浙大提出会打德扑的“自我博弈”AI,还会玩射击游戏

文章选自arXiv,作者:Li Zhang、Wei Wang、Shijian Li、Gang Pan,机器之心编译。
人工智能已在围棋这样的完美信息游戏上实现了远超人类的水平,但在信息未完全披露的多人对战游戏上还无法战胜人类。近年来,OpenAI 和 DeepMind 在 DOTA2 和星际争霸 2 上的尝试都难言成功。近日,来自浙江大学的研究人员提出了一种新方法,结合蒙特卡洛树搜索和 NFSP,大大提高了在信息不完整的大规模零和游戏上的表现。
面对信息不完整的环境,浙大的研究人员提出了异步神经虚拟自我对弈(ANFSP)方法,让 AI 学会在多个虚拟环境中进行“自我博弈”,从而生成最优决策。他们的方法在德州扑克和多人 FPS 射击游戏中均取得了不错表现。
正文
随着深度强化学习的快速发展,AI 已经在围棋等信息完整的游戏中战胜了人类专业玩家。然而,“星际争霸”等信息不完整游戏的研究还没有取得同样的进展。这类研究的一大问题是,它们很少从理论和量化的角度考虑对其训练和结果进行评估,因此效果难以保证。
博弈论是研究现实世界竞赛中人类行为模式的基石。该理论主要研究智能体如何通过竞争与合作实现其利益最大化并度量决策的质量。它已经成为计算机科学中一个颇具吸引力的研究任务。名为“算法博弈论”的交互研究课题已经确立,并随着人工智能的发展受到越来越多的关注。对于交易、交通管理等现实世界中的复杂问题,计算维度会急剧增加,因此有必要利用算法和人工智能的思想使其在实践中发挥作用,这也是该研究的主要动机之一。
在博弈论中,纳什均衡是博弈的一个最优解决方案,即没有人可以通过缓和自己的策略获得额外收益。虚拟对弈(Fictitious Play)是求解正规博弈中纳什均衡的一种传统算法。虚拟对弈玩家反复根据对手的平均策略做出最佳反应。玩家的平均策略将收敛到纳什均衡。Heinrich 等人提出了广泛的虚拟对弈(Extensive Fictitious Play),将虚拟对弈的概念扩展到了扩展式博弈。然而,状态在每个树节点中都以查找表的形式表示,因此(类似状态的)泛化训练是不切实际的,而且平均策略的更新需要遍历整个游戏树,这就给大型游戏带来了维数灾难。
虚拟自我对弈(Fictitious Self-Play,FSP)通过引入基于样本的机器学习方法解决这些问题。对最佳反应的逼近是通过强化学习学到的,平均策略的更新是通过基于样本的监督学习进行的。但为了提高采样效率,智能体之间的交互由元控制器协调,并且与学习是异步的。
Heinrich 和 Silver 介绍了神经虚拟自我对弈(NFSP),将 FSP 与神经网络函数近似结合起来。一个玩家由 Q-学习网络和监督式学习网络组成。该算法通过贪婪深度Q学习(greedy deep Q-learning)计算一个“最佳反应”,通过对智能体历史行为的监督学习计算平均策略。它通过引入预期动态来解决协调问题——玩家根据它们的平均策略和最佳反应展开行动。这是第一个在不完全博弈中不需要任何先验知识就能学习近似纳什均衡的端到端强化学习方法。
然而,由于对手策略的复杂性和深度 Q 网络在离线模式下学习的特点,NFSP 在搜索空间和搜索深度规模较大的游戏中表现较差。本文提出了蒙特卡洛神经虚拟自我对弈(Monte Carlo Neural Fictitious Self Play,MC-NFSP),该算法结合了 NFSP 与蒙特卡洛树搜索(Monte Carlo Tree Search)。研究人员在双方零和的棋牌游戏中评估了该方法。实验表明,在奥赛罗棋中,MC-NFSP 将收敛到近似纳什均衡,但 NFSP 无法做到。
