换脸新潮流:BIGO风靡全球的人脸风格迁移技术
引
1974年,我国的考古学家在陕西省西安市发掘出了兵马俑,并被其神态各异惟妙惟肖的面部表情所震撼。同年,一篇名为《A Parametric Model for Human Faces》论文迈出了人脸属性编辑这一领域的第一步。而半个世纪后的今天,BIGO自主研发的FaceMagic的换脸技术让你随心所欲地化身为兵马俑,世界名画,或者电影里的超级英雄, 产品一推出即风靡全球。
BIGO为了把这项创新技术带给全球用户,研发人员克服了各种挑战。技术挑战主要来源于三个方面:第一是人脸特征迁移技术,我们创新性地尝试把风格迁移的思路用于人脸特征迁移中,克服了当时主流的deep fake、 3D方案等技术的不足。 第二是全球化问题,因为BIGO用户来源于全球各地,为了解决不同人种的肤色、五官结构的差异问题,我们构建了千万量级的全球化的人脸数据集,极大地涵盖肤色、性别、年龄等差异性,力求把全球每一位用户的效果做到最佳 。第三是多属性,多场景的效果优化,我们在不断优化网络结构的同时尝试人脸属性、人脸姿态等约束,并大力提升大规模数据的训练效率,充分挖掘数据的多样性特征,把换脸效果做到更加鲁棒、真实、自然。FaceMagic仍在吸引越来越多人的参与,自上线以来,全球生产总量接近1亿。功能推出后,每天有超过百万级的内容生产量。
背景
人脸属性编辑是计算机视觉领域的一项重要技术,广泛用于内容生产,电影制作,娱乐视频中。早期的人脸属性编辑主要集中在人脸的表情上,比如通过修改张嘴或者闭眼来体现人的喜怒哀乐。随着算力的提升,这项技术随后便升华为即时的表情编辑或迁移,也就是将一张脸的表情作为输入,来控制另一张脸的表情作为输出,当下我们看到的三维动画或者虚拟偶像都在广泛地利用这项技术。
然而仅仅换个表情显然已经跟不上科研人员的脑洞,Volker 一行人在论文《Exchanging faces in images》[1]中首次提出了在自然图像中置换人脸的概念。文章中使用了一种较为原始的3D模型方案来粗估姿态与光线,并将目标人脸替换至源人脸上。这项技术由于需要人工参与标定关键点,主要被应用于图像编辑等工作。在漫长的学术发展过程中,换脸技术发生了天翻地覆的变化,逐渐衍生出来了基于3D脸部建模,以及对抗生成网络(GAN) [2]的两个派系。
3D脸部建模的方案比较直观,即先对源图片和目标图片进行关键点检测并进行3D建模,然后提取目标图片中的身份信息(ID)替换源图片中的相应部分。Dmitri Bitouk et al.[3]针对[1]中需要进行人工参与,同时也不能处理表情的问题,提出了一个全新的方案,可以解决自动化以及表情的问题。而近代通过3D建模来实现换脸的始祖,Face2Face [4]则通过拟合一个3DMM[5]模型来进一步迁移表情。作为第一个能实时进行面部转换的模型,Face2Face的准确率和真实度树立了业界标杆 。随后的一些研究也多基于此,对生成人脸的自然度进行强化,例如Suwajanakorn et al.[6]对嘴部的模型进行修正,使得嘴部的动作更加自然。Nirkin et al.[7]结合脸部分割,基于一个固定的三维人脸来进行换脸,避免拟合三维人脸形状。这些方法虽然能取得一定的换脸效果,但是要么计算量太大,要么就是生成换脸后的图片依旧不自然,且很难处理遮挡等问题。
