受益于这些建筑师们的伟大工作。
Jim Keller就是这群“建筑师”里的一员。作为微处理器领域的传奇人物,他现任英特尔资深副总裁,兼任硅工程事业部(Silicon Engineering Group)的总经理。在此之前,他曾任职DEC、AMD、博通、苹果、特斯拉等公司,担任工程副总裁或首席架构师等工作。
在他几十年的职业生涯中,他领导设计了多种x86和ARM的处理器架构,包括AMD的K7、K8、K12和Zen,苹果用于iPhone4和iPad的A4、A5移动处理器,特斯拉的自动驾驶处理器,等等。此外,他还是x86-64指令集的作者之一。
不久前,Jim Keller做客MIT的网红学者Lex Fridman的播客节目,并分享了自己对于摩尔定律、计算机体系结构、人工智能等技术问题的见解与思考。两人的对谈天马行空,并不拘泥于某个具体技术或领域,而是由某个观点出发,讨论技术背后的驱动因素,并对芯片与人工智能产业的发展和变革做了深入剖析,听来让人受益匪浅。

Lex Fridman,图片来自他的Twitter
本文对Jim Keller的主要观点进行了整理和采编,主要介绍了Jim Keller对摩尔定律、计算机架构、未来计算机技术的发展趋势等。
下文中的“我”,均指的是Jim Keller。
什么是微处理器、什么是微架构、什么是指令集
对于计算机而言,它有着比较明确的设计层级划分,这也是这门科学的特殊魅力之一。原子位于最底层,对原子进行有序排列后,就会得到诸如硅或金属等材料,于是我们可以用这些材料制作晶体管。
在往上,我们可以使用晶体管组成逻辑门,然后再构建逻辑单元,比如加法器、乘法器、或者指令解码器等等。有了这些逻辑单元,我们就能将它们组合成更加复杂的处理单元。在现代处理器中,大概由10到20个这样的处理单元组成。

图片来自罗彻斯特理工RIT
当这些处理单元组合在一起,就可以运行计算机程序了,而这些程序也有着很多抽象层,比如从最底层的指令集,到汇编语言,再到C、C++、Java、JavaScript等等。而所有的这些也构成了从原子到数据中心的抽象层次。
在这个意义上,当人们设计计算机时,首先都要对设计目标有着明确认识。在当前,对计算机的设计目标有着一系列的衡量指标,比如它的运行速度等等。在一个设计团队中,可能有着数千人,他们分别负责计算机设计的不同领域和不同方面。对于我个人来说,我对自己在这个团队中负责哪个方面的工作并不是特别在意。
指令集就是用来编码计算机的一些最基本的操作,比如加法、乘法、存储、分支等。事实上,在过去很长的一段时间里,包括x86和ARM在内的各类处理器的指令集是相当稳定的。因此,目前在领域里并没有太多有趣的工作。
对于一段程序,大概有90%的代码都基于25个最基本的微指令,而这些微指令都已经十分稳定和成熟了。拿英特尔举例,它的x86架构自发明至今已经有大概25年了。基于我们很久之前定义的一些基本原则,它至今都工作的不错。
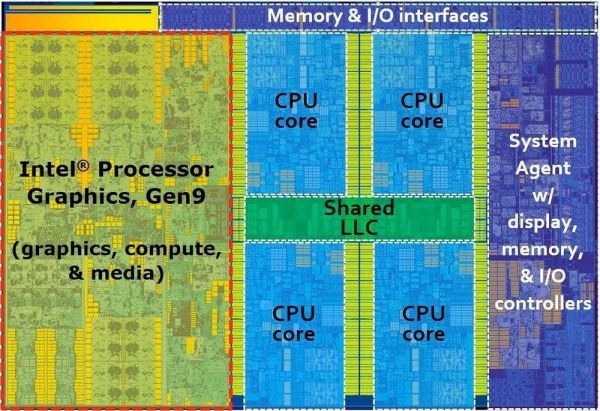
Skylake芯片布局图,图片来自TechPowerUp
以前,计算机的工作方式是取指令,然后顺序执行这些指令。对于现代计算机而言,它的工作方式是取大量指令,比如500条指令,然后寻找并构建这些指令的依赖图,然后在独立的执行单元里分别执行这个依赖图的子集。
很多人说计算机设计应该简洁和干净,但事实上市面上销售的既“简洁”又“干净”的计算机数量基本为零。在当前的各种计算机中,小到手机,大到数据中心,都是通过大量取指、并计算依赖图的方式进行计算的。