另一个缺点是在 NFSP 中,最佳反应依赖于深度 Q-学习的计算,这需要很长时间的计算直到收敛。在本文中,研究人员提出了异步神经虚拟自我对弈(ANFSP)方法,使用并行的 actor learner 来稳定和加速训练。多个玩家并行进行决策。玩家分享 Q 学习网络和监督学习网络,在 Q 学习中累积多个步骤的梯度,并在监督学习中计算小批量的梯度。与 NFSP 相比,这减少了数据存储所需的内存。研究人员在双人零和扑克游戏中评估了其方法。实验表明,与 NFSP 相比,ANFSP 可以更加稳定和快速地接近近似纳什均衡。
为了展示 MC-NFSP 和 ANFSP 技术在复杂游戏中的优势,浙大研究人员还评估了算法在多人 FPS 对战游戏的有效性,其中 AI 智能体队伍和人类组成的队伍进行了比赛,新提出的系统提供了良好的策略和控制,帮助 AI 战胜了人类。
神经虚拟自我对弈
虚拟对弈(FP)是根据自我对弈学习纳什均衡的经典博弈论模型。在每次迭代的时候,玩家队伍根据对方的平均策略做出最佳回应,并更新其平均策略。在特定的游戏场景(如零和游戏)中,玩家在虚拟对弈中的平均策略可以达到纳什均衡。因为 FP 主要是针对正规博弈,Heinrish 等人将 FP 扩展为虚拟自我对弈,FSP 致力于遍历游戏扩展形式的游戏树,有可能在更大规模的游戏中找到纳什均衡。但是 FSP 方法需要玩家和对手遵循动作顺序,因此它不适合信息不完整的游戏。
玩家和对手需要遵循动作顺序的要求使得 FSP 不适用于信息不完整的游戏。神经虚拟自我对弈(NFSP)是一个在信息不完整的游戏上学习近似纳什均衡的模型。该模型结合了虚拟博弈和深度学习。在每一步,玩家会选择混合使用最佳反应和平均策略。玩家通过深度 Q 学习接近最佳反应,并通过监督学习更新平均策略。只有当玩家根据最佳反应决定动作时,状态-动作对(St, at)会被存储在监督学习记忆中。
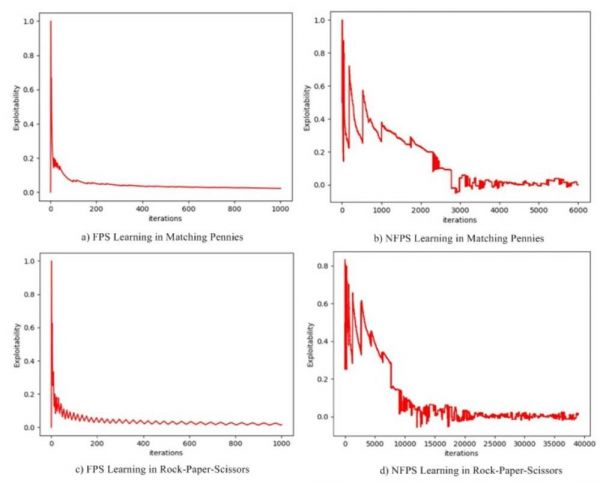
图 1:FSP 和 NFSP 的训练效率
蒙特卡洛神经虚拟自我对弈(MC-NFSP)
该算法利用两种神经网络:蒙特卡洛树搜索的策略-估值网络(policy-value network)(如最佳反应网络,bestresponse network)和监督学习的策略网络(如平均策略网络)。最佳反应网络如图 2 所示。神经网络的输入是边界状态。策略-估值网络有两种输出:策略 p(当前状态到动作概率的映射)和估值 v(指定状态的预测值)。估值范围为“0,1”,其中输掉比赛的对应估值 0,赢得比赛的对应估值 1。在浙大研究人员提出的网络中,relu 激活函数用于卷积层;dropout 用于全连接层以减少过拟合;softmax 用于策略概率。策略网络几乎与最佳反应网络相同,但前者仅输出策略 p 0(不会输出估值),而这也是玩家的平均策略。
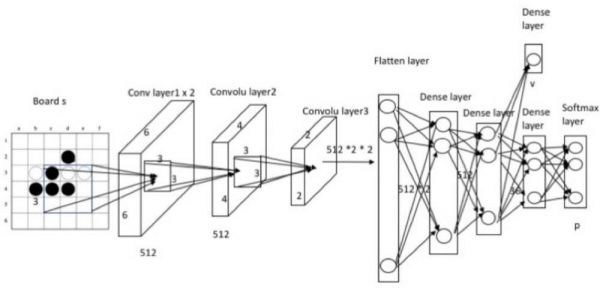
图 2:MCTS 的最佳反应网络
实验
浙大研究人员在改进版无限制州扑克(Leduc Hold'em)中对 ANFSP 和 NFSP 进行比较。为了简化计算,浙大研究人员在无限制德州扑克中将每轮的最大赌注大小限制为 2。实验研究了改进版无限制德州扑克中 ANFSP 对纳什均衡的收敛性,并以学得策略的可利用性作为比较标准。
图 5 显示在改进版无限制德州扑克中 ANFSP 接近纳什均衡。可利用性持续降低,并在 140w 个游戏片段后稳定在 0.64 左右。训练时间约 2 小时。
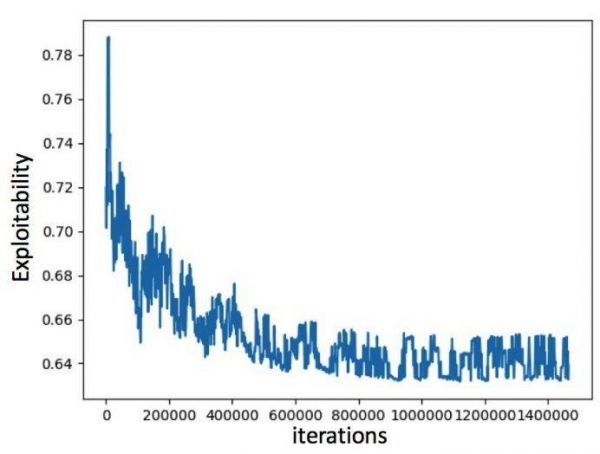
图 5:ANFSP 在改进版无限制德扑中的可利用性
在第一人称射击游戏(FPS)中的评估