近年来,随着大规模的GPGPU算力的出现,基于GAN的换脸方案异军突起,一举击破了基于传统3D换脸方案的大本营。这个突破首先出现在Pix2pixHD [8]中,Ting-Chun等人使用了一个多尺度的cGAN结构进行图片对图片的变化,例如给定一个脸部的轮廓信息,cGAN则能将其转变成一个真实人脸。紧接着GANimation[9] 提出一个双分支生成器来解决人脸表情的问题,其中一个分支通过回归注意力图来控制表情,另一个分支则提供背景和光线信息。GANnotation [10]则在添加约束条件的道路上更进一步,通过约束人脸关键点来驱动生成对应的人脸。除此以外,研究者们也在尝试着与传统方案结合,亦或通过先验知识来指导GAN的生成质量。Kim等人在 Deep video portraits [11] 结合了传统3D与GAN的技术来进行人脸的生成;RSGAN [12]提出一种解耦脸部和头发的方法来换脸;FSGAN [13]通过结合脸部分割来评估遮挡区域,在一定程度上解决了换脸当中的遮挡问题。基于GAN的方法生成的换脸图片相比3D方法更加真实自然,但是很难产生高清的换脸效果,另外源图片姿态比较大时很难兼顾姿态的一致性和换脸的ID迁移能力。
BIGO的算法团队经过探索,提出了基于风格迁移+ID注入的FaceMagic方案,在生成高清自然人脸的同时能够保持人脸姿态、属性一致。目前FaceMagic已在线上运营,每日用户使用量过百万级。
风格迁移的风起
这一切要从风格迁移(Neural Style Transfer)的研究脉络讲起。2016年ECCV的一篇《Image Style Transfer Using Convolutional Neural Networks》[14] 给一张阿姆斯特丹的风景照加上了星空的感觉。文章提出的基于Gram matrix的方法,也就是神经网络的特征图各个通道的相关性,将真实图片(content)与风格图片(style)融合。这使得合成后的图片具有原始图片的内涵,但是视觉上又会感受到不一样的风格。

图1. 风格迁移实例
当然,这种方案的代价也是巨大的,每一组不同的content到style的转换,都需要训练一个专用的神经网络,这在实际的应用当中显然是不现实的。2017年的另一篇论文《Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization》(AdaIN)[15]则对此问题做出了回应。这篇文章证实了一个至关重要的结论:style信息隐藏在特征层中每一层的统计量中(也就是每一层的均值μ和标准差σ)。故而,文章通过定向改变Instance Normalization(IN)层后特征的均值以及标准差,来获取风格迁移效果。这个方法只要通过训练一次网络,即可以实现任意content至任意style的风格迁移。

图2. 经典的基于AdaIN的风格迁移网络
把人脸当做一种风格
2019年英伟达发表了论文《A Style-Based Generator Architecture for GAN》[16],也就是大名鼎鼎的StyleGAN,这种网络结果生成最高1024*1024分辨率的人脸,且相当的真实与自然,惊艳全场。而这背后的核心,则是通过深层全连接神经网络,将一组随机编码的向量转变成一组均值μ和标准差σ,再送入不同尺度的AdaIN模块,最终生成高清人脸。
StyleGAN的工作给我们带来的不仅是新的网络结构、训练方法,更重要的是思维上的颠覆:“人脸特征也可以作为一种风格来描述”。那么,到底什么是content, 什么是style?