现代计算机基本都支持深度乱序执行,它们有着一系列机制负责记录和追踪哪些操作即将结束或可能会结束。但为了快速运行,计算机必须大量取指,并从中寻找可能的并行性。
想象我们看一本书,书里有很多句子和段落,它们共同组成了书的内容。而上面介绍的那种计算机设计方法,就好比尝试打乱句子或者段落的排列顺序,而不影响它们所表达的内容。比如,在介绍一个人的时候,你可以说他是高富帅,但这几点的顺序可以任意排列。你也可以说那个很高的人穿着一件红色的衣服,而此时这句话里就有了依赖关系。
我所说的计算机,包括CPU和GPU。对于CPU,它有着很窄的并行度,这根本上是由它顺序执行的架构所决定,这也和人的思考方式相同,我将其称为“串行叙事(serial narrative)”。
而对于GPU,它的单个处理单元负责处理一个像素点,但它有着上百万个这样的单元。当你看一幅图或一帧画面时,你并不会在意计算机先处理哪个像素点。因此我将其称为“天生并行(given parallelism)”。而它也可以看成是串行叙事的大量集合。
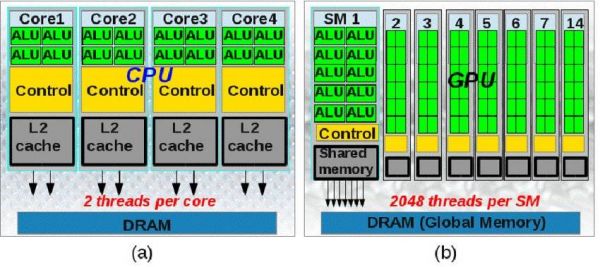
CPU与GPU的架构对比,图片来自网络
在现代计算机中,除了对并行性的探究之外,对分支的预测也是非常重要的。平均来说,每六条指令中就有一条分支语句,而目前人们可以做到远超过90%的预测正确性。
在20年前,我们做分支预测时会直接记录上一次的预测结果,并预测这一次仍将重复这个分支,而这种简单的预测方法可以达到85%的正确性。之后,有人提出采用若干位存储预测结果,并使用一个计数器对之前的预测结果进行统计。如果之前走了一个分支,则计数加一,如果走了另一个分支,则计数减一,诸如此类。所以如果当这个计数器大于0,则预测第一个分支,如果小于0则预测另一个分支。这种预测方法将正确性提高到了92%。然后人们认识到,对于某个分支节点的判断,很多时候还取决于之前的程序是如何执行的,因此这又进一步提升了预测的准确性。
不过,这些都不是现代计算机做分支判断的方法。现代计算机中采用了类似神经网络的方法,简单来说,它考虑了所有的运行过程,并对这些运行过程进行了不同的深度模式识别,并综合这些结果得到分支预测的答案。事实上,在现代计算机里还有一个小型的超级计算机,专门用来计算这些分支和预测。
如果我们还使用上面的计数器的方法做分支预测,为了达到85%的正确率我们需要上千位的计数器,而为了达到99%的正确率我们则需要上千万位。也就是说,为了取得线性的预测正确性提升,需要付出的代价则是指数级的。
然而,很多时候并不需要做到100%的预测正确性,因为有可能不同分支接下来要运行的程序和这些分支并没有关系。比如在看书的时候,有时候段与段之间的联系并不是非常紧密,如果有一段没读懂,也并不会影响后面的阅读。
人脑与计算机的异同
我个人认为,由于目前人们并没有真正了解人类大脑是如何工作的,所以很难将人脑与计算机做直接的比较。不过对于计算机来说,通常来讲它由两个主要部分组成,一个是存储器,一个是计算器。到目前为止,几乎所有的计算机架构的工作机理,都是从存储器中拿数据,通过计算单元进行计算,然后将结果写回存储器。
对于人脑来说,神经元通过各种方式进行连接,它们可以是局部互联的,也可以是全局互联。而数据和信息则通过类似于分布式的方法进行保存。基于此,研究人员构建了所谓的人工神经网络,并提出了很多对应的数学理论对其进行支撑。但这种结构和人脑的实际结构还是有着很大的区别。
计算机系统的确定性
如果你在CPU上运行一段C语言程序,那么每次你都会得到一样的运行结果。但对于现在的AI应用来说,其中的神经网络采用了很低精度的数据表示,而且输入数据也有着极大的噪声。在这种情况下,何必追求完全正确且精确的计算呢?