为了在信息不完整的复杂游戏中评估本文算法的有效性,研究人员在一个 FPS 游戏上训练了该算法,并且让它与人类对战。本次实验中使用的 FPS 平台是由浙大研究人员设计的。游戏场景是两个队伍(10 VS 10)的攻防对抗。在训练过程中,一方是 MC-NFSP,另一方是由上千场人类游戏(SL-Human)训练的记忆。该实验在固定的封闭式 255 x 255 正方形地图上进行。整个地图被分为 12 x 12 个区域,每个区域有一个 20 x 20 的正方形。

图 7:FPS 游戏环境
与本文之前的研究不同,这两个网络是同时为外部队伍和内部队伍构建和训练的。图 8 显示了外部队伍的训练结果(内部队伍的训练结果与此类似)。从图中不难看出,训练收敛得非常快(少于 150 个片段,每个片段有 5 场游戏)。外部队伍对战 SL-Human 的胜率提高了 80%,而训练损失接近 0。
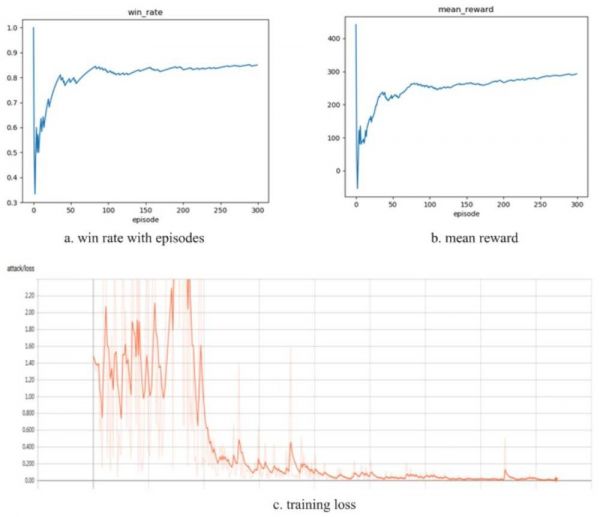
图 8:在 FPS 游戏上的评估结果
相关论文
Monte Carlo Neural Fictitious Self-Play: Achieve Approximate Nash equilibrium of Imperfect-Information Games

论文地址:https://arxiv.org/abs/1903.09569
摘要:人工智能领域的研究人员已经用 AI 在信息完整的大规模游戏上达到了人类水准,但要在信息不完整的大规模游戏(即战争游戏、足球教练或商业策略游戏)上实现最优结果(即近似纳什均衡)仍是一大挑战。神经虚拟自我对弈(NFSP)算法可以通过自我对弈,在没有先验领域知识的情况下有效学习信息不完整游戏的近似纳什均衡。但是,它依赖于深度 Q 网络,但这种网络是离线的而且很难融入对手策略不断变化的在线游戏,因此深度 Q 网络无法在游戏中用大规模搜索和深度搜索来达到近似纳什均衡。本文中,我们提出了蒙特卡洛神经虚拟自我对弈(MC-NFSP)算法,该方法结合了蒙特卡洛树搜索和 NFSP,大大提高了模型在信息不完整的大规模零和游戏中的表现。实验证明,该算法可以利用大规模深度搜索达到 NFSP 无法实现的近似纳什均衡。此外,我们开发了异步神经虚拟自我对弈(ANFSP)算法,该算法使用异步架构和并行架构来收集游戏经验。在实验中,我们发现并行 actor-learner 能够进一步加速和稳定训练。
相关推荐
浙大提出会打德扑的“自我博弈”AI,还会玩射击游戏
AI赌神超进化:德扑六人局击溃世界冠军
第三代AI赌神:在六人桌德扑中胜过5个人类顶尖高手
下围棋、打德扑算什么?AI可能很快就要学会打麻将了
AI玩麻将,6人德州扑克成新赌神?
最前线 | “开悟AI+游戏高校大赛”启动,AI为何要学打王者荣耀?
微软麻将 AI 论文发布,首次公开技术细节
亚马逊推出的射击游戏Crucible,将刺激产生更多Prime会员
甜过初恋!浙大博士用200个西瓜130页论文,教你用机器学习科学挑瓜
「王者荣耀」谈未来游戏发展:AI 已参与,云游戏还在探索 | 潮科技2020. Ask Me Anything
网址: 浙大提出会打德扑的“自我博弈”AI,还会玩射击游戏 http://www.xishuta.com/newsview2164.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95228
- 2人类唯一的出路:变成人工智能 21183
- 3报告:抖音海外版下载量突破1 21148
- 4移动办公如何高效?谷歌研究了 20339
- 5人类唯一的出路: 变成人工智 20338
- 62023年起,银行存取款迎来 10336
- 7五一来了,大数据杀熟又想来, 8596
- 8网传比亚迪一员工泄露华为机密 8505
- 9滴滴出行被投诉价格操纵,网约 8215
- 10顶风作案?金山WPS被指套娃 7230