在艺术风格迁移中,content 作为真实照片中的实物形状、轮廓,style则是艺术家画作中的色调、笔触、画风等独特的艺术特点。在StyleGAN中,则没有content,一切的人脸特征皆为style。从这个角度重新审视风格迁移,我们会得出结论:对于content跟style的界定,没有统一的标准,完全取决于你如何划分!应用时,需要保留的部分作为content,而需要改变的部分则作为style。
从风格迁移到换脸
我们再一次回到换脸这个话题,StyleGAN在生成人脸的时候,使用了随机编码的向量作为种子,生成了所需的人脸style,那么我们可否使用类似的思想,抽取目标人脸的style,用来替换源人脸的呢?答案自然是肯定的。
接下来我们将通过四步演化过程来阐述我们的FaceMagic模型:1)化我为我;2)化我为他;3)融于你我;4)止于平衡。
化我为我
算法的第一步自然是确定我们的content,也就是面部姿态与表情等属性信息,这个目标我们通过让模型学会生成自己来达成。整个流程采用了如图3所示的经典Encoder-Decoder结构,网络的输入输出为同一张人脸图像I,通过叠加了多层的ResBlock结构的Encoder,获取特征图F。实践上我们采取了较大的d值来保存更多的content信息。

图3. 通过自编码器来获取人脸的content信息
化我为他
当模型确定了源人脸中的content信息,我们下一步的目标便是将目标人脸的ID信息,以style的形式注入至content当中。这个目标可以进一步拆解为目标人脸的ID提取以及注入两步。ID提取部分,我们借用了使用VGG-Face[17]数据集预训练的人脸识别网络ID-Net。通过ID-Net提取的特征向量G能够很好地区分人脸之间的相似程度,因此可以很紧致地表征一个人的身份特征,同时不会引入其他干扰信息。而在至关重要的信息注入部分,我们的基本思路,则是首先通过全连接层,将目标人脸的G_Tar转化为所需的均值与方差μ_Tar,σ_Tar,再依照AdaIN的方式将style注入content。
然而在实际操作中,我们注意到了以下两个问题:I)训练网络时的收敛速度很慢;II)容易产生人工造成的不自然缺陷(artifacts)。这两个问题让我们重新反思换脸问题的本质:目标人脸的ID固然可以按照style的思路注入源人脸的content中,但是这种方案很类似于传统的2D/3D视觉中的“贴脸”策略——完全采用目标人脸的ID信息而抛弃源人脸的;而要达成“换脸”,我们实际上只需要关注一个从目标人脸的ID到源人脸ID信息的变化。
于是,我们重新定义了要注入进AdaIN的style为“信息增量”,如下式所示:
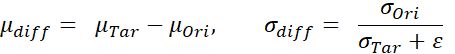
其中ε是一个较小的量以稳定数值。依照这个思路,我们设计了基于AdaIN-ResBlock的风格融合模块Style Mix Block,在多个空间尺度上将ID的信息增量通过AdaIN注入至从源人脸中抽取的content当中。我们另外也采用了一种基于信息增量的训练模式:通过混入一部分源与目标人脸为同一张图片的训练数据,使注入的style信息恒定为μ_diff =0,σ_diff = 1。这个方案极大地提高了模型在学习重构损失时的收敛速度,并且抑制了大部分因为“贴脸重构”导致的artifacts。图4为Style Mix Block的详细结构。
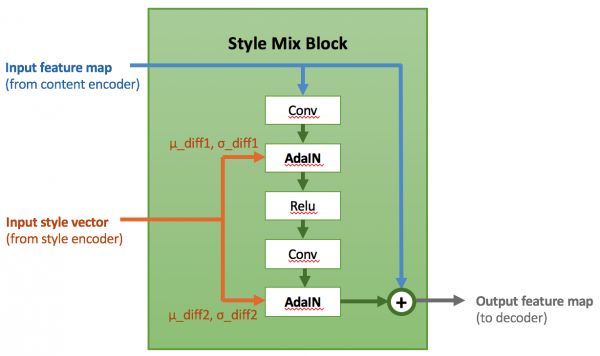
图4. Details of Style Mix Block
然而到这里,BIGO算法团队对目标人脸的ID注入方案的思考,依旧没有结束。真实场景中的换脸,原人脸以及目标人脸肯定不会像证件照一样整洁标准,而经常会涉及到大尺度上的pose转换或者被帽子眼镜遮挡的情况。在这种情况下,信息增量本身存在一个不准确的问题,这就会导致一个在实际效果中依旧存在“换脸的结果并不像目标人脸”的情况。在经过激烈的讨论之后,我们做了一个大胆的决定:将原始用来描述ID信息的特征G,直接拼接(Concatenate)到Style Mix Block的特征上,并将这个整体特征送入Decoder来生成最终结果。整体网络构架如图5所示。
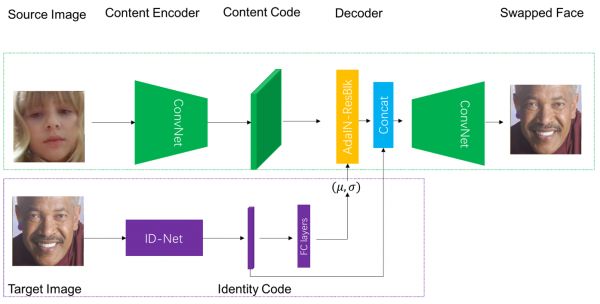
图5. FaceMagic换脸的核心结构
融于你我
故事讲到这里,却依旧只是个开头,接下来一个问题出来哪里呢?