人们通过研究证明,当允许一定程度的误差时,很多算法可以在更短的时间内完成计算,也从而带来功耗的降低和系统性能的提升。
另一方面,在诸如HPC等的很多应用中,如果同一个计算的每次结果都不相同,那也是不可接受的。而且,如果此时计算结果错误,往往很难确定究竟是算法错误还是计算机制错误。因此,在计算机系统的确定性与随机性之间,人们需要做仔细的权衡。
再进一步,即使每次运行结果都相同,也不代表在计算机中执行了相同的计算、或使用了相同的数据通路。事实上,对于很多在现代计算机中运行的程序来说,运行一百遍会得到相同的结果,但每一次运算在计算机里面运行的顺序、采用的计算单元、涉及的硬件结构等等都不尽相同。
计算机架构应该每5年推倒重来
当设计或改进计算机架构的时候,人们容易陷入这样的误区。比如,有人提出需求说希望计算机比现在运行的要更快10%,于是架构师就开始看哪里可以增加存储器、哪里可以增加运算单元、亦或是增加数据总线宽度等等。
渐渐地你会发现,每个运算单元都会变得越来越复杂,系统性能也逐渐到达瓶颈。也就是说,不管你再增加多少存储、增加多少运算单元、增加多少总线宽度,计算机的性能都无法提升更多了。
这时,聪明的架构师会认识到,性能瓶颈是由之前的系统划分、以及这些复杂运算单元的相互耦合造成的。于是,他们会对系统进行重构。这样的结果,是系统性能得到进一步提升,然后每个计算单元的复杂性也会大幅下降。
我认为,像这样的系统级重构,每三到五年应该来一次。也就是说,如果你想从根本上提升计算机架构,至少每隔五年需要重新开始进行设计。
20多年前,我是64位x86指令集的最早设计者之一。尽管指令集没有发生太多有趣的改变,但基于这些指令集的x86架构在这些年间的变化巨大。英特尔和AMD都有很多各自的架构出现。然而,目前我说的这些根本性重构基本是10年一次,而我希望是至少五年一次。
对计算机结构的重新设计会带来两个问题。对于需要每个季度发布业绩的团队来说,他们往往对这种系统级重构畏手畏脚。然而对于有长远目标的团队来说,重构时带来的短期风险也会影响他们达成长期目标。
因此,一个常见的方式是同时做多个项目,这样你可以在优化已有设计的时候,同时开发全新的架构。
那些市场部的人经常喜欢向人们保证,新的计算机架构比前一代的每个方面都更快更好。事实上,一个工程师会告诉你,一般来说新的架构会更好,但由于性能曲线的存在,会有比前一代更慢的产品,而这也有可能对客户造成影响。
摩尔定律不死
戈登·摩尔对摩尔定律的表述大概是,晶体管数量每两年会翻倍。我对摩尔定律的理解是,计算机的性能每2到3年提高一倍。这项表述在过去的若干年里都相当正确。近年来,人们引入了所谓的“收缩因子”(shrinking factor),它大概是0.6左右。也就是说,每2到3年的性能提升从1除以0.5变成了1除以0.6。
我从事计算机设计已经有40年了,一开始人们说摩尔定律在接下来的10到15年会死,我当时还信了。10年之后人们又说过10到15年摩尔定律将死,然后几年后又成了5年后会死,过了几年又成了10年,诸如此类。后来,我就不再关心摩尔定律什么时候会真正失效了。
然后我加入了英特尔,在这里也有人说摩尔定律将死,而这让我很无语,因为英特尔正是代表摩尔定律本身的公司。对于我来说,摩尔定律将死就是一个伪命题,这和担心某天我们会缺少食物、缺少空气等等一样。

很多人认为摩尔定律代表的不过是晶体管变得越来越小,但实际上摩尔定律代表的是推动这一变化背后的千千万万个技术创新。对于某个技术来说,它会随着时代的演进而逐渐落伍,但大量这样的技术创新结合在一起,就能推动整个领域不断向前。
以前,晶体管的长宽高大约各是1000个原子,现在晶体管的尺寸变成了长宽高各10个原子,因此尺寸缩小了一百万倍。现在的技术允许人们直接对原子进行排列,这理论上会得到更小的晶体管。但在实际生产中,你是无法对10的23次方个原子一一排列的。因此,科学家们在物理、化学、材料等多个领域进行了很多创新,使得我们能稳定地制造高良率的半导体器件,而这些创新也是摩尔定律背后的根本推动力量。
作为计算机架构师来说,我们需要做的是考虑如何利用这些不断增加的晶体管,并基于此设计更高效的计算机架构。我的老朋友Raja Koduri曾说过,晶体管尺寸每缩小10倍,就会衍生出一种全新的计算模式。他也将现在的计算模式分成了标量计算、向量计算、矩阵计算和空间计算四类,分别对应基于CPU、GPU、AI ASIC和FPGA的计算。同时,我们也要考虑很多制约因素,比如人本身不会变得更聪明,而且团队的规模不会不断增长。以前我们会使用更快的计算机来帮助我们设计计算机本身,但现在这种方式已经不再有效,我们也因此需要对设计软件进行不断的重构和更新。

4种计算模式,图片来自英特尔
结语
科技的发展离不开大师的推动。作为从业者,我们应该高兴生于这个风起云涌的年代,因为这里随处充满了无穷的机遇和挑战。作为普通人,我们也应该高兴生活在这个时代,因为能够享受科技的发展为生活带来的无尽便利。
本文来自微信公众号:老石谈芯(ID:laoshi_tanxin),作者:老石
网址: 摩尔定律不死,它也未曾凋零 http://www.xishuta.com/newsview21349.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95067
- 2人类唯一的出路:变成人工智能 20174
- 3报告:抖音海外版下载量突破1 19974
- 4移动办公如何高效?谷歌研究了 19396
- 5人类唯一的出路: 变成人工智 19282
- 62023年起,银行存取款迎来 10229
- 7网传比亚迪一员工泄露华为机密 8346
- 8五一来了,大数据杀熟又想来, 7727
- 9滴滴出行被投诉价格操纵,网约 7350
- 10顶风作案?金山WPS被指套娃 7158