这就牵扯到对抗生成网络的一些本质了,我们常说,对抗生成网络实质上是学习了真实样本的特征流形,在生成的时候通过选取一组作为种子的随机变量,选取流形上的点并映射到图像空间上。这就导致了,我们虽然可以保证一张生成的图像“真实且自然”,但是却难以保证在一连串的视频帧上的连续性。例如,在大尺度上的pose转换的场景下,很容易出现提供content的源人脸的pose信息“丢失”的情况;另外源人脸的ID信息在视频中本身也会存在扰动,而这些扰动由会被注入操作进一步放大。这些情况都导致了在对视频进行按帧换脸的操作时,会产生姿态摆动或者肤色光照抖动等不连续的情况。
这里我们通过Pose Constraint以及Skipping connection来缓解视频换脸中存在的连续性问题,如图6红色部分所示:
1)Pose Constraint:我们通过脸部的landmark来强约束源人脸以及生成人脸之间pose差异的问题。这样即便源人脸在某些帧出现大尺度的pose转换,生成的也依旧会被约束在源人脸的pose上。
2)Skipping Connection:为了让生成的图片能够稳定的保留源图片的特征,我们尝试将一些Encoder的低层次的特征直接通过Skipping Connection直接植入到Decoder的特征当中。

图6. FaceMagic换脸的最终系统结构
止于平衡
我们先做一个小总结,目前我们有了很多的模块,我们的total loss可以写成下面的形式:
很显然,加大L_recon和L_pose的权重,可以使得生成的人脸能更多地保留源人脸的特征,加大L_ID的权重,则会更多地迁移更多目标的身份特征,L_GAN的权重则用于保证生成的人脸尽可能的真实自然。那么,终于,我们可以开始愉快地去调参数了?
显然,终极的平衡不是调参就可以获得的。BIGO的算法同学在深挖了L_ID后发现:对于两个本来长得就有点像的人,换脸后的结果从视觉上几乎看不出变化,原因在于他们的ID特征距离本来就小,如果仅仅使用简单的l2损失或者cos相似度的话,网络对这部分的惩罚会很小,但是简单的加大L_ID的权值又会使整个网络的训练变得艰难。为了解决这个问题,我们提出了衡量换脸效果的相对ID距离。简单来说,就是对比源人脸在换脸前后与目标人脸的距离差异。用公式可以表达为:

其中,为l2损失或者cos相似度。式子的前半部分为原始的ID信息损失,后半部分为对比损失。
结语
经过BIGO算法团队同学们的不断努力,我们攻克了各种技术上的难关,成果实现了FaceMagic——实时且高度真实自然的视频换脸工具。但是我们绝对不会在这里停下休息,追求理想与技术的我们会一直前进。

图7:效果展示,从左往右分别为:源人脸,目标人脸,生成人脸
参考文献
1. Volker Blanz, Kristina Scherbaum, Thomas Vetter, and Hans-Peter Seidel. Exchanging faces in images. In Computer Graphics Forum, volume 23, pages 669–676. Wiley Online Library, 2004. 1, 2, 3
2. Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Advances in neural information processing systems (NPIS), pages 2672–2680, 2014.
3. Dmitri Bitouk, Neeraj Kumar, Samreen Dhillon, Peter Belhumeur, and Shree K Nayar. Face swapping: automatically replacing faces in photographs. ACM Trans. on Graphics (TOG), 27(3):39, 2008.
4. Justus Thies, Michael Zollhofer, Marc Stamminger, Chris- tian Theobalt, and Matthias Nießner. Face2face: Real-time face capture and reenactment of rgb videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2387–2395, 2016.
5. Volker Blanz, Sami Romdhani, and Thomas Vetter. Face identification across different poses and illuminations with a 3d morphable model. In Int. Conf. on Automatic Face and Gesture Recognition (FG), pages 192–197, 2002.
6.Supasorn Suwajanakorn, Steven M Seitz, and Ira Kemelmacher-Shlizerman. Synthesizing obama: learning lip sync from audio. ACM Transactions on Graphics (TOG), 36(4):95, 2017.
7. Yuval Nirkin, Iacopo Masi, Anh Tran Tuan, Tal Hassner, and Gerard Medioni. On face segmentation, face swapping, and face perception. In Automatic Face & Gesture Recognition (FG), 2018 13th IEEE International Conference on, pages 98–105. IEEE, 2018.
8. Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Andrew Tao, Jan Kautz, and Bryan Catanzaro. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
9. Albert Pumarola, Antonio Agudo, Aleix M Martinez, Al- berto Sanfeliu, and Francesc Moreno-Noguer. Ganimation: Anatomically-aware facial animation from a single image. In Proceedings of the European Conference on Computer Vision (ECCV), pages 818–833, 2018.
10. Enrique Sanchez and Michel Valstar. Triple consistency loss for pairing distributions in gan-based face synthesis. arXiv preprint arXiv:1811.03492, 2018.
11. Hyeongwoo Kim, Pablo Carrido, Ayush Tewari, Weipeng Xu, Justus Thies, Matthias Niessner, Patrick Pe ́rez, Chris- tian Richardt, Michael Zollho ̈fer, and Christian Theobalt. Deep video portraits. ACM Transactions on Graphics (TOG), 37(4):163, 2018.
12. Ryota Natsume, Tatsuya Yatagawa, and Shigeo Morishima. Rsgan: face swapping and editing using face and hair representation in latent spaces. arXiv preprint arXiv:1804.03447, 2018.
13. Nirkin Y, Keller Y, Hassner T. Fsgan: Subject agnostic face swapping and reenactment. In Proceedings of the IEEE International Conference on Computer Vision (ICCV). 2019: 7184-7193.
14. Gatys L A, Ecker A S, Bethge M. Image style transfer using convolutional neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR). 2016: 2414-2423.
15. Huang X, Belongie S. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV). 2017: 1501-1510.
16. Karras T, Laine S, Aila T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2019: 4401-4410.
17. Parkhi O M, Vedaldi A, Zisserman A. Deep face recognition[J]. 2015.
网址: 换脸新潮流:BIGO风靡全球的人脸风格迁移技术 http://www.xishuta.com/newsview23178.html
推荐科技快讯






- 1问界商标转让释放信号:赛力斯 95070
- 2人类唯一的出路:变成人工智能 20198
- 3报告:抖音海外版下载量突破1 20006
- 4移动办公如何高效?谷歌研究了 19422
- 5人类唯一的出路: 变成人工智 19310
- 62023年起,银行存取款迎来 10232
- 7网传比亚迪一员工泄露华为机密 8350
- 8五一来了,大数据杀熟又想来, 7752
- 9滴滴出行被投诉价格操纵,网约 7374
- 10顶风作案?金山WPS被指套娃 7161



